MySQL索引解析(联合索引/最左前缀/覆盖索引/索引下推)
本节内容:
1)索引基础
2)索引类型(Hash索引、有序数组、B+树)
3)索引的几个常见问题
1)联合索引
2)最左前缀原则
3)覆盖索引
4)索引下推
1. 索引基础
索引对查询的速度有着至关重要的影响,理解索引也是进行数据库性能调优的起点,索引就是为了提高数据查询的效率。索引可以包含一个或多个列的值,如果索引包含多个列的值,则列的顺序也十分重要,因为MySQL只能高效地使用索引的最左前缀列。
2. 索引类型
用于提高读写效率的数据结构有很多,这里先介绍常见的3种,分别是:
- 哈希表
- 有序数组
- 搜索树(重点)
2.1 哈希索引
哈希表是一种以键-值(key-value)的方式存储数据的结构,我们只要输入待查找的值(即key),就可以找到其对应的值(即Value)。哈希的思路很简单,把值放在数组里,用一个哈希函数把key换算成一个确定的位置,然后把value放在数组的这个位置,即idx = Hash(key)。如果出现哈希冲突,就采用拉链法解决。
因为哈希表中存放的数据不是有序的,因此不适合做区间查询,适用于只有等值查询的场景。
2.2 有序数组
有序数组在等值查询和范围查询场景中的性能都非常优秀。用二分法就可以快速找到(时间复杂度为O(logN))。但是如果要往中间插入一条数据,则必须挪动后面的所有记录,成本较高。因此,有序数组只适用于静态存储引擎,即数据表一旦建立后不再会修改。
2.3 B+树索引(InnoDB)
首先,得先好好理解什么是B+树!看单独介绍B树、B+树的文章,基于篇幅不在此赘述。简单的说,是因为使用B+树存储数据可以让一个查询尽量少的读磁盘,从而减少查询时磁盘I/O的时间。
在 InnoDB 中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。又因为前面我们提到的,InnoDB 使用了 B+ 树索引模型,所以数据都是存储在 B+ 树中的。每一个索引在 InnoDB 里面对应一棵 B+ 树。
假设,有这样一张表:该表主键为ID,且还有一个字段为k,并在k上有索引。
CREATE TABLE T(
id int primary key,
k int not null,
index (k)
)engine=InnoDB;
表中有5条记录,分别为R1~R5,(100,1)、(200,2)、(300,3)、(500,5)和(600,6)。则在InnoDB中的索引组织结构是这样的:
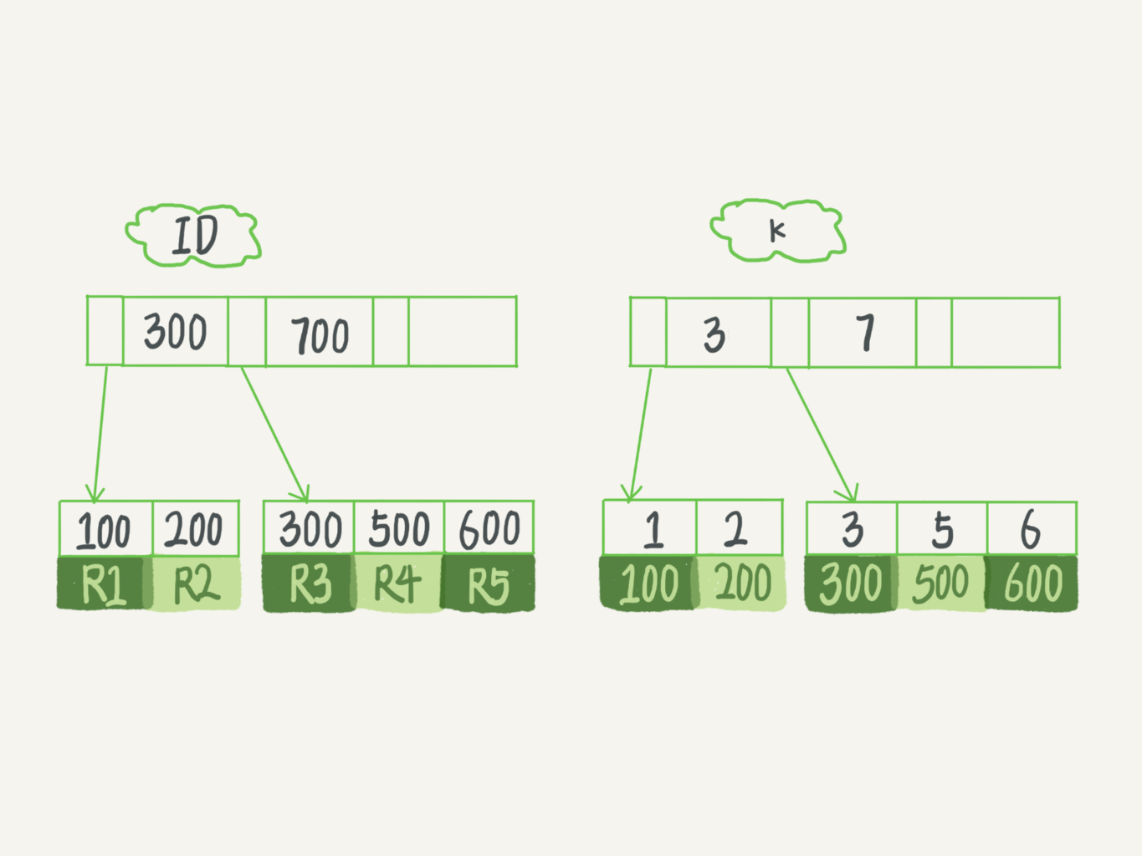
根据叶子结点的内容,索引类型分为主键索引和非主键索引。
- 主键索引的叶子结点存的是整条记录,主键索引也被称为聚簇索引(clustered index)。
- 非主键索引的叶子结点存的是主键的值,非主键索引也被称为二级索引(secondary index)/普通索引/辅助索引。
那么,基于主键索引和非主键索引的查询有什么区别?
- 如果语句是 select * from T where ID=500,即主键查询,则只需要搜索ID这棵树。
- 如果语句是 select * from T where k=5,即非主键索引查询,则需要先搜索k索引树,得到ID的值为500,再到ID索引树搜索一次。从非主键索引回到主键索引的过程称为回表。
也就是说,基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。而从存储空间的角度讲,因为非主键索引树的叶结点存放的是主键的值,那么,应该考虑让主键的字段尽量短,这样非主键索引的叶子结点就越小,非主键索引占用的空间也就越小。一般情况下,建议创建一个自增主键,这样非主键索引占用的空间最小。
3. 联合索引
联合索引是指对表上的多个列进行索引。下面以一个例子进行说明。假设有下面这样一张表,有这样一个需求,我们需要查询某个用户的购物情况,并按照时间进行排序,取出某用户近几次的购物情况。(注:例子来源于《MySQL技术内幕》)
// 表
CREATE TABLE buylog(
userid int not null,
buy_date DATE
)ENGINE=InnoDB;
// 插入数据
insert into buylog values(1, '2019-08-13');
insert into buylog values(2, '2019-08-14');
insert into buylog values(3, '2019-08-15');
insert into buylog values(1, '2019-08-11');
insert into buylog values(3, '2019-08-10');
insert into buylog values(1, '2019-08-12');
// 添加索引
alter table buylog add index(userid);
alter table buylog add index(userid, buy_date);
// (或用key关键字也一样的)
alter table buylog add key(userid);
alter table buylog add key(userid, buy_date);
上面的代码建立了两个索引,两个索引都包含了userid字段。
如果只对于userid进行查询,如:
select * from buylog where userid=2;
通过explain查看该语句的执行情况,如下,(explain的用法,简单了解)

可以看到,possible_keys在这里有两个索引可供使用,分别是userid索引和(userid,buy_date)联合索引。优化器最终选择的索引(即key)是userid,因为该索引的叶子节点只包含单个键值,所以理论上一页能存放的记录会更多(意味着可以减少查询的次数)。
接着假定要查询userid为1的最近两次的购买记录,如:
select * from buylog where userid=1 order by buy_date desc limit 2;
同样的,我们看一下它的执行过程是怎样的,如下:

可以看到,这一次查询优化器选择的索引是userid_2(也就是(userid, buy_date)联合索引)。为什么呢?因为在这个联合索引中,记录已经分别根据userid和buy_date排好序了,利用这个索引则可以直接取出相应的数据而无需再对buy_date额外做一次排序操作了。如果强制使用userid索引,则它的执行计划如下:

从Extra字段可以看出,该语句的执行需要使用fliesort,也就是需要一次额外的排序操作才能完成查询。显然,这个排序就是对buy_date字段的排序,因为这里仅使用了userid索引,该索引未对buy_date进行排序。
总结:
联合索引(a, b)是根据a, b进行排序(先根据a排序,如果a相同则根据b排序)。因此,下列语句可以直接使用联合索引得到结果(事实上,也就是用到了最左前缀原则):
select ... from xxx where a=xxx;
select ... from xxx where a=xxx order by b;
而下列语句则不能使用联合查询:
select ... from xxx where b=xxx;
对于联合索引(a, b, c),下列语句同样可以直接通过联合索引得到结果:
select ... from xxx where a=xxx order by b;
select ... from xxx where a=xxx and b=xxx order by c;
而下列语句则不行,需要执行一次filesort排序操作。
select ... from xxx where a=xxx order by c;
4. 最左前缀原则
对于有很多字段的一张表,查询的方式是多样的,难道要为了每一种可能的查询都定义索引吗?这样岂不是很浪费空间,毕竟建索引也是需要一些空间的。事实上,B+ 树这种索引结构,可以利用索引的“最左前缀”原则来定位记录,避免重复定义索引。
以下面的例子进行说明什么是“最左前缀原则”。
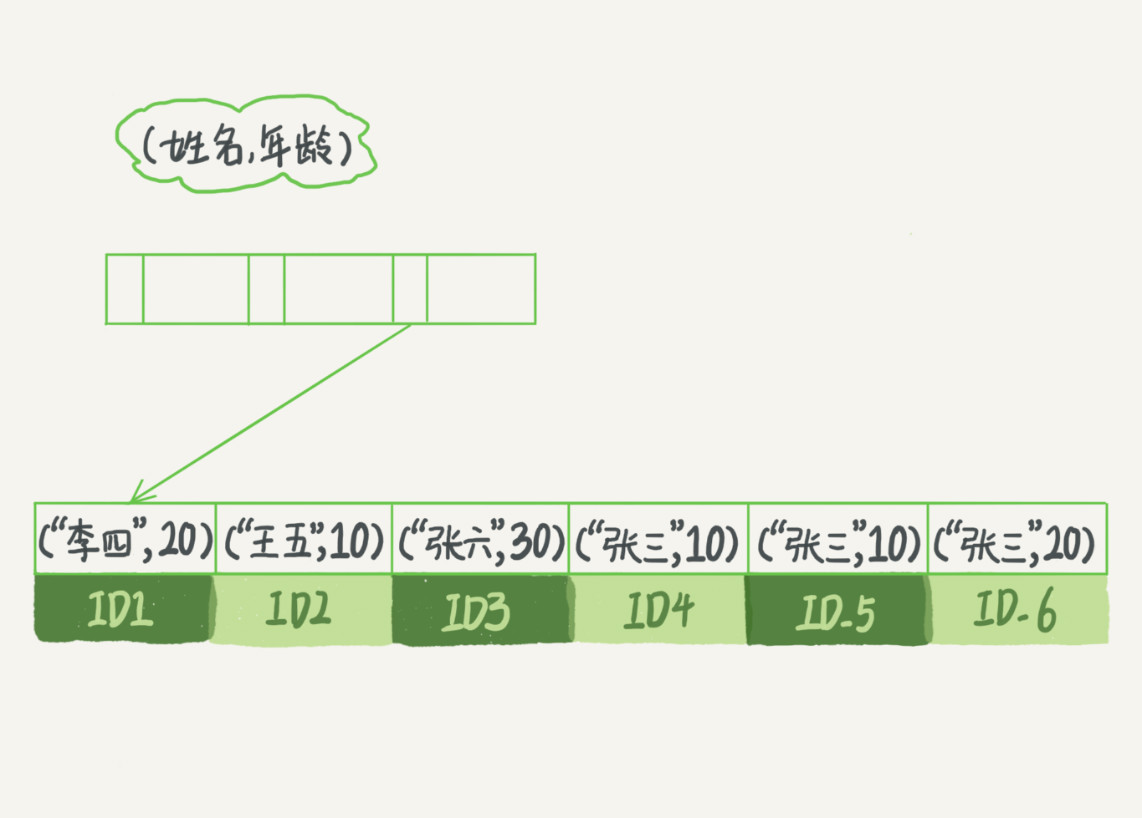
假设建立了一个联合索引(name,age),可以看到,索引项是按照索引定义里面出现的字段顺序排序的,先根据名字排序,名字相同的就根据年龄排序。
当你的逻辑需求是查到所有名字是“张三”的人时,可以快速定位到 ID4,然后向后遍历得到所有需要的结果。
如果你要查的是所有名字第一个字是“张”的人,你的 SQL 语句的条件是"where name like ‘张%’"。这时,你也能够用上这个索引,查找到第一个符合条件的记录是 ID3,然后向后遍历,直到不满足条件为止。
可以看到,不只是索引的全部定义,只要满足最左前缀,就可以利用索引来加速检索。这个最左前缀可以是联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符。
因此,基于最左前缀原则,我们在定义联合索引的时候,考虑如何安排索引内的字段顺序就至关重要了!评估的标准就是索引的复用能力,比如,当已经有了(a,b)字段的索引,一般就不需要再单独在a上建立索引了。
5. 覆盖索引
还是利用“2.3 B+树索引”提到过的表,如果执行的语句是:
select * from T where k between 3 and 5;
则这条SQL语句的执行流程如下:
- 在 k 索引树上找到 k=3 的记录,取得 ID = 300;
- 再到 ID 索引树查到 ID=300 对应的 R3;
- 在 k 索引树取下一个值 k=5,取得 ID=500;
- 再回到 ID 索引树查到 ID=500 对应的 R4;
- 在 k 索引树取下一个值k=6,不满足条件,循环结束。
在这个过程中,回到主键索引树的过程,称为回表。在这个例子中,由于查询的结果是所有字段,所需要的数据只有主键上才有,所以不得不回表。但如果执行的语句是下面这样的,注意!这里查询的结果只是“ID”(恰好是主键),而不是所有字段了。
select ID from T where k between 3 and 5;
由于查询的值是ID,而ID的值已经在k索引树上了,因此可以直接提供查询结果,不需要回表。也就是说,在这个查询里,索引k已经“覆盖了”我们的查询需求,故称为覆盖索引。
除了上面这种情况,针对某些统计问题时,覆盖索引也能发挥用处。还是以上面的例子,执行如下语句来统计表的记录总数(在此我们假设这张表数据量特别特别大,需要多次磁盘IO):
select count(*) from T;
如果没有对字段k设置索引,那么只能是通过聚簇索引来计算;如果对字段k设置了索引,那么,由于聚簇索引的叶结点存放的是整行记录的所有信息,而辅助索引的叶结点只存放主键,两者相比,对于一页内存,显然辅助索引能够存放的节点更多,意味着辅助索引可以减少IO次数,从而更快的计算出count(*)的值。
验证如下:
没有对字段k设置索引时,优化器会选择聚簇索引进行操作(即key为PRIMARY)。

对字段k设置了索引时,优化器会选择辅助索引进行操作(即key为k)

可见,如果建立了辅助索引,在有些场景下,优化器会自动使用辅助索引从而提升查询效率。
总结:覆盖索引就是从辅助索引中就能直接得到查询结果,而不需要回表到聚簇索引中进行再次查询,所以可以减少搜索次数(不需要从辅助索引树回表到聚簇索引树),或者说减少IO操作(通过辅助索引树可以一次性从磁盘载入更多节点),从而提升性能。
6. 索引下推
什么是索引下推(Index Condition Pushdown,ICP)呢?假设有这么个需求,查询表中“名字第一个字是张,性别男,年龄为10岁的所有记录”。那么,查询语句是这么写的:
mysq> select * from tuser where name like '张 %' and age=10 and ismale=1;
根据前面说的“最左前缀原则”,该语句在搜索索引树的时候,只能匹配到名字第一个字是‘张’的记录(即记录ID3),接下来是怎么处理的呢?当然就是从ID3开始,逐个回表,到主键索引上找出相应的记录,再比对age和ismale这两个字段的值是否符合。
但是!MySQL 5.6引入了索引下推优化,可以在索引遍历过程中,对索引中包含的字段先做判断,过滤掉不符合条件的记录,减少回表字数。
下面图1、图2分别展示这两种情况。
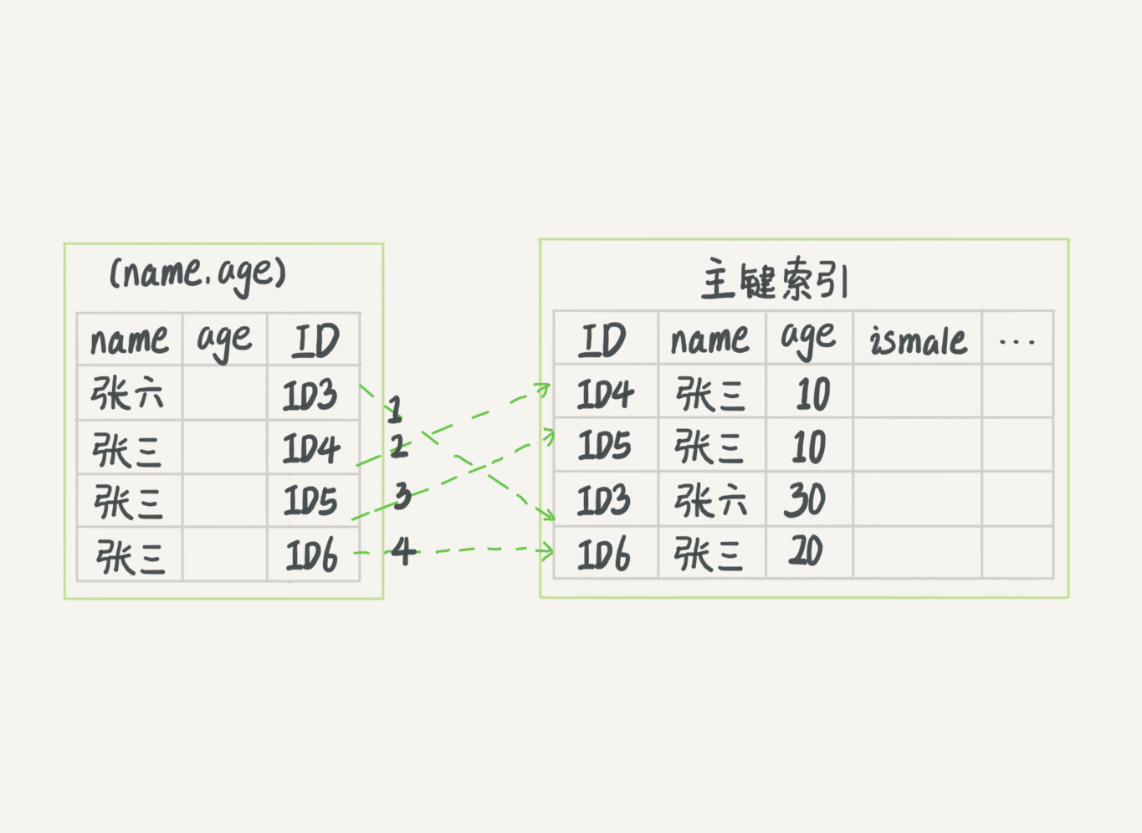
(图1)
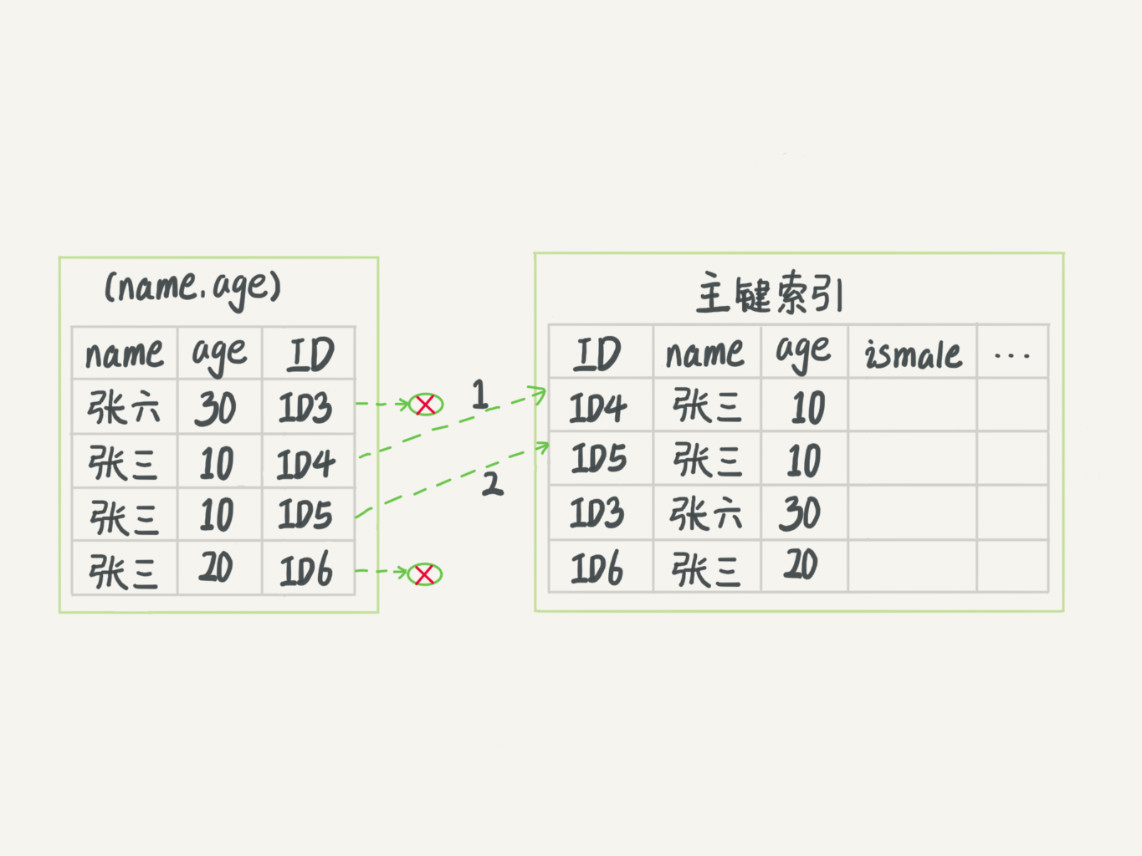
(图2)
图 1 中,在 (name,age) 索引里面我特意去掉了 age 的值,这个过程 InnoDB 并不会去看 age 的值,只是按顺序把“name 第一个字是’张’”的记录一条条取出来回表。因此,需要回表 4 次。
图 2 跟图 1 的区别是,InnoDB 在 (name,age) 索引内部就判断了 age 是否等于 10,对于不等于 10 的记录,直接判断并跳过。在我们的这个例子中,只需要对 ID4、ID5 这两条记录回表取数据判断,就只需要回表 2 次。
总结:如果没有索引下推优化(或称ICP优化),当进行索引查询时,首先根据索引来查找记录,然后再根据where条件来过滤记录;在支持ICP优化后,MySQL会在取出索引的同时,判断是否可以进行where条件过滤,也就是说提前执行where的部分过滤操作,在某些场景下,可以大大减少回表次数,从而提升整体性能。
总结:
学习完本节内容,需要问问自己:
- 索引的常见数据结构有哪些?(哈希表,有序数组,B+树),它们分别有怎样的特点?分别适合哪些应用场景?
- 主键索引(也称聚簇索引)和非主键索引(也称辅助索引/二级索引)的概念是什么?回表的概念又是什么?
- 什么是联合索引,什么是最左前缀原则?(由于MySQL的最左前缀特性,建立联合索引的时候对字段的顺序应该要多考虑)。什么是覆盖索引?能否清楚的说出Index Condition Pushdown优化的原理?
参考:
- 《高性能MySQL》
- 《MySQL技术内幕-InnoDB存储引擎》
- 极客时间“MySQL实战45讲”专栏第4、5讲
MySQL索引解析(联合索引/最左前缀/覆盖索引/索引下推)的更多相关文章
- mysql索引之四:复合索引之最左前缀原理,索引选择性,索引优化策略之前缀索引
高效使用索引的首要条件是知道什么样的查询会使用到索引,这个问题和B+Tree中的“最左前缀原理”有关,下面通过例子说明最左前缀原理. 一.最左前缀索引 这里先说一下联合索引的概念.MySQL中的索引可 ...
- MySQL数据库中的索引(二)——索引的使用,最左前缀原则
上文中,我们了解了MySQL不同引擎下索引的实现原理,在本文我们将继续探讨一下索引的使用以及优化. 创建索引可以大大提高系统的性能. 第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性. ...
- mysql索引之八:myisam压缩(前缀压缩)索引
myisam使用前缀压缩来减少索引的大小,从而让更多的索引可以放入内存中,默认只压缩字符串,但通过参数配置也可以对整数做压缩,myisam压缩每个索引块的方法是,先完全保存索引块中的第一个值,然后将其 ...
- mysql优化-----多列索引的左前缀规则
索引优化策略 :索引类型 .1B-tree索引 关注的是:Btree索引的左前缀匹配规则,索引在排序和分组上发挥的作用. 注:名叫btree索引,大的方面看都用的二叉树.平衡树.但具体的实现上,各引擎 ...
- mysql索引之一:索引基础(B-Tree索引、哈希索引、聚簇索引、全文(Full-text)索引区别)(唯一索引、最左前缀索引、前缀索引、多列索引)
没有索引时mysql是如何查询到数据的 索引对查询的速度有着至关重要的影响,理解索引也是进行数据库性能调优的起点.考虑如下情况,假设数据库中一个表有10^6条记录,DBMS的页面大小为4K,并存储10 ...
- 转:SQL 索引最左前缀原理
表结构和索引列 假设数据库中表是这样的: 我们只考虑一张表employees.titles: 索引是(emp_no,title,from_date) SHOW INDEX FROM employee ...
- mysql数据库从删库到跑路之mysq索引
一 介绍 为何要有索引? 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句 ...
- MySQL之视图、触发器、函数、存储过程、索引
1.视图 把某个查询语句(临时表)设置别名,日后方便使用,视图是虚拟的(不要在数据库里使用视图) #创建: create view v1(视图名称) as SQL #修改: alter view v1 ...
- Mysql的索引调优详解:如何去创建索引以及避免索引失效
在正式介绍Mysql调优之前,先补充mysql的两种引擎 mysql逻辑分层 InnoDB:事务优先(适合高并发操作,行锁) MyISAM:性能优先(表锁) 查看使用的引擎: show variabl ...
随机推荐
- Java8-Lock-No.03
import java.util.HashMap; import java.util.Map; import java.util.concurrent.ExecutorService; import ...
- 用IE滤镜实现多种常用的CSS3效果
CSS3是当下非常火的一个话题之一,很多浏览器都已经开始支持这一特性,然后IE这个拥有庞大用户群体的平台,却无法提供这样的支持,即便是IE9发布,也无法改变这一事实,然而,幸运的是,IE并非在这方面毫 ...
- BZOJ 4008 亚瑟王(概率DP 奥妙重重)
题意 中文题面,就不解释了 分析 显然这道题直接求期望太麻烦,想想转化问题(这转化太神了). 定义f(i,j)f(i,j)f(i,j)表示第iii张卡总共被经过jjj次的概率,有转移方程式 f(i,j ...
- 001_linuxC++之_类的引入
(一) C++类的引入,图片的程序比较好看,文中程序不贴出来 (二) 知识点 1. 成员函数的存取权限:公有的(public),保护的(protectd),私有的(private) 2. 第27行th ...
- bzoj 1924
所用点的编号为输入顺序,因为只有在存在联通门的宫室中存在宝藏.其余点不考虑 对于每一行,选定一个横天门,向该行横天门连双向边,其余门单向边纵列同理自.由门用map判周围八个点是否存在,存在即连边 Ta ...
- bzoj3694
/* * 对于不在最短路树上的边(x, y) * 1 * | * | * t * / \ * / \ * x-----y * 考虑这样一种形态的图, ‘-’ 标记为非最短路树的边 * 对于边集(x, ...
- P1169 [ZJOI2007]棋盘制作——悬线法
---恢复内容开始--- 给你一个矩阵,选出最大的棋盘,棋盘的要求是黑白相间(01不能相邻),求出最大的正方形和矩形棋盘的面积: 数据n,m<=2000; 这个一看就可能是n2DP,但是写不出. ...
- [svn]查看,删除svn账号
1.查看svn账号 ll ~/.subversion/auth/svn.simple 随便打开一个文件 这是保存的对应地址的svn账号和密码,都是明文的 win路径:C:\Users\ysk\AppD ...
- c++ 容器反转
// reverse algorithm example #include <iostream> // std::cout #include <algorithm> // st ...
- Atcoder ABC 139A
Atcoder ABC 139A 题意: 给你两个字符串,记录对应位置字符相同的个数 $ (n=3) $ 解法: 暴力枚举. CODE: #include<iostream> #inclu ...