kafka 讲讲acks参数对消息持久化的影响
目录
(0)写在前面
(1)如何保证宕机时数据不丢失?
(2)多副本冗余的高可用机制
(3)多副本之间数据如何同步?
(4)ISR到底指的什么东西?
(5)acks参数的含义?
(6)最后的思考
(0)写在前面
面试大厂时,一旦简历上写了Kafka,几乎必然会被问到一个问题:说说acks参数对消息持久化的影响?
这个acks参数在kafka的使用中,是非常核心以及关键的一个参数,决定了很多东西。
所以无论是为了面试还是实际项目使用,大家都值得看一下这篇文章对Kafka的acks参数的分析,以及背后的原理。
(1)如何保证宕机的时候数据不丢失?
如果要想理解这个acks参数的含义,首先就得搞明白kafka的高可用架构原理。
比如下面的图里就是表明了对于每一个Topic,我们都可以设置他包含几个Partition,每个Partition负责存储这个Topic一部分的数据。
然后Kafka的Broker集群中,每台机器上都存储了一些Partition,也就存放了Topic的一部分数据,这样就实现了Topic的数据分布式存储在一个Broker集群上。

但是有一个问题,万一 一个Kafka Broker宕机了,此时上面存储的数据不就丢失了吗?
没错,这就是一个比较大的问题了,分布式系统的数据丢失问题,是他首先必须要解决的,一旦说任何一台机器宕机,此时就会导致数据的丢失。
(2)多副本冗余的高可用机制
所以如果大家去分析任何一个分布式系统的原理,比如说zookeeper、kafka、redis cluster、elasticsearch、hdfs,等等,其实他都有自己内部的一套多副本冗余的机制,多副本冗余几乎是现在任何一个优秀的分布式系统都一般要具备的功能。
在kafka集群中,每个Partition都有多个副本,其中一个副本叫做leader,其他的副本叫做follower,如下图。

如上图所示,假设一个Topic拆分为了3个Partition,分别是Partition0,Partiton1,Partition2,此时每个Partition都有2个副本。
比如Partition0有一个副本是Leader,另外一个副本是Follower,Leader和Follower两个副本是分布在不同机器上的。
这样的多副本冗余机制,可以保证任何一台机器挂掉,都不会导致数据彻底丢失,因为起码还是有副本在别的机器上的。
(3)多副本之间数据如何同步?
接着我们就来看看多个副本之间数据是如何同步的?其实任何一个Partition,只有Leader是对外提供读写服务的
也就是说,如果有一个客户端往一个Partition写入数据,此时一般就是写入这个Partition的Leader副本。
然后Leader副本接收到数据之后,Follower副本会不停的给他发送请求尝试去拉取最新的数据,拉取到自己本地后,写入磁盘中。如下图所示:
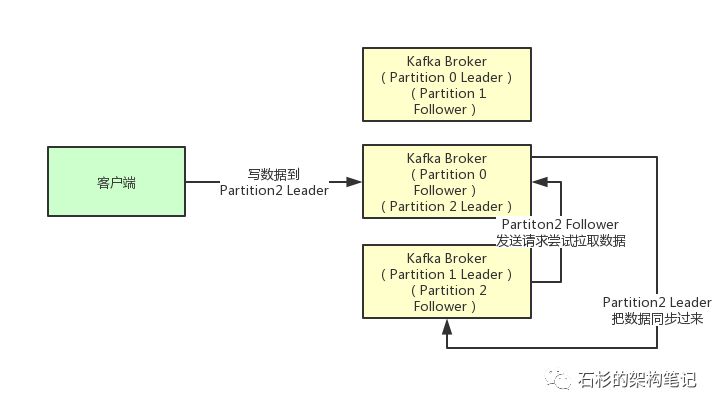
(4)ISR到底指的是什么东西?
既然大家已经知道了Partiton的多副本同步数据的机制了,那么就可以来看看ISR是什么了。
ISR全称是“In-Sync Replicas”,也就是保持同步的副本,他的含义就是,跟Leader始终保持同步的Follower有哪些。
大家可以想一下 ,如果说某个Follower所在的Broker因为JVM FullGC之类的问题,导致自己卡顿了,无法及时从Leader拉取同步数据,那么是不是会导致Follower的数据比Leader要落后很多?
所以这个时候,就意味着Follower已经跟Leader不再处于同步的关系了。但是只要Follower一直及时从Leader同步数据,就可以保证他们是处于同步的关系的。
所以每个Partition都有一个ISR,这个ISR里一定会有Leader自己,因为Leader肯定数据是最新的,然后就是那些跟Leader保持同步的Follower,也会在ISR里。
(5)acks参数的含义
铺垫了那么多的东西,最后终于可以进入主题来聊一下acks参数的含义了。
如果大家没看明白前面的那些副本机制、同步机制、ISR机制,那么就无法充分的理解acks参数的含义,这个参数实际上决定了很多重要的东西。
首先这个acks参数,是在KafkaProducer,也就是生产者客户端里设置的
也就是说,你往kafka写数据的时候,就可以来设置这个acks参数。然后这个参数实际上有三种常见的值可以设置,分别是:0、1 和 all。
第一种选择是把acks参数设置为0,意思就是我的KafkaProducer在客户端,只要把消息发送出去,不管那条数据有没有在哪怕Partition Leader上落到磁盘,我就不管他了,直接就认为这个消息发送成功了。
如果你采用这种设置的话,那么你必须注意的一点是,可能你发送出去的消息还在半路。结果呢,Partition Leader所在Broker就直接挂了,然后结果你的客户端还认为消息发送成功了,此时就会导致这条消息就丢失了。

第二种选择是设置 acks = 1,意思就是说只要Partition Leader接收到消息而且写入本地磁盘了,就认为成功了,不管他其他的Follower有没有同步过去这条消息了。
这种设置其实是kafka默认的设置,大家请注意,划重点!这是默认的设置
也就是说,默认情况下,你要是不管acks这个参数,只要Partition Leader写成功就算成功。
但是这里有一个问题,万一Partition Leader刚刚接收到消息,Follower还没来得及同步过去,结果Leader所在的broker宕机了,此时也会导致这条消息丢失,因为人家客户端已经认为发送成功了。

最后一种情况,就是设置acks=all,这个意思就是说,Partition Leader接收到消息之后,还必须要求ISR列表里跟Leader保持同步的那些Follower都要把消息同步过去,才能认为这条消息是写入成功了。
如果说Partition Leader刚接收到了消息,但是结果Follower没有收到消息,此时Leader宕机了,那么客户端会感知到这个消息没发送成功,他会重试再次发送消息过去。
此时可能Partition 2的Follower变成Leader了,此时ISR列表里只有最新的这个Follower转变成的Leader了,那么只要这个新的Leader接收消息就算成功了。

(6)最后的思考
acks=all 就可以代表数据一定不会丢失了吗?
当然不是,如果你的Partition只有一个副本,也就是一个Leader,任何Follower都没有,你认为acks=all有用吗?
当然没用了,因为ISR里就一个Leader,他接收完消息后宕机,也会导致数据丢失。
所以说,这个acks=all,必须跟ISR列表里至少有2个以上的副本配合使用,起码是有一个Leader和一个Follower才可以。
这样才能保证说写一条数据过去,一定是2个以上的副本都收到了才算是成功,此时任何一个副本宕机,不会导致数据丢失。
所以希望大家把这篇文章好好理解一下,对大家出去面试,或者工作中用kafka都是很好的一个帮助。
kafka 讲讲acks参数对消息持久化的影响的更多相关文章
- 面试官让你讲讲acks参数对消息持久化的影响
(0)写在前面 面试大厂时,一旦简历上写了Kafka,几乎必然会被问到一个问题:说说acks参数对消息持久化的影响? 这个acks参数在kafka的使用中,是非常核心以及关键的一个参数,决定了很多东西 ...
- kafka什么时候会丢消息(转)
因为在具体开发中某些环节考虑使用kafka却担心有消息丢失的风险,本周结合项目对kafka的消息可靠性做了一下调研和总结: 首先明确一下丢消息的定义.kafka集群中的部分或全部broker挂了,导致 ...
- RabbitMQ基本用法、消息分发模式、消息持久化、广播模式
RabbitMQ基本用法 进程queue用于同一父进程创建的子进程间的通信 而RabbitMQ可以在不同父进程间通信(例如在word和QQ间通信) 示例代码 生产端(发送) import pika c ...
- Spring Kafka中关于Kafka的配置参数
#################consumer的配置参数(开始)################# #如果'enable.auto.commit'为true,则消费者偏移自动提交给Kafka的频率 ...
- 深入浅出理解基于 Kafka 和 ZooKeeper 的分布式消息队列
消息队列中间件是分布式系统中重要的组件,主要解决应用耦合,异步消息,流量削锋等问题.实现高性能,高可用,可伸缩和最终一致性架构,是大型分布式系统不可缺少的中间件. 本场 Chat 主要内容: Kafk ...
- Kafka 和 ZooKeeper 的分布式消息队列分析
1. Kafka 总体架构 基于 Kafka-ZooKeeper 的分布式消息队列系统总体架构如下: 如上图所示,一个典型的 Kafka 体系架构包括若干 Producer(消息生产者),若干 bro ...
- Kafka:主要参数详解(转)
原文地址:http://kafka.apache.org/documentation.html ############################# System ############### ...
- RabbitMQ原理与相关操作(三)消息持久化
现在聊一下RabbitMQ消息持久化: 问题及方案描述 1.当有多个消费者同时收取消息,且每个消费者在接收消息的同时,还要处理其它的事情,且会消耗很长的时间.在此过程中可能会出现一些意外,比如消息接收 ...
- EQueue - 详细谈一下消息持久化以及消息堆积的设计
前言 之前写了一篇文章,总体介绍了EQueue.在看这篇文章之前如果还没看过那篇文章,可能会看不懂这篇文章.所以建议没看过的朋友务必先看一下那篇文章中所提到的各种概念,这样才能更好的理解本文所说的内容 ...
随机推荐
- Xcode如何快速定位crash的位置?
最近发现经常有人程序崩掉后不知道怎么定位crash的位置 如何快速定位crash的位置? 选择右箭头 选择Add Exception Breakpoint 这样如果你的app再crash就会自动定位到 ...
- 【转载】Asp.Net MVC网站提交富文本HTML标签内容抛出异常
今天开发一个ASP.NET MVC网站时,有个页面使用到了FCKEditor富文本编辑器,通过Post方式提交内容时候抛出异常,仔细分析后得出应该是服务器阻止了带有HTML标签内容的提交操作,ASP. ...
- node中用的cookie-parser插件设置的max-age,和普通正常设置max-age的计算方式不一样
在cookie-parser中通过max-age设置的cookie的过期时间是按照毫秒计算的; 在普通设置的时候max-age后面的值是按秒计算的;
- 有用的vscode快捷键大全+自定义快捷键
VS Code是前端的一个比较好用的代码编辑器,但是我们不能老是局限于鼠标操作呀,有时候很不方便,所以呢,快捷键大全来啦,有的可能会和你们电脑自带的快捷键冲突呢,这时候,你自己设置一下就好了呀 一.v ...
- English-培训5-How much is it
- 制作win10系统及安装win10系统
制作win10系统 1.登陆msdn,下载win10系统,打开迅雷下载器,复制完该段代码,直接开始下载,网址:https://msdn.itellyou.cn/ 2.下载软碟通,下载网址:https: ...
- cocos creator按钮点击按钮弹起效果设置方法
如图所示: 只要设置下button的Transition的属性为Scale即可,参数自己调整下.
- 《Python编程:从入门到实践》第四章 操作列表 习题答案
#4.1 pizzas = ['KFC','MDL','DKS'] ''' for pizza in pizzas: print(pizza); ''' for pizza in pizzas: pr ...
- Redis未授权漏洞检测工具
Redis未授权检测小工具 #!/usr/bin/python3 # -*- coding: utf-8 -*- """ @Author: r0cky @Time: 20 ...
- jquery基础知识2
1.js和jquery对象的转换 js==>jquery对象 $(js对象) jquery==>js jq对象[index] jq对象.get(index) <!DOCTYPE ht ...