python (2)xpath与定向爬虫
内容来自:极客学院,教学视频;
写在前面:
提取Item
选择器介绍
我们有很多方法从网站中提取数据。Scrapy 使用一种叫做 XPath selectors的机制,它基于 XPath表达式。
这是一些XPath表达式的例子和他们的含义
- /html/head/title: 选择HTML文档<head>元素下面的<title> 标签。
- /html/head/title/text(): 选择前面提到的<title> 元素下面的文本内容
- //td: 选择所有 <td> 元素
- //div[@class="mine"]: 选择所有包含 class="mine" 属性的div 标签元素
这只是几个使用XPath的简单例子,但是实际上XPath非常强大。
为了方便使用XPaths,Scrapy提供XPathSelector 类, 有两种口味可以选择, HtmlXPathSelector
(HTML数据解析) 和XmlXPathSelector (XML数据解析)。 为了使用他们你必须通过一个 Response
对象对他们进行实例化操作。你会发现Selector对象展示了文档的节点结构。因此,第一个实例化的selector必与根节点或者是整个目录有关
。
Selectors 有三种方法
- select():返回selectors列表, 每一个select表示一个xpath参数表达式选择的节点.
- extract():返回一个unicode字符串,该字符串为XPath选择器返回的数据
- re(): 返回unicode字符串列表,字符串作为参数由正则表达式提取出来
一.xpath与定向爬虫
知识点:(话说秒杀 正则表达式啊)
// 定位根节点
/往下层寻找
/text()获取标签中的内容
/@xxxx提取属性的内容
#-*-coding:utf8-*-
from lxml import etree
html = '''
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title>测试-常规用法</title>
</head>
<body>
<div id="content">
<ul id="useful">
<li>这是第一条信息</li>
<li>这是第二条信息</li>
<li>这是第三条信息</li>
</ul>
<ul id="useless">
<li>不需要的信息1</li>
<li>不需要的信息2</li>
<li>不需要的信息3</li>
</ul> <div id="url">
<a href="http://jikexueyuan.com">极客学院</a>
<a href="http://jikexueyuan.com/course/" title="极客学院课程库">点我打开课程库</a>
</div>
</div> </body>
</html>
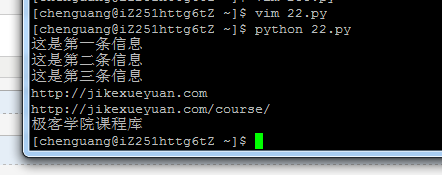
''' selector = etree.HTML(html) #提取文本
content = selector.xpath('//ul[@id="useful"]/li/text()')#提取li标签里的内容
for each in content:
print each #提取属性
link = selector.xpath('//a/@href')#提取标签里面的链接
for each in link:
print each title = selector.xpath('//a/@title')
print title[0]
运行结果:
二. xpath的特殊用法
例如:1. start-with(@属性名称,属性地址相同的部分)
2.string(.)
#-*-coding:utf8-*-
from lxml import etree html1 = '''
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<div id="test-1">需要的内容1</div>
<div id="test-2">需要的内容2</div>
<div id="testfault">需要的内容3</div>
</body>
</html>
''' html2 = '''
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<div id="test3">
我左青龙,
<span id="tiger">
右白虎,
<ul>上朱雀,
<li>下玄武。</li>
</ul>
老牛在当中,
</span>
龙头在胸口。
</div>
</body>
</html>
''' selector = etree.HTML(html1)
content = selector.xpath('//div[starts-with(@id,"test")]/text()')
for each in content:
print each selector = etree.HTML(html2)
content_1 = selector.xpath('//div[@id="test3"]/text()')
for each in content_1:
print each data = selector.xpath('//div[@id="test3"]')[0]
info = data.xpath('string(.)')
content_2 = info.replace('\n','').replace(' ','')
print content_2
运行结果:

三:实战演练 百度贴吧
#-*-coding:utf8-*-
from lxml import etree
from multiprocessing.dummy import Pool as ThreadPool
import requests
import json
import sys reload(sys) sys.setdefaultencoding('utf-8') '''重新运行之前请删除content.txt,因为文件操作使用追加方式,会导致内容太多。''' def towrite(contentdict):
f.writelines(u'回帖时间:' + str(contentdict['topic_reply_time']) + '\n')
f.writelines(u'回帖内容:' + unicode(contentdict['topic_reply_content']) + '\n')
f.writelines(u'回帖人:' + contentdict['user_name'] + '\n\n') def spider(url):
html = requests.get(url)
selector = etree.HTML(html.text)
content_field = selector.xpath('//div[@class="l_post l_post_bright "]')
item = {}
for each in content_field:
reply_info = json.loads(each.xpath('@data-field')[0].replace('"',''))
author = reply_info['author']['user_name']
content = each.xpath('div[@class="d_post_content_main"]/div/cc/div[@class="d_post_content j_d_post_content "]/text()')[0]
reply_time = reply_info['content']['date']
print content
print reply_time
print author
item['user_name'] = author
item['topic_reply_content'] = content
item['topic_reply_time'] = reply_time
towrite(item) if __name__ == '__main__':
pool = ThreadPool(4)
f = open('content.txt','a')
page = []
for i in range(1,21):
newpage = 'http://tieba.baidu.com/p/3522395718?pn=' + str(i)
page.append(newpage) results = pool.map(spider, page)
pool.close()
pool.join()
f.close()
python (2)xpath与定向爬虫的更多相关文章
- Python 中国大学排名定向爬虫
代码来自于中国大学Mooc北京理工大学Pythont教学团队:https://www.icourse163.org/learn/BIT-1001870001#/learn/content?type=d ...
- Python淘宝商品比价定向爬虫
1.项目基本信息 目标: 获取淘宝搜索页面的信息,提取其中的商品名称和价格理解: 淘宝的搜索接口.翻页的处理 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道 ...
- 定向爬虫 - Python模拟新浪微博登录
当我们试图从新浪微博抓取数据时,我们会发现网页上提示未登录,无法查看其他用户的信息. 模拟登录是定向爬虫制作中一个必须克服的问题,只有这样才能爬取到更多的内容. 实现微博登录的方法有很多,一般我们在模 ...
- Python定向爬虫实战
转载请注明原文地址:http://www.cnblogs.com/ygj0930/p/7019963.html 一:requests模块介绍 requests是第三方http库,可以十分方便地实现py ...
- 放养的小爬虫--京东定向爬虫(AJAX获取价格数据)
放养的小爬虫--京东定向爬虫(AJAX获取价格数据) 笔者声明:只用于学习交流,不用于其他途径.源代码已上传github.githu地址:https://github.com/Erma-Wang/Sp ...
- python beautifulsoup/xpath/re详解
自己在看python处理数据的方法,发现一篇介绍比较详细的文章 转自:http://blog.csdn.net/lingojames/article/details/72835972 20170531 ...
- python Cmd实例之网络爬虫应用
python Cmd实例之网络爬虫应用 标签(空格分隔): python Cmd 爬虫 废话少说,直接上代码 # encoding=utf-8 import os import multiproces ...
- 使用python做最简单的爬虫
使用python做最简单的爬虫 --之心 #第一种方法import urllib2 #将urllib2库引用进来response=urllib2.urlopen("http://www.ba ...
- Python之定向爬虫Scrapy
1.Scrapy介绍 Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 ...
随机推荐
- Scala vs. Groovy vs. Clojure
http://stackoverflow.com/questions/1314732/scala-vs-groovy-vs-clojure Groovy is a dynamically typed ...
- 【深入Cocos2d-x】使用MVC架构搭建游戏Four
喜欢Four这个项目,就赶快在GitHub上Star这个项目吧! 喜欢我的文章,来微博关注我吧:王选易在学C艹 点我下载 项目起源 项目Logo: 下面是该游戏的项目地址,各位想参考源代码的同学可以到 ...
- Entity Framework 全面教程详解(转)
目录 预备知识 2 LINQ技术 2 LINQ技术的基础 - C#3.0 2 自动属性 2 隐式类型 2 对象初始化器与集合初始化器 3 匿名类 3 扩展方法 ...
- 怎么给OCR文字识别软件设置正确的扫描分辨率
ABBYY FineReader 12是一款专业的OCR文字识别软件,可快速方便地将扫描纸质文档.PDF文件和数码相机的图像转换成可编辑.可搜索的文本,不仅支持对页扫描,还支持多页扫描,扫描分辨率的选 ...
- Axure轮播图
制作步骤如下: 1.新建一个动态面板,并添加几个动态面板状态(tab) 2.在所建的几个动态面板状态中添加要显示的每个广告的图片和相对应的代表第几个广告的数字. 3.添加页面交互事件.添加事件是在页面 ...
- 002. C#生成GUID
什么是GUID: 全局唯一标识符(GUID,Globally Unique Identifier)是一种由算法生成的二进制长度为128位的数字标识符.该算法使用了太网卡地址, 纳秒级时间,CPU芯片I ...
- 【转】用 PHP 内置函数 file_put_contents 写入文件
PHP 内置函数 file_put_contents 用于写入文件. file_put_contents 函数最简单的写法,可以只用两个参数,一个是文件路径,一个是要写入的内容,语法如下: file_ ...
- Sql2008 全文索引应用(错误7625)
在SQL Server 中提供了一种名为全文索引的技术,可以大大提高从长字符串里搜索数 据的速度,不用在用LIKE这样低效率的模糊查询了. 下面简明的介绍如何使用Sql2008 全文索引 一.检查服务 ...
- C#中的List<string>泛型类示例
在C#代码中使用一系列字符串(strings)并需要为其创建一个列表时,List<string>泛型类是一个用于存储一系列字 符串(strings)的极其优秀的解决办法.下面一起有一些Li ...
- 结合MongoDB开发LBS应用
然后列举一下需求:1.实时性要高,有频繁的更新和读取2.可按距离排序支持分页3.支持多条件筛选(一个经纬度数据还包含其他属性,比如社交系统的性别.年龄) 方案简单介绍:1.sphinx geo索引支持 ...