SQL Server-聚焦INNER JOIN AND IN性能分析(十四)
前言
本节我们来讲讲联接综合知识,我们在大多教程或理论书上都在讲用哪好,哪个性能不如哪个的性能,但是真正讲到问题的实质却不是太多,所以才有了本系列每一篇的篇幅不是太多,但是肯定是我用心去查找许多资料而写出,简短的内容,深入的理解,Always to review the basics。
初次探讨INNER JOIN和IN性能分析
接下来我们看第一篇联接综合知识讲解INNER JOIN和IN的比较分析,我们通过创建表来看INNER JOIN。
创建测试表1
CREATE TABLE Table1 (
id INT IDENTITY PRIMARY KEY,
SomeColumn CHAR(),
Filler CHAR()
)
插入测试数据
Insert into Table1(SomeColumn) Values (),(),(),(),()
创建测试表2并插入数据
USE TSQL2012
GO CREATE TABLE Table2 (IntCol int)
Insert into Table2 (IntCol) Values (),(),(),(),(),(),()
接下来我们对测试表1和测试表2中的SomeColumn和IntCol进行JOIN
USE TSQL2012
GO SELECT *
FROM Table1 b
INNER JOIN Table2 s ON b.SomeColumn = s.IntCol

此时我们看到两个测试表中都返回7行数据,因为在测试表2中有重复的数据都匹配上所有测试表1返回所有数据。此时我们再来看看IN的查询
USE TSQL2012
GO SELECT *
FROM Table1
WHERE SomeColumn IN (Select IntCol FROM Table2)

此时则返回5条数据,从这里我们知道INNER JOIN和IN还是有很大的区别,但是若在测试表2中没有重复的数据,同时在测试表2中没有需要的列,此时则查询出的数据和测试表1是一样的,此时二者在性能上有什么区别呢?接下来我们在创建大量数据的前提下来进行测试看看。
创建两个测试表
CREATE TABLE BigTable (
id INT IDENTITY PRIMARY KEY,
SomeColumn UNIQUEIDENTIFIER NOT NULL,
Filler CHAR()
) CREATE TABLE SmallerTable (
id INT IDENTITY PRIMARY KEY,
LookupColumn UNIQUEIDENTIFIER NOT NULL,
SomeArbDate DATETIME DEFAULT GETDATE()
)
在BigTable表SomeColumn列中插入100万条数据
INSERT INTO BigTable (SomeColumn)
SELECT NEWID()
FROM dbo.Nums
WHERE n<
取出BigTable中的25%数据插入到SmallerTable表LookupColumn列中
USE TSQL2012
GO INSERT INTO SmallerTable (LookupColumn)
SELECT DISTINCT SomeColumn
FROM BigTable TABLESAMPLE ( PERCENT)
这里我们分三种情况来测试。
(1)未建立索引比较INNER和JOIN
SELECT BigTable.ID, SomeColumn
FROM BigTable
WHERE SomeColumn IN (SELECT LookupColumn FROM dbo.SmallerTable) SELECT BigTable.ID, SomeColumn
FROM BigTable
INNER JOIN SmallerTable ON dbo.BigTable.SomeColumn = dbo.SmallerTable.LookupColumn
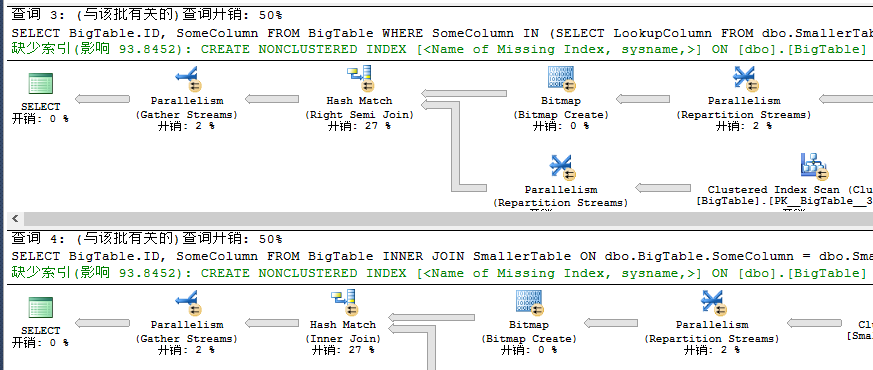

从上看出此时在无论是查询开销还是IO上均没有什么差异,下面我们再来看看建立索引的情况
(2)建立非唯一非聚集索引比较INNER JOIN和IN
CREATE INDEX idx_BigTable_SomeColumn ON BigTable (SomeColumn)
CREATE INDEX idx_SmallerTable_LookupColumn ON SmallerTable (LookupColumn)
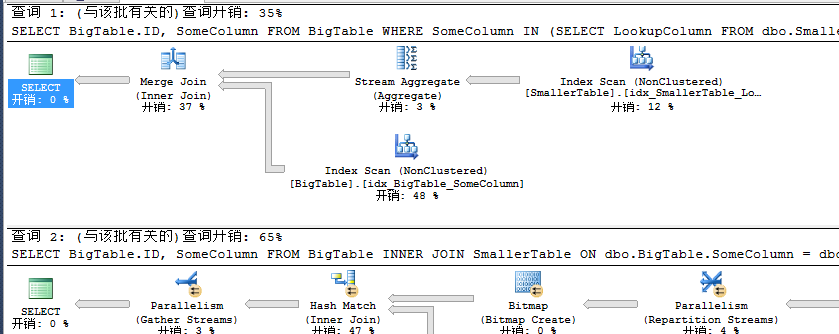

此时我们发现在建立非唯一非聚集索引的情况二者在查询开销上开始有了比较大的差异,INNER JOIN的开销是IN的两倍而IO几乎是等同的。
(3)建立唯一非聚集索引比较INNER JOIN和IN
CREATE UNIQUE INDEX idx_BigTable_SomeColumn ON BigTable (SomeColumn)
CREATE UNIQUE INDEX idx_SmallerTable_LookupColumn ON SmallerTable (LookupColumn)
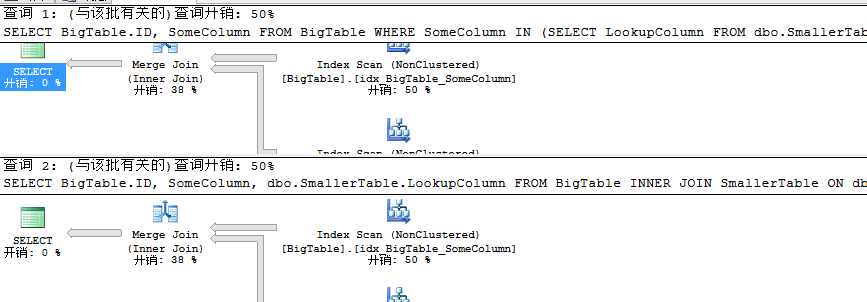
此时为何索引变为唯一聚集索引二者性能开销却一致了呢?有点纳闷,同时到这里为止是不是说明IN的查询性能比JOIN的性能更好呢,完全颠覆我们的想法,在本文前言我们讨论过在教程中都会给出大部分JOIN比EXISTS性能好,而EXISTS比IN性能好,凡是还是动手实践,亲自验证才是王道,我们只能得出一般性结论:一般来说,JOIN比EXISTS性能好,而EXISTS比IN性能好仅此而已。这都是一般性情况,本系列需要讲述的是什么时候应该用EXISTS,什么时候应该用JOIN,还有什么时候应该用IN,后续内容会陆续讨论这些内容。好了,有点跑题了,上述我们通过100万条数据得出IN的性能接近是INNER JOIN性能的两倍,完全出乎你我的意料,带着这个疑问,接下来我们进一步进行探讨。
进一步探讨INNER JOIN和IN性能分析
上述在SmallerTable表从BigTable表中取出的25%的数据都是唯一的,接下来我们将这25%数据的一部分设置为重复的。我们随便从BigTable表中取出SomeColumn这列的数据,然后将SmallerTable表中的LookupColumn这列的数据设置重复的10000条,如下
USE TSQL2012
GO UPDATE dbo.SmallerTable SET LookupColumn = '0067cb6c-64e1-46cc-b7f2-334a7dd812ff'
WHERE id>= AND id<=
此时我们查询包括重复的这10000条
USE TSQL2012
GO SELECT BigTable.ID, SomeColumn
FROM BigTable
WHERE SomeColumn IN (SELECT LookupColumn FROM dbo.SmallerTable) SELECT BigTable.ID, SomeColumn
FROM BigTable
INNER JOIN SmallerTable ON dbo.BigTable.SomeColumn = dbo.SmallerTable.LookupColumn

此时结果还是IN性能比INNER JOIN性能要接近一半,接下来我们在查询SmallerTable表时将重复的LookupColumn列数据去除,此时我们查询变为如下:
USE TSQL2012
GO SELECT BigTable.ID, SomeColumn
FROM BigTable
WHERE SomeColumn IN (SELECT LookupColumn FROM dbo.SmallerTable) SELECT BigTable.ID, SomeColumn
FROM BigTable
INNER JOIN (SELECT DISTINCT LookupColumn FROM dbo.SmallerTable) AS s
ON s.LookupColumn = dbo.BigTable.SomeColumn
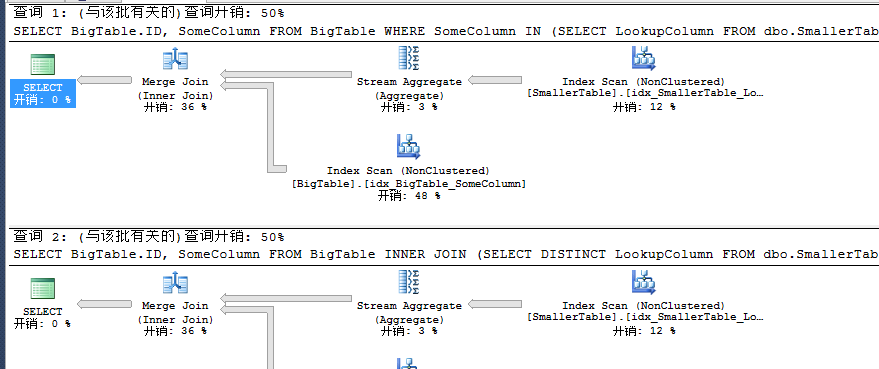
终于查询开销和上述不一样了,此时二者查询性能开销是一致的,相信到了这里我们应该很清楚了。通过上述大量篇幅的贴图和比较我们可以得出INNER JOIN和IN的性能开销使用场景,当我们在初步探讨INNER JOIN和IN的性能分析时,当建立非唯一聚集索引时IN性能接近是INNER JOIN的两倍,而当建立唯一聚集索引时,此时性能开销一致,不免有点纳闷,当我们继续向下探讨时终于明白了这个原因,至此我们最终得出INNER JOIN和IN的性能开销结论。
INNER JOIN和IN性能开销结论:当INNER JOIN表中列数据是唯一的,此时INNER JOIN和IN的性能开销是相同的,当INNER JOIN表中列数据是重复的,此时IN性能要INNER JOIN要好。
总结
本节我们详细叙述了INNER JOIN和IN的性能分析,最终得出一致性结论,下节我们开始讨论NOT EXISTS和NOT IN性能分析,简短的内容,深入的理解,我们下节再会,good night。
SQL Server-聚焦INNER JOIN AND IN性能分析(十四)的更多相关文章
- SQL Server-聚焦NOT IN VS NOT EXISTS VS LEFT JOIN...IS NULL性能分析(十八)
前言 本节我们来综合比较NOT IN VS NOT EXISTS VS LEFT JOIN...IS NULL的性能,简短的内容,深入的理解,Always to review the basics. ...
- SQL Server中INNER JOIN与子查询IN的性能测试
这个月碰到几个人问我关于"SQL SERVER中INNER JOIN 与 IN两种写法的性能孰优孰劣?"这个问题.其实这个概括起来就是SQL Server中INNER JOIN与子 ...
- sql server几种Join的区别测试方法与union表的合并
/* sql server几种Join的区别测试方法 主要来介绍下Inner Join , Full Out Join , Cross Join , Left Join , Right Join的区别 ...
- 对Oracle 、SQL Server、MySQL、PostgreSQL数据库优缺点分析
对Oracle .SQL Server.MySQL.PostgreSQL数据库优缺点分析 Oracle Database Oracle Database,又名Oracle RDBMS,或简称Oracl ...
- SQL Server 2019 中标量用户定义函数性能的改进
在SQL Server中,我们通常使用用户定义的函数来编写SQL查询.UDF接受参数并将结果作为输出返回.我们可以在编程代码中使用这些UDF,并且可以快速编写查询.我们可以独立于任何其他编程代码来修改 ...
- SQL Server中使用Check约束提升性能
在SQL Server中,SQL语句的执行是依赖查询优化器生成的执行计划,而执行计划的好坏直接关乎执行性能. 在查询优化器生成执行计划过程中,需要参考元数据来尽可能生成高效的执行计划, ...
- SQL Server中一个隐性的IO性能杀手-Forwarded record
简介 最近在一个客户那里注意到一个计数器很高(Forwarded Records/Sec),伴随着间歇性的磁盘等待队列的波动.本篇文章分享什么是forwarded record,并从原理上谈一 ...
- SQL Server调优系列基础篇 - 性能调优介绍
前言 关于SQL Server调优系列是一个庞大的内容体系,非一言两语能够分析清楚,本篇先就在SQL 调优中所最常用的查询计划进行解析,力图做好基础的掌握,夯实基本功!而后再谈谈整体的语句调优. 通过 ...
- SQL Server nested loop join 效率试验
从很多网页上都看到,SQL Server有三种Join的算法, nested loop join, merge join, hash join. 其中最常用的就是nested loop join. 在 ...
随机推荐
- 从源码看Azkaban作业流下发过程
上一篇零散地罗列了看源码时记录的一些类的信息,这篇完整介绍一个作业流在Azkaban中的执行过程,希望可以帮助刚刚接手Azkaban相关工作的开发.测试. 一.Azkaban简介 Azkaban作为开 ...
- CoreCRM 开发实录——想用国货不容易
昨天(2016年12月29日)发了开始开发的文章.本来晚上准备在 Coding.NET 上添加几个任务开始搞起了.可是真的开始用的时候才发现:Coding.NET 的任务功能只针对私有的任务开放.我想 ...
- nginx源码分析之网络初始化
nginx作为一个高性能的HTTP服务器,网络的处理是其核心,了解网络的初始化有助于加深对nginx网络处理的了解,本文主要通过nginx的源代码来分析其网络初始化. 从配置文件中读取初始化信息 与网 ...
- 手把手教你写一个RN小程序!
时间过得真快,眨眼已经快3年了! 1.我的第一个App 还记得我14年初写的第一个iOS小程序,当时是给别人写的一个单机的相册,也是我开发的第一个完整的app,虽然功能挺少,但是耐不住心中的激动啊,现 ...
- 基于注解的bean配置
基于注解的bean配置,主要是进行applicationContext.xml配置.DAO层类注解.Service层类注解. 1.在applicationContext.xml文件中配置信息如下 &l ...
- javascript高性能编程-算法和流程控制
代码整体结构是执行速度的决定因素之一. 代码量少不一定运行速度快, 代码量多也不一定运行速度慢. 性能损失与代码组织方式和具体问题解决办法直接相关. 倒序循环可以提高性能,如: ...
- iOS开源项目周报1222
由OpenDigg 出品的iOS开源项目周报第二期来啦.我们的iOS开源周报集合了OpenDigg一周来新收录的优质的iOS开发方面的开源项目,方便iOS开发人员便捷的找到自己需要的项目工具等. io ...
- PLSql Oracle配置
1.安装Oracle客户端或者服务端 2.配置环境变量 <1>.一般如果安装了Oracle客户端或者服务端的话,在环境变种的Path中有Oracle的安装路径(计算机-属性-高级系统设置- ...
- mono3.2和monodevelop4.0在ubuntu12.04上两天的苦战
首先第一步是设置ubuntu server 12.04版更新源,推荐中科大的比较快:deb http://debian.ustc.edu.cn/ubuntu/ precise main multive ...
- ABP理论之时间
返回总目录 本篇目录 介绍 Clock 时区 绑定器和转换器 介绍 虽然有些应用针对的是一个特定的时区,但是也有一些应用针对多个不同的时区.为了满足这些需求,ABP为datetime操作提供了通用的基 ...