java从零到变身爬虫大神(一)
学习java3天有余,知道一些基本语法后
学习java爬虫,1天后开始出现明显效果
刚开始先从最简单的爬虫逻辑入手
爬虫最简单的解析面真的是这样
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException; public class Test {
public static void Get_Url(String url) {
try {
Document doc = Jsoup.connect(url)
//.data("query", "Java")
//.userAgent("头部")
//.cookie("auth", "token")
//.timeout(3000)
//.post()
.get();
} catch (IOException e) {
e.printStackTrace();
}
}
}
这只是一个函数而已
那么在下面加上:
//main函数
public static void main(String[] args) {
String url = "...";
Get_Url(url);
}
哈哈,搞定
就是这么一个爬虫了
太神奇
但是得到的只是网页的html页面的东西
而且还没筛选
那么就筛选吧
public static void Get_Url(String url) {
try {
Document doc = Jsoup.connect(url)
//.data("query", "Java")
//.userAgent("头部")
//.cookie("auth", "token")
//.timeout(3000)
//.post()
.get();
//得到html的所有东西
Element content = doc.getElementById("content");
//分离出html下<a>...</a>之间的所有东西
Elements links = content.getElementsByTag("a");
//Elements links = doc.select("a[href]");
// 扩展名为.png的图片
Elements pngs = doc.select("img[src$=.png]");
// class等于masthead的div标签
Element masthead = doc.select("div.masthead").first();
for (Element link : links) {
//得到<a>...</a>里面的网址
String linkHref = link.attr("href");
//得到<a>...</a>里面的汉字
String linkText = link.text();
System.out.println(linkText);
}
} catch (IOException e) {
e.printStackTrace();
}
}
那就用上面的来解析一下我的博客园
解析的是<a>...</a>之间的东西

看起来很不错,就是不错
-------------------------------我是快乐的分割线-------------------------------
其实还有另外一种爬虫的方法更加好
他能批量爬取网页保存到本地
先保存在本地再去正则什么的筛选自己想要的东西
这样效率比上面的那个高了很多
很多
很多
看代码!
//将抓取的网页变成html文件,保存在本地
public static void Save_Html(String url) {
try {
File dest = new File("src/temp_html/" + "保存的html的名字.html");
//接收字节输入流
InputStream is;
//字节输出流
FileOutputStream fos = new FileOutputStream(dest); URL temp = new URL(url);
is = temp.openStream(); //为字节输入流加缓冲
BufferedInputStream bis = new BufferedInputStream(is);
//为字节输出流加缓冲
BufferedOutputStream bos = new BufferedOutputStream(fos); int length; byte[] bytes = new byte[1024*20];
while((length = bis.read(bytes, 0, bytes.length)) != -1){
fos.write(bytes, 0, length);
} bos.close();
fos.close();
bis.close();
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
这个方法直接将html保存在了文件夹src/temp_html/里面
在批量抓取网页的时候
都是先抓下来,保存为html或者json
然后在正则什么的进数据库
东西在本地了,自己想怎么搞就怎么搞
反爬虫关我什么事
上面两个方法都会造成一个问题
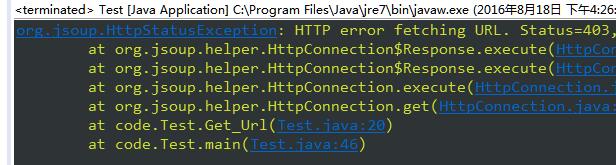
这个错误代表
这种爬虫方法太low逼
大部分网页都禁止了
所以,要加个头
就是UA
方法一那里的头部那里直接
.userAgent("Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; MALC)")
方法二间接加:
URL temp = new URL(url);
URLConnection uc = temp.openConnection();
uc.addRequestProperty("User-Agent", "Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5");
is = temp.openStream();
加了头部,几乎可以应付大部分网址了
-------------------------------我是快乐的分割线-------------------------------
将html下载到本地后需要解析啊
解析啊看这里啊
//解析本地的html
public static void Get_Localhtml(String path) { //读取本地html的路径
File file = new File(path);
//生成一个数组用来存储这些路径下的文件名
File[] array = file.listFiles();
//写个循环读取这些文件的名字 for(int i=0;i<array.length;i++){
try{
if(array[i].isFile()){
//文件名字
System.out.println("正在解析网址:" + array[i].getName()); //下面开始解析本地的html
Document doc = Jsoup.parse(array[i], "UTF-8");
//得到html的所有东西
Element content = doc.getElementById("content");
//分离出html下<a>...</a>之间的所有东西
Elements links = content.getElementsByTag("a");
//Elements links = doc.select("a[href]");
// 扩展名为.png的图片
Elements pngs = doc.select("img[src$=.png]");
// class等于masthead的div标签
Element masthead = doc.select("div.masthead").first(); for (Element link : links) {
//得到<a>...</a>里面的网址
String linkHref = link.attr("href");
//得到<a>...</a>里面的汉字
String linkText = link.text();
System.out.println(linkText);
}
}
}catch (Exception e) {
System.out.println("网址:" + array[i].getName() + "解析出错");
e.printStackTrace();
continue;
}
}
}
文字配的很漂亮
就这样解析出来啦
主函数加上
//main函数
public static void main(String[] args) {
String url = "http://www.cnblogs.com/TTyb/";
String path = "src/temp_html/";
Get_Localhtml(path);
}
那么这个文件夹里面的所有的html都要被我解析掉
好啦
3天java1天爬虫的结果就是这样子咯
-------------------------------我是快乐的分割线-------------------------------
其实对于这两种爬取html的方法来说,最好结合在一起
作者测试过
方法二稳定性不足
方法一速度不好
所以自己改正
将方法一放到方法二的catch里面去
当方法二出现错误的时候就会用到方法一
但是当方法一也错误的时候就跳过吧
结合如下:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements; import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;
import java.util.Date;
import java.text.SimpleDateFormat; public class JavaSpider { //将抓取的网页变成html文件,保存在本地
public static void Save_Html(String url) {
try {
File dest = new File("src/temp_html/" + "我是名字.html");
//接收字节输入流
InputStream is;
//字节输出流
FileOutputStream fos = new FileOutputStream(dest); URL temp = new URL(url);
URLConnection uc = temp.openConnection();
uc.addRequestProperty("User-Agent", "Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5");
is = temp.openStream(); //为字节输入流加缓冲
BufferedInputStream bis = new BufferedInputStream(is);
//为字节输出流加缓冲
BufferedOutputStream bos = new BufferedOutputStream(fos); int length; byte[] bytes = new byte[1024*20];
while((length = bis.read(bytes, 0, bytes.length)) != -1){
fos.write(bytes, 0, length);
} bos.close();
fos.close();
bis.close();
is.close();
} catch (IOException e) {
e.printStackTrace();
System.out.println("openStream流错误,跳转get流");
//如果上面的那种方法解析错误
//那么就用下面这一种方法解析
try{
Document doc = Jsoup.connect(url)
.userAgent("Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; MALC)")
.timeout(3000)
.get(); File dest = new File("src/temp_html/" + "我是名字.html");
if(!dest.exists())
dest.createNewFile();
FileOutputStream out=new FileOutputStream(dest,false);
out.write(doc.toString().getBytes("utf-8"));
out.close(); }catch (IOException E) {
E.printStackTrace();
System.out.println("get流错误,请检查网址是否正确");
} }
} //解析本地的html
public static void Get_Localhtml(String path) { //读取本地html的路径
File file = new File(path);
//生成一个数组用来存储这些路径下的文件名
File[] array = file.listFiles();
//写个循环读取这些文件的名字 for(int i=0;i<array.length;i++){
try{
if(array[i].isFile()){
//文件名字
System.out.println("正在解析网址:" + array[i].getName());
//文件地址加文件名字
//System.out.println("#####" + array[i]);
//一样的文件地址加文件名字
//System.out.println("*****" + array[i].getPath()); //下面开始解析本地的html
Document doc = Jsoup.parse(array[i], "UTF-8");
//得到html的所有东西
Element content = doc.getElementById("content");
//分离出html下<a>...</a>之间的所有东西
Elements links = content.getElementsByTag("a");
//Elements links = doc.select("a[href]");
// 扩展名为.png的图片
Elements pngs = doc.select("img[src$=.png]");
// class等于masthead的div标签
Element masthead = doc.select("div.masthead").first(); for (Element link : links) {
//得到<a>...</a>里面的网址
String linkHref = link.attr("href");
//得到<a>...</a>里面的汉字
String linkText = link.text();
System.out.println(linkText);
}
}
}catch (Exception e) {
System.out.println("网址:" + array[i].getName() + "解析出错");
e.printStackTrace();
continue;
}
}
}
//main函数
public static void main(String[] args) {
String url = "http://www.cnblogs.com/TTyb/";
String path = "src/temp_html/";
//保存到本地的网页地址
Save_Html(url);
//解析本地的网页地址
Get_Localhtml(path);
}
}
总的来说
java爬虫的方法比python的多好多
java的库真特么变态
java从零到变身爬虫大神(一)的更多相关文章
- java从零到变身爬虫大神
刚开始先从最简单的爬虫逻辑入手 爬虫最简单的解析面真的是这样 import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import java. ...
- 【推荐】Java工程师如何从普通成为大神值得一读
本文源自 http://www.hollischuang.com/archives/489 一点感悟 java作为一门编程语言,在各类编程语言中作为弄潮儿始终排在前三的位置,这充分肯定了java语言的 ...
- 从菜鸟到大神:Java高并发核心编程(连载视频)
任何事情是有套路的,学习是如此, Java的学习,更是如此. 本文,为大家揭示 Java学习的套路 背景 Java高并发.分布式的中间件非常多,网上也有很多组件的源码视频.原理视频,汗牛塞屋了. 作为 ...
- 交流希望希望能得到一些大神的指点,加QQ群:249627436 java技术交流群
查了好多资料,发现还是不全,干脆自己整理吧,至少保证在我的做法正确的,以免误导读者,也是给自己做个记录吧! 本人学习java,1年多,对一些基本技巧已掌握.为了使自己能力晋升建了一个QQ群:java交 ...
- 关于Java8 Stream流的利与弊 Java初学者,大神勿喷
题目需求: 1:第一个队伍只要名字为3个字成员的姓名,存储到新集合 2:第一个队伍筛选之后只要前3人:存储到一个新集合 3:第2个队伍只要姓张的成员姓名:存储到一个新集合 4:第2个队伍不要前2人,存 ...
- 大神教你零基础学PS,30堂课从入门到精通
ps视频教程,ps自学视频教程.ps免费视频教程下载,大神教你零基础学PS教程视频内容较大,分为俩部分: 大神教你零基础学PS--30堂课从入门到精通第一部分:百度网盘,https://pan.bai ...
- java大神进阶之路
既然励志在java路上走的更远,那就必须了解java的路径.先看图 更加细化的细节如下 一: 编程基础 不管是C还是C++,不管是Java还是PHP,想成为一名合格的程序员,基本的数据结构和算法基础还 ...
- 一个4年工作经验的java程序员的困惑,怎样才能能为一个架构师,请教大神
一个4年工作经验的java程序员的困惑,怎样才能能为一个架构师 LZ本人想往架构师发展, 业余时间也会看一些书籍, 但是感觉没有头绪, 有些书看了,也没有地方实践 我做了4年的java开发, 在一个公 ...
- 学习 Doug Lea 大神写的——Scalable IO in Java
学习 Doug Lea 大神写的--Scalable IO in Java 网络服务 Web services.分布式对象等等都具有相同的处理结构 Read request Decode reques ...
随机推荐
- ORM和Hibernate的配置方式
分层体系结构: 逻辑上一般分为三层:表述层(提供与用户交互的界面).业务逻辑层(实现各种业务的逻辑).数据库层(负责存放和管理应用的持久性业务数据). 物理上一般分为两层:物理层(每一层都运行在网络上 ...
- Swift:网络库Alamofire
一,Alamofire的说明与配置 1,什么是Alamofire (1)Alamofire 的前身是 AFNetworking.AFNetworking 是 iOS 和 OS X 上很受欢迎的第三方H ...
- Android Priority Job Queue (Job Manager):后台线程任务结果传回前台(三)
Android Priority Job Queue (Job Manager):后台线程任务结果传回前台(三) 在附录文章4,5的基础上改造MainActivity.java和MyJob.ja ...
- POJ2449 (k短路)
#include <cstdio> #include <cstring> #include <cmath> #include <algorithm> # ...
- 使用.bat 文件,批量编译项目文件。
使用.bat 文件,批量编译项目文件. 2008-6-1来源:www.aspcool.com 作者:PCJIM 点击:次 path %path%;D:\Program Files\Microsof ...
- 用C语言计算圆的面积~!!!!!!!
#include <stdio.h>void main(){ int a,b,c,y,g,f; printf("圆柱底面的半径,圆柱的高"); scanf(" ...
- 怎么在手机浏览器上访问电脑本地的文件,局域网内,自建WiFi也可以
首先,电脑要有Mysql+Apache+PHP环境,我直接用Wampsever,开启环境后手机和电脑要再同一个局域网内,然后电脑上打开win+R,输入cmd,再输入ipconfig,就可以看着这台的电 ...
- 作业6 分析项目的NABCD和项目的产品Backlog
项目scrum:邵家文 NABCD模型分析 N(Need 需求)根据采访用户下面可以得出用户的基本需求:1.小孩说:我想要做适合自己能力的四则运算2.小孩说:我想这个四则运算软件里面的题目越做越提高自 ...
- HDU 2089 数位dp/字符串处理 两种方法
不要62 Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submis ...
- MACOS,LINUX,IOS上可用的毫秒级精度时间获取
二话不说,先上代码 void outputCurrentTime(uint32_t seq,const char* type){ struct timeval t_curr; gettimeofday ...