Hadoop学习6--里程碑式的开始之执行第一个程序wordcount
一、先在HDFS文件系统创建对应的目录,具体如下:
1、待处理文件存放目录
/data/wordcount(之所以创建wordcount,是为了对文件分类,对应本次任务名)
命令:hadoop fs -mkdir -p /data/wordcount (-p是同时创建子目录)
2、存放输出文件目录
/output
命令:hadoop fs -mkdir /output
tip:也可以在已连接了集群的eclipse里建立,即:Map/Reduce Location里
不过这种方式建立的文件,所有者是本机,不是我安装hadoop的用户,是否可用,需要验证下。
3、验证以上的成果:
命令:hadoop fs -ls /
二、自己在本地文件系统(也就是某一个目录下)手动创建一个文件,用于测试
1、创建文件
命令:vi ~/test/inputword(vi命令有意思,如果文件不存在,会自动创建一个空文件)
2、打开文件、手动写入一些测试内容:
hello my
hello master
what slave
hello slave
保存。
3、将该文件上传到hdfs文件系统:
命令:hadoop fs -put ~/test/inputword /data/wordcount/
验证方式:
命令:hadoop fs -text /data/wordcount/inputword
三、运行吧
命令:hadoop jar /work/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar wordcount /data/wordcount /output/wordcount
tip:
1、注意jar包的路径一定要写对,否则会提示找不到jar包
2、遇到个问题,一直提示重试连接服务器master:
15/10/29 02:26:38 INFO ipc.Client: Retrying connect to server: master/xx.xx.xx.xx:8032. Already tried 5 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
网上查了下,说是端口还是什么的,这个8032并不是我配置的,和他有关系的可能性不大。
不过其中一句话引起了我的联想,他提到了连接不上JobTacker云云
突然想起来,由于在启动hadoop集群的时候,提示start-all.sh已过时,于是使用的start-dfs.sh
这样在启动后,使用jps验证服务,是少几个的,只有两个namenode,一个datanode和一个默认的jps
于是重新执行了一次 start-all.sh
然后重新运行,成功。
Nice!
把结果截图放上来吧!
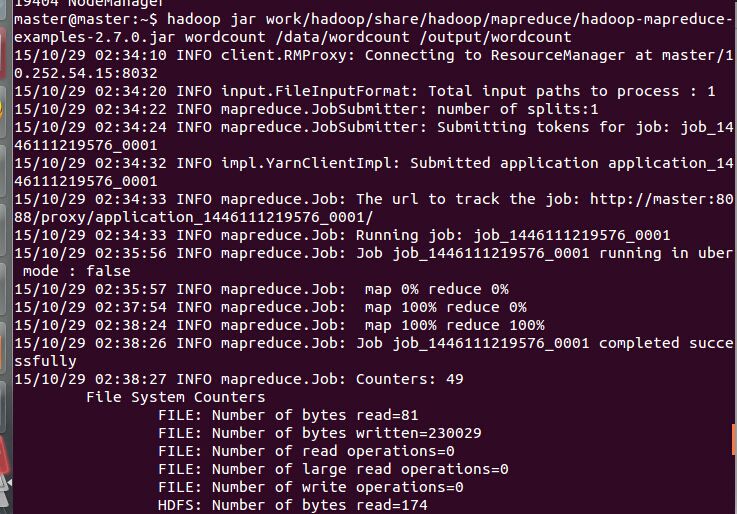
四、验证:
命令:-text /output/wordcount/part-r-00000
结果就是对单词出现个数的统计,略。
Hadoop学习6--里程碑式的开始之执行第一个程序wordcount的更多相关文章
- hadoop第一个程序WordCount
hadoop第一个程序WordCount package test; import org.apache.hadoop.mapreduce.Job; import java.io.IOExceptio ...
- 从零开始学习PYTHON3讲义(三)写第一个程序
<从零开始PYTHON3>第三讲 本页面使用了公式插件,因博客主机过滤无法显示的表示抱歉,并建议至个人主页查看原文. 我见过很多初学者,提到编程都有一种恐惧感,起源是感觉编程太难了.其 ...
- Android学习——在Android中使用OpenCV的第一个程序
刚開始学习Android,因为之前比較熟悉OpenCV,于是就想先在Android上执行OpenCV试试 =============================================== ...
- Mac上使用jenkins+ant执行第一个程序
本文旨在让同学们明白如何让jenkis在mac笔记本上运行,以模拟实际工作中在linux上搭建jenkins服务平台首先按照笔者的习惯先说一下如何安装jenkis和tomcat,先安装tomcat,在 ...
- Spark学习之第一个程序 WordCount
WordCount程序 求下列文件中使用空格分割之后,单词出现的个数 input.txt java scala python hello world java pyfysf upuptop wintp ...
- Objective-C学习笔记(三)——用Objective-C编写第一个程序:Hello,World!
不管是哪一个程序猿,或者是学习哪一门计算机语言.写的第一个程序基本上就是Hello World. 今天我们用OC来实现第一个程序:Hello World. 在Xcode中选择新建一个项目,在对话框中选 ...
- Hadoop学习之旅二:HDFS
本文基于Hadoop1.X 概述 分布式文件系统主要用来解决如下几个问题: 读写大文件 加速运算 对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop学习之旅三:MapReduce
MapReduce编程模型 在Google的一篇重要的论文MapReduce: Simplified Data Processing on Large Clusters中提到,Google公司有大量的 ...
随机推荐
- poj 3320 技巧/尺取法 map标记
Description Jessica's a very lovely girl wooed by lots of boys. Recently she has a problem. The fina ...
- clientX,screenX,pageX,offsetX的异同 【转载】
首先说明一下以上对象都是指javascript中的,不包含其他语言. pageX/pageY: 鼠标相对于整个页面的X/Y坐标.注意,整个页面的意思就是你整个网页的全部,比如说网页很宽很长,宽2000 ...
- 本文使用springMVC和ajax,实现将JSON对象返回到页面
一.引言 本文使用springMVC和ajax做的一个小小的demo,实现将JSON对象返回到页面,没有什么技术含量,纯粹是因为最近项目中引入了springMVC框架. 二.入门例子 ①. 建立工程, ...
- Java并发编程-并发工具包(java.util.concurrent)使用指南(全)
1. java.util.concurrent - Java 并发工具包 Java 5 添加了一个新的包到 Java 平台,java.util.concurrent 包.这个包包含有一系列能够让 Ja ...
- treap树及相关算法
#include "stdafx.h" #include <stdio.h> #include <stdlib.h> #include <string ...
- tomcat 源码解析
how_tomcat_works https://www.uzh.ch/cmsssl/dam/jcr:00000000-29c9-42ee-0000-000074fab75a/how_tomcat_w ...
- Unix 入门
说明:转自以为大神的笔记. 首先,我们一起看看UNIX的目录,因为清楚了目录,才能对UNIX的框架有个大概的印象!当然这里讲的是系统正常运转所必须的,并且一定不能删除或者修改. / 是系统的根目录: ...
- Web前端开发笔试&面试_04_20161019MTBS
1.运用CSS3 ,实现div 沿Y 轴上下循环运动的动画. 我写是:-webkit-animation:xz 3s linear 1s infinite //即XZ轴变化,Y轴不变 正确答案是: & ...
- Oracle数据库——触发器的创建与应用
一.涉及内容 1.理解触发器的概念.作用和类型. 2.练习触发器的创建和使用. 二.具体操作 (实验) 1.利用触发器对在scott.emp表上执行的DML操作进行安全性检查,只有scott用户登录数 ...
- unity, monoDevelop ide 代码提示不起作用的解决方法
monoDevelop ide 代码提示不起作用,可能是因为ide里索引了一些不存在的文件,检查一下solution窗口里是否有文件变红,如下图中springControlEx.cs.将变红的文件re ...