Storm实时计算框架的编程模式
storm分布式流式计算框架。
nimbus:主进程服务(职责就是任务的分配的,程序的分发)
supervisor:工作进程服务(职责就是启动线程池,接受任务,运行任务,报告任务的运行状态)
注意容错:supervisor与nimbus都是基于zookeeper来实现容错,任务运行的元数据存储的zk里面,如果工作节点宕机,zk可以发现,执行触发机制,通知nimbus,对任务进行重新的分发。
===================================================================================
1.Bolt任务crash引起的消息未被应答。此时,acker中所有与此Bolt任务关联的消息都会因为超时而失败,对应的Spout的fail方法将被调用
2.acker任务失败。如果acker任务本身失败了,它在失败之前持有的所有消息都将超时而失败。Spout的fail方法将被调用
3.Spout任务失败。在情况下,与Spout任务对接的外部设备(如MQ)负责消息的完整性。例如,当客户端异常时,kestrel队列会将处于pending状态的所有消息重新放回队列中
任务槽(slot)故障
Worker失败。每个Worker中包含数个Bolt(或Spout)任务。Supervisor负责监控这些任务,当worker失败后会尝试在本机重启它,如果它在启动时连续失败了一定的次数,无法发送心跳信息到Nimbus,Nimbus将在另一台主机上重新分配worker
Supervisor失败。Supervisor是无状态(所有的状态都保存在Zookeeper或者磁盘上)和快速失败(每当遇到任何意外的情况,进程自动毁灭)的,因此Supervisor的失败不会影响当前正在运行的任务,只要及时将他们重新启动即可。
Nimbus失败。Nimbus也是无状态和快速失败的,因此Nimbus的失败不会影响当前正在运行的任务,但是当Nimbus失败时,无法提交新的任务,只要及时将它重新启动即可。
为了管理Spout的可靠性,可以在发射元组的时候,在元组里面包含一个消息ID
===================================================================================
下面看一下提供的编程模型
===================================
实现IRichSpout接口(BaseRichSpout),表示此处就是数据的源(1.设置数据格式-字段,2.初始化业务对象,3.处理完数据之后发送数据到下游) []
@Override
public void declareOutputFields(OutputFieldsDeclarer arg0) {
//设置输出的数据格式字段
} @Override
public void open(Map arg0, TopologyContext arg1,SpoutOutputCollector arg2) {
//首先获取到SpoutOutputCollector
//初始化相关的参数数据
} @Override
public void nextTuple() {
//开始处理数据
}
实现IRichBolt接口(BaseBasicBolt ),表示对数据的处理逻辑接口(初始化对象,处理数据,发送到下游继续处理)
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector arg2) {
//初始化相关的参数对象OutputCollector
} @Override
public void declareOutputFields(OutputFieldsDeclarer arg0) {
//声明处理输出的字段数据
} @Override
public void execute(Tuple arg0) {
//处理业务数据接口
}
组装通过Topology实现,设置spout,bolt的pie流程关系,设置任务的名称以及并行度等参数,此类里面有个main函数就是执行的入口函数。
==================================================================================================
storm的操作算子:
Tident提供了 joins, aggregations, grouping, functions, 以及 filters等能力,所以使用它既可以完成聚合计算,连接计算,我们可以把它嵌入到blot里面,所以blot是处理逻辑,而Tident主要的作用就是提聚合操作的算子。
Trident的topology会被编译成尽可能高效的Storm topology。只有在需要对数据进行repartition的时候(如groupby或者shuffle)才会把tuple通过network发送出去,如果你有一个trident如下
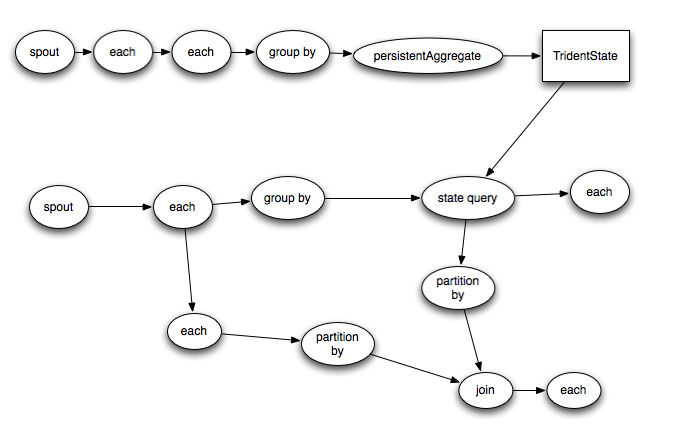

上图就是编译前与编译之后的运行图,也就是说,为了可以并发执行,尽量保证本地计算,编写生成新的拓扑运行。而需要网络传输的数据则进行shuffle操作(网络传输数据)。
Storm实时计算框架的编程模式的更多相关文章
- Storm实时计算:流操作入门编程实践
转自:http://shiyanjun.cn/archives/977.html Storm实时计算:流操作入门编程实践 Storm是一个分布式是实时计算系统,它设计了一种对流和计算的抽象,概念比 ...
- 实时计算框架:Flink集群搭建与运行机制
一.Flink概述 1.基础简介 Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算.Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算.主要特性包 ...
- Spark Streaming实时计算框架介绍
随着大数据的发展,人们对大数据的处理要求也越来越高,原有的批处理框架MapReduce适合离线计算,却无法满足实时性要求较高的业务,如实时推荐.用户行为分析等. Spark Streaming是建立在 ...
- 大数据笔记(二十二)——大数据实时计算框架Storm
一. 1.对比:离线计算和实时计算 离线计算:MapReduce,批量处理(Sqoop-->HDFS--> MR ---> HDFS) 实时计算:Storm和Spark Sparki ...
- 可以穿梭时空的实时计算框架——Flink对时间的处理
Flink对于流处理架构的意义十分重要,Kafka让消息具有了持久化的能力,而处理数据,甚至穿越时间的能力都要靠Flink来完成. 在Streaming-大数据的未来一文中我们知道,对于流式处理最重要 ...
- storm实时计算实例(socket实时接入)
介绍 实现了一个简单的从实时日志文件监听,写入socket服务器,再接入Storm计算的一个流程. 源码 日志监听实时写入socket服务器 package socket; import java ...
- 大数据“重磅炸弹”——实时计算框架 Flink
Flink 学习 项目地址:https://github.com/zhisheng17/flink-learning/ 博客:http://www.54tianzhisheng.cn/tags/Fli ...
- [开源]CSharpFlink(NET 5.0开发)分布式实时计算框架,PC机10万数据点秒级计算测试说明
github地址:https://github.com/wxzz/CSharpFlinkgitee地址:https://gitee.com/wxzz/CSharpFlink 1 计算 ...
- 实时计算框架:Spark集群搭建与入门案例
一.Spark概述 1.Spark简介 Spark是专为大规模数据处理而设计的,基于内存快速通用,可扩展的集群计算引擎,实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流,运算速度相比于Ma ...
随机推荐
- linux设置系统日期时间
设置当前日期: date -s 08/06/2015 设置当前时间:date -s 10:03:00 写入BIOS: clock -w 显示当前日期时间: date
- eclipse注解——作者,创建时间,版本
总结: /** * @author liangyadong * @date ${date} ${time} * @version 1.0 */
- 10socket编程
这一节主要关注的还是粘包问题,我们利用recv实现一个recv_peek函数,它的目的是偷窥目的,它是利用recv的一个msg_peek参数与read的区别,read读取后 会擦除缓冲区的内容,而re ...
- Spring实战6:利用Spring和JDBC访问数据库
主要内容 定义Spring的数据访问支持 配置数据库资源 使用Spring提供的JDBC模板 写在前面:经过上一篇文章的学习,我们掌握了如何写web应用的控制器层,不过由于只定义了SpitterRep ...
- 常用JS
window.opener.location.reload(); 刷新上一个页面 window.opener=null;window.open('','_self');window.close(); ...
- 反转(开关问题) POJ 3276
POJ 3276 题意:n头牛站成线,有朝前有朝后的的,然后每次可以选择大小为k的区间里的牛全部转向,会有一个最小操作m次使得它们全部面朝前方.问:求最小操作m,再此基础上求k. 题解:1.5000头 ...
- 一. Logback与p6spy
一. LogBack配置 配置pom.xml <dependency> <groupId>org.slf4j</groupId> <artifactId> ...
- [Java Web – Maven – 1A]maven 3.3.3 for windows 配置(转)
1.环境 系统环境:windows 2008 R2 JDK VERSION: 1.7.0_10 2.下载地址 MAVEN 下载地址:http://maven.apache.org/download.c ...
- VC++、MFC、COM和ATL的区别
今天看到的,感觉不错.转载了 一.什么是MFC 微软基础类(Microsoft Foundation Classes),实际上是微软提供的,用于在C++环境下编写应用程序的一个框架和引擎,VC++是W ...
- Python中HTTPS连接
permike 原文 Python中HTTPS连接 今天写代码时碰到一个问题,花了几个小时的时间google, 首先需要安装openssl,更新到最新版本后,在浏览器里看是否可访问,如果是可以的,所以 ...