JAVA-FileInputStream之read方法
今天一个友询问FileInputStrem方法的read()和read(byte b) 方法为什么都用-1来判断读文件结束的问题,在此和大家一起学习下。
- 关于FileInputStream
它用于读取本地文件中的字节数据,继承自InputStream类,由于所有的文件都是以字节为向导,因此它适用于操作于任何形式的文件。
关于其最重要的两个方法Read()和Read(byte b) 怎么使用呢?首先我们来查看API文档:
- read()
API文档:
public int read() throws IOException从此输入流中读取一个数据字节。如果没有输入可用,则此方法将阻塞。 指定者: 类 InputStream 中的 read 返回: 下一个数据字节;如果已到达文件末尾,则返回 -1。
解读:
1、此方法是从输入流中读取一个数据的字节,通俗点讲,即每调用一次read方法,从FileInputStream中读取一个字节。
2、返回下一个数据字节,如果已达到文件末尾,返回-1,这点除看难以理解,通过代码测试理解不难。
3、如果没有输入可用,则此方法将阻塞。这不用多解释,大家在学习的时候,用到的Scannner sc = new Scanner(System.in);其中System.in就是InputStream(为什么?不明白的,请到System.class查阅in是个什么东西!!),大家都深有体会,执行到此句代码时,将等待用户输入。
既然说可以测试任意形式的文件,那么用两种不同格式的,测试文件data1.txt和data2.txt,里面均放入1个数字"1",两文件的格式分别为:ANSI和Unicode。
编写一下代码测试:
package com.gxlee;
import java.io.FileInputStream;
import java.io.IOException;
public class Test {
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream("data1.txt");//ANSI格式
for (int i = 0; i < 5; i++) {
System.out.println(fis.read());
}
fis.close();
System.out.println("------------------");
fis = new FileInputStream("data2.txt");//Unicode格式
for (int i = 0; i < 5; i++) {
System.out.println(fis.read());
}
fis.close();
}
}
文件里不是只有一个数字吗,为什么循环5次,什么鬼?稍后知晓,先看输出结果:
49 -1 -1 -1 -1------------------ 255 254 49 0 -1
结果怎么会是这样呢?
1.因为ANSI编码没有文件头,因此数字字符1只占一个字节,并且1的Ascii码为49因此输出49,而Unicode格式有2个字节的文件头,并且以2个字节表示一个字符,对于Ascii字符对应的字符则是第2位补0,因此1的Unicode码的两位十进制分别为49和0;
附:文本文件各格式文件头:ANSI类型:什么都没有,UTF-8类型:EF BB BF,UNICODE类型:FF FE,UNICODE BIG ENDIAN类型:FE FF
2.从返回的结果来看,返回的是当前的字节数据,API文档中原文为:"下一个数据字节,如果已到达文件末尾,则返回 -1。"(英文原文为:the next byte of data, or -1 if the end of the file is reached),应该理解成:此时的指针在下一个数据字节的开始位置。如下图示意:

因此对于未知长度的文件即可通过读取到的内容是否为-1来确定读取是否结束,以下是代码片段:
int b;
while(-1!=(b=fis.read())){
System.out.println(b);
}
- read(byte b)
同样看API:
public int read(byte[] b) throws IOException从此输入流中将最多 b.length 个字节的数据读入一个 byte 数组中。在某些输入可用之前,此方法将阻塞。 覆盖: 类 InputStream 中的 read 参数: b - 存储读取数据的缓冲区。 返回: 读入缓冲区的字节总数,如果因为已经到达文件末尾而没有更多的数据,则返回 -1。
解读:
1、最多b.length个字节的数据读入一个byte数据组中,即,最多将byte数组b填满;
2、返回读入缓冲的字节总数,如果因为已经到达文件末尾而没有更多的数据,则返回-1。这里即这为朋友的问题点,为什么用-1来判断文件的结束。他的理由为,假设3个字节源数据,用2个字节的数组来缓存,当第2次读取的时候到达了文件的结尾,此时应该返回-1了,岂不是只读取到了2个字节?
同样,我们来测试:
测试文件,data.txt,文件格式ANSI,文件内容123,测试代码:
package com.gxlee;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Arrays;
public class Test {
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream("data.txt");//ANSI格式
byte[] b = new byte[2];
for (int i = 0; i < 3; i++) {
System.out.print("第"+(i+1)+"次读取返回的结果:"+fis.read(b));
System.out.println(",读取后数组b的内容为:"+Arrays.toString(b));
}
fis.close();
}
}
输出结果:
第1次读取返回的结果:2,读取后数组b的内容为:[49, 50] 第2次读取返回的结果:1,读取后数组b的内容为:[51, 50] 第3次读取返回的结果:-1,读取后数组b的内容为:[51, 50]
测试数据文件采用的是ANSI格式,放入3个数字,因此为3个字节,这里测试读3次,从代码中可以看出,b为一个byte数组,大小为2,即每次可以存放2个字节。那么问题来了,第一次读取的时候读到2个字节返回很好理解,而第2次的时候,由于只剩下一个字节,此处到了文件的结尾,按照朋友对API文档的理解,应该返回-1才对?
API文档只是对源代码的一种文字说明,具体的意思视阅读者的理解能力有偏差,那么我们来看源代码吧?
public int read(byte b[]) throws IOException {
return readBytes(b, 0, b.length);
}
又调用了 readBytes方法,继续看该方法的源码:
private native int readBytes(byte b[], int off, int len) throws IOException;
晴天霹雳,是个被native修饰的方法,因此没办法继续一步看代码了。没啥好说的,用个代码类继承FileInputStream,覆盖read(byte b)方法,看代码即能理解:
package com.gxlee;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class MyFileInputStream extends FileInputStream{
public MyFileInputStream(String name) throws FileNotFoundException {
super(name);
}
@Override
public int read(byte[] b) throws IOException {
int getData = read();
if (getData==-1) {
return -1;
}else{
b[0] = (byte)getData;
for (int i = 1; i < b.length; i++) {
getData = read();
if(-1==getData)
return i;
b[i] = (byte)getData;
}
}
return b.length;
}
}
原测试代码做小小的改动:
package com.gxlee;
import java.io.FileInputStream;
import java.util.Arrays;
public class Test {
public static void main(String[] args) throws Exception {
FileInputStream fis = new MyFileInputStream("data.txt");//ANSI格式
byte[] b = new byte[2];
for (int i = 0; i < 3; i++) {
System.out.print("第"+(i+1)+"次读取返回的结果:"+fis.read(b));
System.out.println(",读取后数组b的内容为:"+Arrays.toString(b));
}
fis.close();
}
}
输出结果与原结果一致:
第1次读取返回的结果:2,读取后数组b的内容为:[49, 50] 第2次读取返回的结果:1,读取后数组b的内容为:[51, 50] 第3次读取返回的结果:-1,读取后数组b的内容为:[51, 50]
图示:
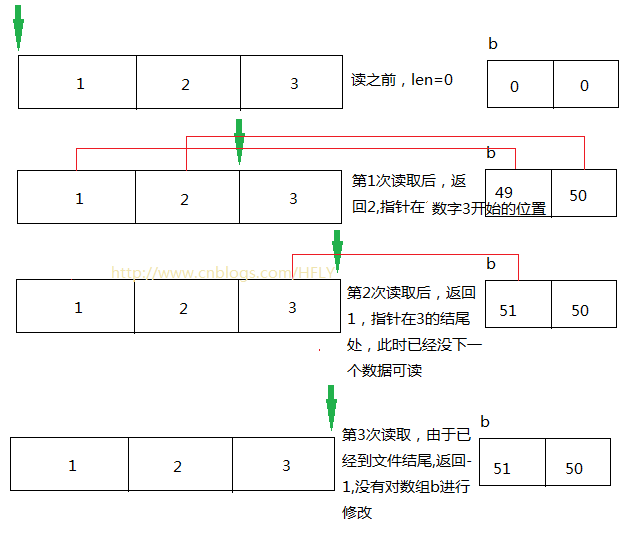
大家对指针的理解,各自把握。
测试读取文本内容:
package com.gxlee;
import java.io.FileInputStream;
public class Test {
public static void main(String[] args) throws Exception {
FileInputStream fis = new MyFileInputStream("data.txt");//ANSI格式
byte[] b = new byte[2];
int len ;
while (-1!=(len = fis.read(b))) {
System.out.println(new String(b,0,len));
}
fis.close();
}
}
准确输出文件内容:
12 3
原创内容,欢迎指点!
JAVA-FileInputStream之read方法的更多相关文章
- [转]Java FileInputStream与FileReader的区别
在解释Java中FileInputStream和FileReader的具体区别之前,我想讲述一下Java中InputStream和Reader的根本差异,以及分别什么时候使用InputStream和R ...
- 使用Java操作文本文件的方法详解
使用Java操作文本文件的方法详解 摘要: 最初java是不支持对文本文件的处理的,为了弥补这个缺憾而引入了Reader和Writer两个类 最初java是不支持对文本文件的处理的,为了弥补这个缺憾而 ...
- java获取文件大小的方法
目前Java获取文件大小的方法有两种: 1.通过file的length()方法获取: 2.通过流式方法获取: 通过流式方法又有两种,分别是旧的java.io.*中FileInputStream的ava ...
- Java FileInputStream与FileReader的区别
在解释Java中FileInputStream和FileReader的具体区别之前,我想讲述一下Java中InputStream和Reader的根本差异,以及分别什么时候使用InputStream和R ...
- Java.io.ObjectOutputStream.writeObject()方法实例
java.io.ObjectOutputStream.writeObject(Object obj) 方法将指定对象写入ObjectOutputStream.该对象的类,类的签名,以及类及其所有超类型 ...
- Java创建对象的六种方法-权当记录一下
1 简介 Java是面向对象的编程语言,只要使用它,就需要创建对象.Java创建对象有六种方法,实际常用的不会这么多,这里权当是记录一下. 2 六种方法 (1)使用new关键字 Pumpkin p1 ...
- 获取当前应用的系统路径工具类和java的System.getProperty()方法介绍
java的System.getProperty()方法可以获取的值,如下: 对于Java程序,无论是未打包的还是打包的JAR或WAR文件,有时候都需要获取它运行所在目录信息,如何做到这一点呢? /** ...
- Java实现时间动态显示方法汇总
这篇文章主要介绍了Java实现时间动态显示方法汇总,很实用的功能,需要的朋友可以参考下 本文所述实例可以实现Java在界面上动态的显示时间.具体实现方法汇总如下: 1.方法一 用TimerTask: ...
- Java Native Interfce三在JNI中使用Java类的普通方法与变量
本文是<The Java Native Interface Programmer's Guide and Specification>读书笔记 前面我们学习了如何在JNI中通过参数来使用J ...
- 浅谈Java中的hashcode方法
哈希表这个数据结构想必大多数人都不陌生,而且在很多地方都会利用到hash表来提高查找效率.在Java的Object类中有一个方法: 1 public native int hashCode(); 根据 ...
随机推荐
- QT5-控件-QFontComboBox-字体选择下拉列表,使用一个标签查看效果
#ifndef MAINWINDOW_H #define MAINWINDOW_H #include <QMainWindow> #include <QFontComboBox> ...
- mysql服务启动
1.C:\Program Files (x86)\MySQL\mysql-5.5.33-win32\bin>net stop mysqlMySQL 服务正在停止.MySQL 服务已成功停止. 2 ...
- 用C++类模板实现栈结构出现的问题以及思考
C++中使用了模板来减少方法相同但是类型不一样带来的函数重载以及大量复制代码的问题.这里主要说说类模板 类模板的定义: template<TYPENAME Type> clas ...
- stdarg.h详解
读Linux内核中的vsprintf函数的时候遇到了C语言的可变参数调用,查了挺多资料还是这篇比较详细,而且自己验证了下,确实如此 (一)写一个简单的可变参数的C函数 下面我们来探讨如何写一个简单的 ...
- windows 下安装使用ipython
转自:https://my.oschina.net/u/1431433/blog/189337 1. 下载安装Python 下载: python-3.3.3.amd64.msi (救在Python.o ...
- Linux查看机器是多少位
命令: file /bin/ls或者file /sbin/init 示例: 如上所示,我的机器是32位的.
- 开源一套DirectUI界面库
http://www.cppblog.com/weiym/archive/2012/07/03/181307.html
- BZOJ 3153 Sone1
题解:水水哒AAA树啦 #include<iostream> #include<cstdio> #include<cmath> #include<algori ...
- Android豆瓣图书查询Demo
原文出自:方杰| http://fangjie.info/?p=26 转载请注明出处 首先先看一下Demo预览效果吧,主要也就是两个Activity.涉及到的技术有zxing开源项目的使用,网络协议豆 ...
- [转]10款 Web 开发常备工具
文章地址:https://my.oschina.net/u/2903254/blog/798135 工欲善其事,必先利其器.如今 Web 开发标准越来越高,Web 开发者也在不断寻找途径提升自己的技能 ...