python学习笔记——正则表达式regex
1 概述
1.1 定义
本质是由一系列字符和特殊符号组成的字串,用来表示一定规则的某一类字符串。
1.2 特点
正则表达式是一个独立的技术,其在多种编程语言中使用。
在python语言中的正则表达式模块为 re 模块
2 正则表达式
2.1 元字符
首先引入re模块
tarena@tedu:~$ ipython3 In [1]: import re
# 单个字符
匹配规则:匹配相应的字符
例如 a 匹配 a ab 匹配 ab
In [2]: re.findall('ab','abc')
Out[2]: ['ab']
# 匹配单个字符
元字符:.
匹配规则:匹配除 ‘\n’ 外的任意一个字符
In [4]: re.findall('a.b','acbadbab')
Out[4]: ['acb', 'adb']
# 匹配字符串的开头位置
元字符 : ^
匹配规则 : ^ 位置必须为字符串的开始位置才可,通常和其他元字符同用
In [6]: re.findall('^ab','abb')
Out[6]: ['ab']
# 匹配字符串的结尾位置
元字符: $
匹配规则 : 匹配字符串的结尾位置
In [8]: re.findall('ab$','aab')
Out[8]: ['ab']
# 匹配重复
元字符 : *
匹配规则 :匹配前面出现的正则表达式0次或多次
In [10]: re.findall('ab*','aabbabbb')
Out[10]: ['a', 'abb', 'abbb']
# 匹配重复
元字符 : +
匹配规则 : 匹配前面出现的正则表达式1次或多次
In [11]: re.findall('ab+','aabbabbb')
Out[11]: ['abb', 'abbb']
# 匹配重复
元字符 : ?
匹配规则: 匹配前面出现的正则表达式0次或1次
In [13]: re.findall('ab?','aababb')
Out[13]: ['a', 'ab', 'ab']
# 匹配重复
元字符 : {n}
匹配规则: 匹配指定重复的次数
In [14]: re.findall('ab{2}','aababbabbb')
Out[14]: ['abb', 'abb']
# 匹配重复
元字符 : {m,n}
匹配规则 : 匹配重复m次到n次
In [16]: re.findall('ab{1,2}','aababbabbbabbbb')
Out[16]: ['ab', 'abb', 'abb', 'abb']
In [17]: re.findall('ab{1,3}','aababbabbbabbbb')
Out[17]: ['ab', 'abb', 'abbb', 'abbb']
In [18]: re.findall('ab{2,3}','aababbabbbabbbb')
Out[18]: ['abb', 'abbb', 'abbb']
# 字符集匹配
元字符 : ['abc...']
匹配规则 : 匹配字符集中任意一个字符
In [19]: re.findall('[abcd]','Today is February 26th, the gem index fell 2.10%')
Out[19]: ['d', 'a', 'b', 'a', 'd']
# 匹配字符区间
元字符 : [0-9] [a-z] [A-Z]
匹配规则 : 匹配区间内任意一个字符,不同区间可以写在一起,同时还能添加其他的字符集(一般将其写在字符区间前面)
In [23]: re.findall('[a-z]+','Today is February 26th, the gem index fell 2.10%')
Out[23]: ['oday', 'is', 'ebruary', 'th', 'the', 'gem', 'index', 'fell']
In [24]: re.findall('[_0-3a-z]+','Today is February 26th, the gem_index fell 2.10%')
Out[24]: [']
不添加加号+ 的话,会输出在范围内的单个字母。
# 集合取反
元字符:[ ^ ....]
匹配规则 :匹配任意一个不再集合中的字符
In [26]: re.findall('[^a-z]+','Today is February 26th, the gem index fell 2.10%')
Out[26]: [', ', ', ' ', ' ', ' ', ' 2.10%']
# (非)数字字符
元字符(匹配规则):\d(任意一个数字字符);\D(任意一个非数字字符)
In [27]: re.findall('\d+','a0123456789b')
Out[27]: [']
In [28]: re.findall('\D+','a0123456789b')
Out[28]: ['a', 'b']
# (非)数字字母下划线
元字符(匹配规则):\w(任意一个数字字母下划线,等价于[_0-9a-zA-Z])\W(任意一个特殊字符,等价于非[^_0-9a-zA-Z])
In [29]: re.findall('\w+','1_!_2_@_3_#_4_$')
Out[29]: ['1_', '_2_', '_3_', '_4_']
In [30]: re.findall('\W+','1_!_2_@_3_#_4_$')
Out[30]: ['!', '@', '#', '$']
# (非)空字符
元字符(匹配规则):\s(任意空字符,等价于[ \n \r \t \0 ]) \S(任意非空字符)
In [33]: re.findall('\S+','Today is February 26th, the gem index fell 2.10%')
Out[33]: ['Today', 'is', 'February', '26th,', 'the', 'gem', 'index', 'fell', '2.10%']
In [34]: re.findall('\s+','Today is February 26th, the gem index fell 2.10%')
Out[34]: [' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ']
# 开头 / 结尾位置
元字符(匹配规则):\A(匹配字符串的开头位置,等价于 ^ )\Z(匹配字符串的结尾位置,等价于 $ )
In [35]: re.findall('\Aab\Z','aabb')
Out[35]: []
In [36]: re.findall('\Aab\Z','ab')
Out[36]: ['ab']
# (非)边界位置
元字符(匹配规则):\b(匹配单词边界位置) \B(匹配非单词边界位置)
单词边界(注) : 数字字母下划线和其他字符交界的位置认为是单词边界
In [5]: re.findall(r'ab\b','ab aab') Out[5]: ['ab', 'ab'] In [6]: re.findall(r'ab\b','ab abb') Out[6]: ['ab']
另
In [18]: re.findall(r'ab\B','aab aabb') Out[18]: ['ab'] In [19]: re.findall(r'ab\B','abb aabb') Out[19]: ['ab', 'ab']
# 或关系
元字符 : |
匹配规则 : 连接多个正则表达式 形成或关系
In [22]: re.findall('abc|bcd','abcde bcdef')
Out[22]: ['abc', 'bcd']
总结:
1 匹配单个字符:普通字符串 . \d \D \w \W \s \S [ ... ] [ ^... ]
2 匹配位置:^ $ \A \Z \b \B
3 匹配重复次数:* + ? { n } { m , n }
4 其他:|
2.2 转义字符
1 正则表达式中有很多特殊字符为元字符 (如* $ ? + \d \s),如果在设定匹配时需要匹配到特殊字符则用转义
例如 \ ---> \\ * --> \* \d --> \\d
2 当使用某个编程语言时,正则表达式往往要以字符串的形式传入,而编程语言的字符串又有转义性质
2.3 贪婪和非贪婪
贪婪模式:当重复次数不确定时,正则表达式总是尽可能多的向后匹配
常见的贪婪模式的元字符有:* + ? { m , n }
非贪婪模式:再具有重复的元字符后加?
示例:
In [23]: re.findall('ab*','abbba')
Out[23]: ['abbb', 'a']
In [24]: re.findall('ab*?','abbba')
Out[24]: ['a', 'a']
In [25]: re.findall('ab?','abbba')
Out[25]: ['ab', 'a']
In [26]: re.findall('ab??','abbba')
Out[26]: ['a', 'a']
In [27]: re.findall('ab+','abbba')
Out[27]: ['abbb']
In [28]: re.findall('ab+?','abbba')
Out[28]: ['ab']
2.4 子组
正则表达式子组:在整段正则表达式中用()截取一部分作为正则表达式的一个子组。
一个正则表达式中原则上可有多个子组,但子组间不能出现交叉
一般而言,从外到内,从左到右,依次称为第一子组、第二子组。。。
In [29]: re.findall('a(bc)','abbcabc')
Out[29]: ['bc']
子组的作用:
(1)子组作为一个整体,可改变重复元字符的作用范围
(2)很多编程语言函数可单独提取子组的内容
(3)在使用和调用上更加方便
子组的命名和调用:
子组的命名:(?P<name>abcd)
子组的调用:(?P=name)
(?P<dog>ab)cdef(?P=dog)
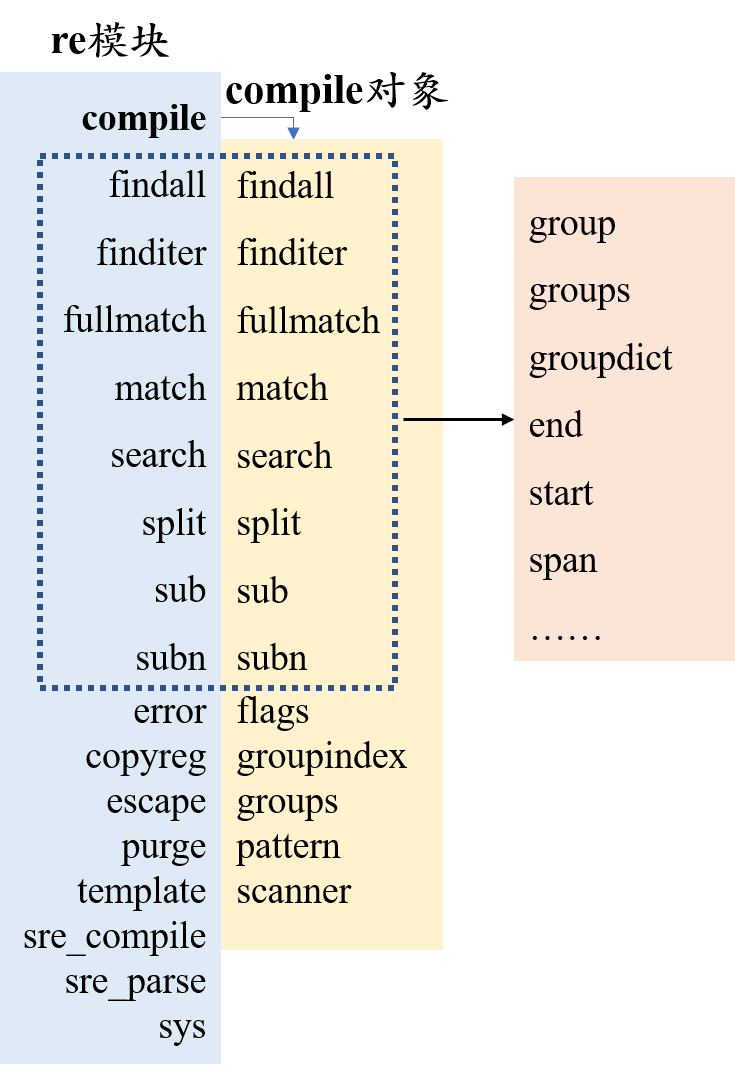
2.5 模块 re
re模块中的方法及属性
compile(pattern, flags=0)
功能:生成正则表达式对象
参数:pattern:正则表达式;flags:扩展标志位(默认为0,表示不进行任何扩展)
返回值:正则表达式对象
obj = re.compile('abc')
以下函数既能在re模块中直接调用,也可用compile对象直接调用
对比如下图所示:
re.findall(pattern, string, flags=0)
功能:根据正则表达式匹配目标字符串
参数:
pattern:正则表达式
string:目标字符串
flags:正则扩展标志位
返回值:匹配到的所有内容以列表返回,若有分组则只返回子组能匹配到的内容
obj.findall(string=None, pos=0, endpos=2^63-1)
功能:根据正则表达式匹配目标字符串
参数:
string:目标字符串
pos:匹配目标字符串的起始位置
endpos:匹配目标字符串的结束位置,默认值为2^63-1
返回值:匹配到的所有内容以列表返回,如果有分组则只返回子组能匹配到的内容
finditer()
功能:同findall
参数:同findall
返回值:返回一个迭代对象,迭代获取的每个值为match obj
* match 对象:finditer match fullmatch search
这些函数将正则匹配到的结果以match对象的形式给出,方便进行具体操作
fullmatch()
功能:用正则表达式完全匹配某个字符串
参数:目标字符串
返回值:返回匹配到的match对象,如果没有匹配到返回None
match()
功能:匹配字符串的开头
参数:目标字符串
返回值:若匹配到内容返回match object,否则返回None
search()
功能:匹配第一处符合正则的字串
参数:目标字串
返回值:如果匹配到内容则返回match object,否则返回None
split()
功能:按照正则表达式切割字符串
参数:目标字符串
返回值:将切割后的字符串放入列表
sub(re_str, string, max)
功能:用指定字符串替换正则表达式匹配到的部分
参数:
re_str:待替换的字符串
string:目标字符串
max:最多替换几处
返回值:替换后的字符串
subn(re_str, string, max)
功能:用指定字符串替换正则表达式匹配到的部分
参数:
re_str:待替换的字符串
string:目标字符串
max:最多替换几处
返回值:返回值为二元元组,第一项为替换后的字符串,第二项为实际替换几处
compile返回对象的属性
flags:正则表达式表示位(用整型表示)
pattern:正则表达式
groupindex:返回以捕获的名称为键,第几组为值的字典
groups:正在表达式中一共有多少个子组
match search fullmatch finditer
match对象属性和方法
属性:
pos:匹配目标字符串的开始位置
endpos:匹配目标字符串的结束位置
lastgroup:获取最后一个子组的名称,如果没名字则为None
lastindex:获取最后一个子组是第几组
re:match匹配所用的正则表达式
regs:正则表达式整体及每个子组所匹配的部分
string:match匹配的目标字符串
方法:
start():得到匹配内容在字符串中的开始位置
end():得到匹配内容在字符串中的结束位置(结束字符下标的下一个)
span():得到匹配到的内容在字符串中的起止位置
group(n):
功能:获取match对象匹配到的内容
参数:n(默认为0)表示整个正则匹配到的内容,当给n赋一个正整数时则表示要获取第n个子组匹配内容
返回值:返回匹配到的字符串
groups():获取所有子组匹配到的内容
groupdict():将捕获组的名称和匹配的内容形成键值对关系
re.compile re.findall re.match re.search……中的flags
'A','ASCII',
'S','DOTALL', 让 . 可以匹配换行
'I', 'IGNORECASE' 忽略大小写
'L','LOCALE',
'M', 'MULTILINE' 作用于 ^ $ 使其能匹配每行的开头结尾
'T','TEMPLATE',
'U','UNICODE'
'X','VERBOSE', 让你的正则可以添加以#开头的注释
当多个flag同时使用时 中间用竖线分割
例如:re.I | re.S
3 实例
3.1 简单示例
匹配长度为8-10位的密码,必须以字母开头,数字字母下划线组成
In [2]: re.findall(r'^[a-zA-Z]\w{7,9}$','abc123_a')
Out[2]: ['abc123_a']
匹配身份证号
In [6]: re.search(r'\d{17}(\d|x)','123123123123123123').group()
Out[6]: '123123123123123123'
匹配一段文字中以大写字母开头的单词
In [14]: re.findall(r'\b[A-Z]\w*\b',data)
Out[14]: ['Python', 'Hello', 'World']
3.2 综合应用
import re
obj = re.compile(r'hello',re.I|re.S)
print(obj.findall('hello world Hello Kitty'))
# ['hello', 'Hello']
print('*****')
s = '''hello world
nihao china
'''
print(re.search('.*',s,re.S).group())
# hello world
# nihao china
# (注,可以匹配换行)
print('*****')
print(re.search('world$',s,re.M).group())
# world
print('*****')
print(re.search(
'''hello#注释1
\s#注释2
\w+#注释3
''',s,re.X).group())
# hello world
import re
re_obj = re.compile(r'(?P<dog>ab)c(de)')
match_obj = re_obj.search('abcdefg')
print(match_obj)
# <_sre.SRE_Match object; span=(0, 5), match='abcde'>
# print(dir(match_obj))
#属性
print(match_obj.lastgroup) # None
print(match_obj.re) #re.compile('(?P<dog>ab)c(de)')
print(match_obj.regs) #((0, 5), (0, 2), (3, 5))
print(match_obj.string) #abcdefg
print("************************")
#函数
print(match_obj.span()) #(0,5)
print(match_obj.group(0)) #abcde
print(match_obj.group(1)) #ab
print(match_obj.group(2)) #de
print(match_obj.groups()) #('ab', 'de')
print(match_obj.groupdict()) #{'dog': 'ab'}
import re
obj = re.compile(r'(?P<dog>ab)cd(ef)')
result = obj.findall('abcdeabcfg')
result = obj.finditer('abcdefgabch')
result = obj.fullmatch('abcdef#%')
result = obj.match('abcd')
result = obj.search('abcdefcdg')
result = obj.split('hello world nihao china@Beijing')
result = obj.sub('##',\
'hello world nihao china@Beijing',3)
result = obj.subn('##',\
'hello world nihao china@Beijing',6)
if result != None:
print(result)
else:
print("match nothing")
# for i in result:
# print(i.group())
print(obj.flags)
print(obj.pattern)
print(obj.groups)
print(obj.groupindex)
# print(obj.scanner('abcdef'))
python学习笔记——正则表达式regex的更多相关文章
- [Python学习笔记]正则表达式总结
常用缩写字符及其含义表格查询 缩写字符分类 含义 \d 0-9的任意数字 \D 除0-9的数字以外的任何字符 \w 任何字母.数字或下划线字符(可以认为是匹配"单词"字符) \W ...
- Python学习笔记——正则表达式入门
# 本文对正则知识不做详细解释,仅作入门级的正则知识目录. 正则表达式的强大早有耳闻,大一时参加一次选拔考试,题目就是用做个HTML解析器,正则的优势表现得淋漓尽致.题外话不多讲,直接上干货: 1. ...
- python学习笔记----正则表达式
正则: regular expression 常用的场景: #正则的包 >>> import re #match:开头匹配,匹配到,返回一个匹配对象,否则返回None >> ...
- Python学习笔记——正则表达式
今天把之前学的正则表达式好好总结总结. 一.元字符 . : .表示可以匹配任意一个字符 \d : \d表示可以匹配任意一个数字 \D : \D表示可以匹配任意一个非数字 \s : \s表示 ...
- Python学习笔记基础篇——总览
Python初识与简介[开篇] Python学习笔记——基础篇[第一周]——变量与赋值.用户交互.条件判断.循环控制.数据类型.文本操作 Python学习笔记——基础篇[第二周]——解释器.字符串.列 ...
- Python学习笔记(十一)
Python学习笔记(十一): 生成器,迭代器回顾 模块 作业-计算器 1. 生成器,迭代器回顾 1. 列表生成式:[x for x in range(10)] 2. 生成器 (generator o ...
- Python学习笔记,day5
Python学习笔记,day5 一.time & datetime模块 import本质为将要导入的模块,先解释一遍 #_*_coding:utf-8_*_ __author__ = 'Ale ...
- 【目录】Python学习笔记
目录:Python学习笔记 目标:坚持每天学习,每周一篇博文 1. Python学习笔记 - day1 - 概述及安装 2.Python学习笔记 - day2 - PyCharm的基本使用 3.Pyt ...
- Python 学习笔记(上)
Python 学习笔记(上) 这份笔记是我在系统地学习python时记录的,它不能算是一份完整的参考,但里面大都是我觉得比较重要的地方. 目录 Python 学习笔记(上) 基础知识 基本输入输出 模 ...
随机推荐
- C 图像处理 颜色相关宏定义
很多年前整理的,像素处理的宏定义,包括r8g8b8到r5g6b5之间的相互转化,浮点数像素与整数值之间的相互转化,像素值的插值.取反等处理.具体没什么好说的,宏定义的代码还是很容易看的.这套东西对搞图 ...
- [19] 半球形(Hemisphere)图形的生成算法
顶点数据的生成 bool YfBuildHemisphereVertices ( Yreal radius, Yuint slices, Yuint stacks, YeOriginPose orig ...
- Vue Cli安装以及使用
因为公司项目要用vue框架,所以会用vue-cli来新建项目.用过vue的都知道,要全局安装vue以及脚手架vue-cli,然后执行vue init webpack projectname来新建v ...
- [转]聊聊技术选型 - Angular2 vs Vue2
转载:https://juejin.im/post/58cab85b44d9040069f38f7a "Come, and take choice of all my library, An ...
- Tomcat发布Maven项目遇到异常:java.lang.OutOfMemoryError: PermGen space
前言: 本问题出现在tomcat 7发布 web3.0Maven项目的时候出现. 问题阐述: 异常:java.lang.OutOfMemoryError:PermGen space 解决如下: 1. ...
- 内存泄漏 Memory Leaks 内存优化 MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- 用C#代码编写的SN快速输入工具
一般软件都要输入序列号(SN),而大家平时用的最多的恐怕是盗版软件,通常盗版软件的序列号(SN)都保存成:XXXXX-XXXXX-XXXX-XXXX的形式. 而软件输入序列号的地方通常都是几个文本框( ...
- Kafka集群环境搭建(2.9.2-0.8.2.2)
Kafka是一个分布式.可分区.可复制的消息系统.Kafka将消息以topic为单位进行归纳:Kafka发布消息的程序称为producer,也叫生产者:Kafka预订topics并消费消息的程序称为c ...
- c++call back
#include "stdafx.h" struct A; typedef void(A::*MemFuncPtr) (int* e); class A { int a; }; c ...
- Android -- ImageLoader简析
图片的内存缓存实现 Image-Loader库有一个较完整的内存缓存实现,使用者可以根据需要选择已经实现的策略,也可以定制自己项目中需要的策略. 内存缓存实现代码在memory和memory.impl ...