大数据入门第十一天——hive详解(三)hive函数
一、hive函数
1.内置运算符与内置函数
函数分类:
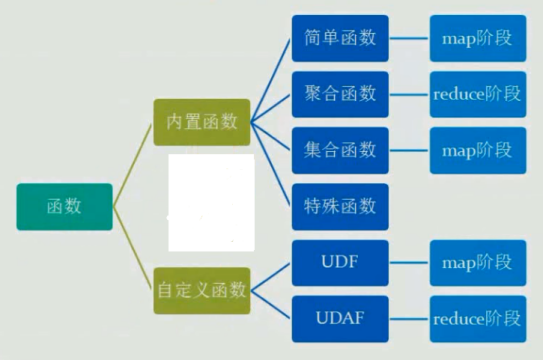
查看函数信息:
DESC FUNCTION concat;
常用的分析函数之rank() row_number(),参考:https://www.cnblogs.com/wujin/p/6051768.html
常用20个内置函数:
https://www.cnblogs.com/kimbo/p/6288516.html
常用函数:https://www.iteblog.com/archives/2258.html
完整参考官方手册:https://www.cnblogs.com/liupengpengg/p/7908274.html
窗口函数推荐教程:http://www.aboutyun.com/thread-22652-1-1.html
结合相关实例:https://blog.csdn.net/dingchangxiu11/article/details/83145151
开窗函数OVER用法介绍:http://blog.csdn.net/sherri_du/article/details/53312085
http://blog.csdn.net/qq_26937525/article/details/54925827
窗口函数理解与实践:http://blog.csdn.net/xiepeifeng/article/details/42676567
窗口函数与分析函数用法:http://www.cnblogs.com/skyEva/p/5730531.html
http://blog.csdn.net/sunnyyoona/article/details/56484919
PARTITON BY 与 ORDER BY语句非常重要:
窗口函数和聚合函数不同的地方在于聚合函数每个分组只产生一条记录,而窗口函数则是每条记录都会生成一条记录
SQL 窗口查询引入了三个新的概念:窗口分区、窗口帧、以及窗口函数。 PARTITION 语句会按照一个或多个指定字段,将查询结果集拆分到不同的 窗口分区 中,并可按照一定规则排序。
如果没有 PARTITION BY,则整个结果集将作为单个窗口分区;
如果没有 ORDER BY,我们则无法定义窗口帧,进而整个分区将作为单个窗口帧进行处理。
行列转换:https://www.cnblogs.com/dongxiucai/p/9784011.html
lateral view的用法参考maxcomputer常用SQL小结
2.自定义函数
分类
UDF 作用于单个数据行,产生一个数据行作为输出。(数学函数,字符串函数)
UDAF(用户定义聚集函数):接收多个输入数据行,并产生一个输出数据行。(count,max)
自定义UDF:
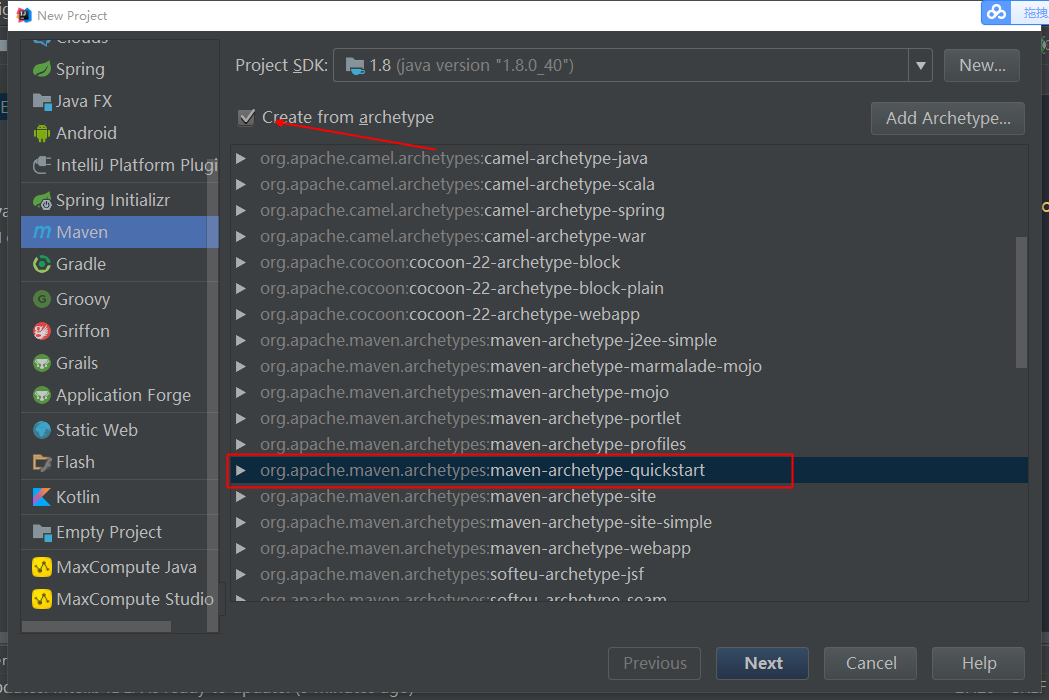
1.新建工程
这里选择IDEA中建立普通的maven工程,如果不使用maven,则导入hive安装包中Lib下除掉php、perl等的jar
2.引入依赖
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
// 推荐保持和hadoop版本一致
3.定义继承于UDF的类,编写evaluate()方法(必须是Public):
public class ToLowerCaseUDF extends UDF {
public String evaluate(String src) {
if (src == null) {
return "";
}
return src.toLowerCase();
}
}
若需要添加函数说明,使得可以通过DESC查看,可以添加以下注解(_FUNC_会替换为函数名)
@Description(name = "deprecation",
value = "_FUNC_(date, price) - from the input date string(yyyyMMdd), " +
"returns the deprecation price by computing price and "
+ "the depreciation rate of the second-hand car.",
extended = "Example:\n" +
" > SELECT _FUNC_(date_string, price) FROM src;")
public class TestUDF extends UDF {
4.打成jar包
使用maven的package打包,如果不使用IDEA的打包,可以切换到项目根目录,手动命令打包:
mvn clean package
5.上传jar包
这里就使用rz上传了
6.使用UDF
临时:
不过这个临时函数, 其生命周期和hive的这个交互session保持一致, 一旦退出, 这个临时函数就消失了.
0: jdbc:hive2://localhost:10000> add JAR /home/hadoop/hiveUDF.jar;
// 在hive中上传jar到hive的classpath
create temporary function toprovince as 'com.jiangbei.ToLowerCaseUDF';
//定义一个函数与UDF对应(as后接类的全路径名),这里手误,函数名应该命令为tolowercase
0: jdbc:hive2://localhost:10000> SELECT toprovince("HELLO");
+--------+--+
| _c0 |
+--------+--+
| hello |
+--------+--+
1 row selected (0.613 seconds)
0: jdbc:hive2://localhost:10000>
hive> DROP TEMPORARY FUNCTION IF EXISTS deprecation;
//删除函数
永久:
1. 把自定义函数的jar上传到hdfs中.
hdfs dfs -put lower.jar 'hdfs:///path/to/hive_func';
2. 创建永久函数
hive> create function xxoo_lower as 'test.ql.LowerUDF' using jar 'hdfs:///path/to/hive_func/lower.jar'
3. 验证
hive> select xxoo_lower("Hello World");
hive> show functions;
4.删除
hive> drop function xxoo_lower;
//补充:处理JSON的内置函数:jason:
hive> select
get_json_object(‘{“store”:{“fruit”:\[{"weight":8,"type":"apple"},{"weight":9,"type":"pear"}], “bicycle”:{“price”:19.95,”color”:”red”}}, “email”:”amy@only_for_json_udf_test.net”, “owner”:”amy” } ‘,’$.owner’)
from dual;
3.Transform
Hive的 TRANSFORM 关键字提供了在SQL中调用自写脚本的功能
适合实现Hive中没有的功能又不想写UDF的情况
实例:
CREATE TABLE u_data_new (
movieid INT,
rating INT,
weekday INT,
userid INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'; add FILE weekday_mapper.py; INSERT OVERWRITE TABLE u_data_new
SELECT
TRANSFORM (movieid, rating, unixtime,userid)
USING 'python weekday_mapper.py'
AS (movieid, rating, weekday,userid)
FROM u_data;
#!/bin/python
import sys
import datetime for line in sys.stdin:
line = line.strip()
movieid, rating, unixtime,userid = line.split('\t')
weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()
print '\t'.join([movieid, rating, str(weekday),userid])
参考:http://blog.csdn.net/tianjun2012/article/details/64500499
大数据入门第十一天——hive详解(三)hive函数的更多相关文章
- 大数据入门第七天——MapReduce详解(一)入门与简单示例
一.概述 1.map-reduce是什么 Hadoop MapReduce is a software framework for easily writing applications which ...
- 大数据入门第七天——MapReduce详解(二)切片源码浅析与自定义patition
一.mapTask并行度的决定机制 1.概述 一个job的map阶段并行度由客户端在提交job时决定 而客户端对map阶段并行度的规划的基本逻辑为: 将待处理数据执行逻辑切片(即按照一个特定切片大小, ...
- 大数据入门第十一天——hive详解(一)入门与安装
一.基本概念 1.什么是hive The Apache Hive ™ data warehouse software facilitates reading, writing, and managin ...
- 大数据入门第十一天——hive详解(二)基本操作与分区分桶
一.基本操作 1.DDL 官网的DDL语法教程:点击查看 建表语句 CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data ...
- 大数据入门第十六天——流式计算之storm详解(一)入门与集群安装
一.概述 今天起就正式进入了流式计算.这里先解释一下流式计算的概念 离线计算 离线计算:批量获取数据.批量传输数据.周期性批量计算数据.数据展示 代表技术:Sqoop批量导入数据.HDFS批量存储数据 ...
- 大数据入门第八天——MapReduce详解(三)MR的shuffer、combiner与Yarn集群分析
/mr的combiner /mr的排序 /mr的shuffle /mr与yarn /mr运行模式 /mr实现join /mr全局图 /mr的压缩 今日提纲 一.流量汇总排序的实现 1.需求 对日志数据 ...
- 大数据入门第十七天——storm上游数据源 之kafka详解(三)其他问题
一.kafka文件存储机制 1.topic存储 在Kafka文件存储中,同一个topic下有多个不同partition,每个partition为一个目录,partiton命名规则为topic名称+有序 ...
- 大数据入门第十七天——storm上游数据源 之kafka详解(一)入门与集群安装
一.概述 1.kafka是什么 根据标题可以有个概念:kafka是storm的上游数据源之一,也是一对经典的组合,就像郭德纲和于谦 根据官网:http://kafka.apache.org/intro ...
- 大数据入门第十七天——storm上游数据源 之kafka详解(二)常用命令
一.kafka常用命令 1.创建topic bin/kafka-topics. --replication-factor --zookeeper mini1: // 如果配置了PATH可以省略相关命令 ...
随机推荐
- Ad-hoc 查询以及动态SQL的罪恶[译]
本文为翻译文章,原文地址:https://www.simple-talk.com/blogs/2009/08/03/stolen-pages-ad-hoc-queries-and-the-sins-o ...
- HDFS pipeline写 -- datanode
站在DataNode的视角,看看pipeline写的流程,本文不分析客户端部分,从客户端写数据之前拿到了3个可写的block位置说起. 每个datanode会创建一个线程DataXceiverServ ...
- Oracle EBS 报表日期格式问题
1.确保参数日期值集选择:FND_STANDARD_DATE 2.将程序的入口参数选择为 varchar2类型 3.注意输出和游标时参数的截断 to_date(substr(p_DATE_from, ...
- 名词解释:Linux内存管理之RSS和VSZ
Linux内存管理中不管是top命令还是pmap命令,都会有RSS和VSZ这两个名词,这里解释一下: RSS( Resident Set Size )常驻内存集合大小,表示相应进程在RAM中占用了多少 ...
- Linux 系统学习梳理_【All】
第一部分---基础学习 00.Linux操作系统各版本ISO镜像下载 00.Linux系统下安装Vmware(虚拟机) 00.Linux 系统安装[Redhat] 00.Linux 系统安装[Cent ...
- Spring @Autowired注解在非Controller/Service中注入为null
参考:https://blog.csdn.net/qq_35056292/article/details/78430777 问题出现: 在一个非controller/service类中,我需要注入Co ...
- 关于RSA、公钥、私钥、加密、签名的那些概念
前言 作为一名程序员,经常会听到加密解密之类的词.而非对称加密技术,应用的非常广泛.本文不写加密技术的原理,只是希望以一个简单的类比,让大家了解非对称加密中常见词的概念,以及它的作用. 介绍 在RSA ...
- [T-ARA][yayaya]
歌词来源:http://music.163.com/#/song?id=22704449 U look at me Right T-ARA U Ready Let me seeya LaLaLaLa ...
- pthread线程内存布局
http://www.cnblogs.com/snake-hand/p/3148191.html 我们从图上可以看出,两个线程之间的栈是独立的,其他是共享的,所以,在操作共享区域的时候才有可能出现同步 ...
- Install Weblogic12C
1. 安装JDK软件 1.1)jdk版本选择 由于jdk编译出class文件是一个二进制文件,其中前四个字节是magic位,第五到第六个字节对应于minor和major.class文件的minor和m ...