Python学习---爬虫学习[scrapy框架初识]
Scrapy
Scrapy是一个框架,可以帮助我们进行创建项目,运行项目,可以帮我们下载,解析网页,同时支持cookies和自定义其他功能。
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
【更多参考】http://www.cnblogs.com/wupeiqi/articles/6229292.html
scrapy框架介绍以及安装
Linux
pip3 install scrapy
Windows
1. pip3 install wheel
1-1安装Twisted
a. http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted, 下载:Twisted-17.1.0-cp35-cp35m-win_amd64.whl
b. 进入文件所在目录
c. pip3 install Twisted-17.1.0-cp35-cp35m-win_amd64.whl
2. pip3 install scrapy
3. windows上scrapy依赖 https://sourceforge.net/projects/pywin32/files/
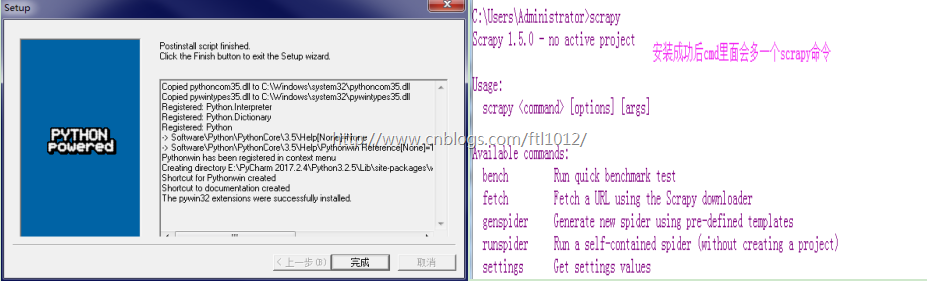
创建一个scrapy工程:
创建一个scrapy工程:
scrapy startproject scy
scrapy genspider baidu baidu.com

baidu.py里面的内容
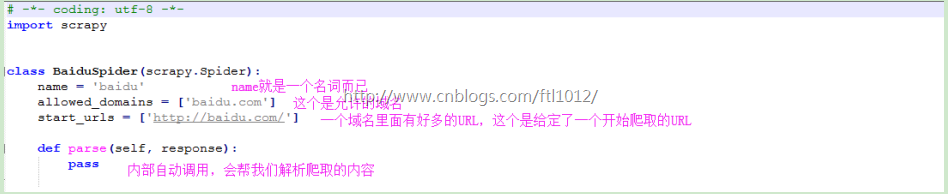
response.text可以打印具体的内容
scrapy crawl baidu
scrapy crawl baidu --nolog [不打印日志]

修改settting.py 让spider不去访问robot.txt文件

附: 查看spider文件的其他模板
scrapy genspider --list

项目结构以及爬虫应用简介
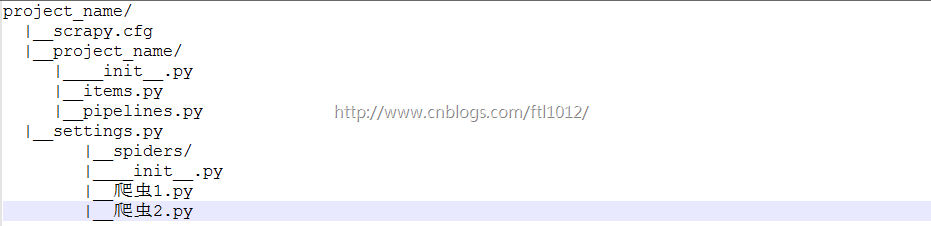
文件说明:
· scrapy.cfg 项目的主配置信息。(真正爬虫相关的配置信息在settings.py文件中)
· items.py 设置数据存储模板,用于结构化数据,如:Django的Model
· pipelines 数据处理行为,如:一般结构化的数据持久化
· settings.py 配置文件,如:递归的层数、并发数,延迟下载等
· spiders 爬虫目录,如:创建文件,编写爬虫规则
爬取笑话网
# -*- coding: utf-8 -*-
import scrapy
from scrapy.selector import HtmlXPathSelector
from scrapy.http import Request
class XiaohuarSpider(scrapy.Spider):
name = "xiaohuar"
allowed_domains = ["xiaohuar.com"]
start_urls = ['http://www.xiaohuar.com/list-1-0.html'] visited_set = set()
def parse(self, response):
self.visited_set.add(response.url)
# 1. 当前页面的所有校花爬下来
# 获取div并且属性为 class=item masonry_brick
hxs = HtmlXPathSelector(response)
item_list = hxs.select('//div[@class="item masonry_brick"]')
for item in item_list:
v = item.select('.//span[@class="price"]/text()').extract_first()
print(v) # 2. 在当前页中获取 http://www.xiaohuar.com/list-1-\d+.html,
# page_list = hxs.select('//a[@href="http://www.xiaohuar.com/list-1-1.html"]')
page_list = hxs.select('//a[re:test(@href,"http://www.xiaohuar.com/list-1-\d+.html")]/@href').extract()
for url in page_list:
if url in self.visited_set:
pass
else:
obj = Request(url=url,method='GET',callback=self.parse)
yield obj
view-source: http://www.521609.com/daxuexiaohua/

Django和scrapy框架的小对比
Django和scrapy框架的小对比
########## scrapy ##########
Django
django-admin startproject mysite # 创建Django工程
cd mysite
python3 namage.py startapp app01
python3 namage.py startapp app02
scrapy
scrapy startproject scy # 创建scrapy工程
cd scy
scrapy genspider chouti chouti.com
scrapy crawl 名字 --nolog
Python学习---爬虫学习[scrapy框架初识]的更多相关文章
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
- Python逆向爬虫之scrapy框架,非常详细
爬虫系列目录 目录 Python逆向爬虫之scrapy框架,非常详细 一.爬虫入门 1.1 定义需求 1.2 需求分析 1.2.1 下载某个页面上所有的图片 1.2.2 分页 1.2.3 进行下载图片 ...
- 16.Python网络爬虫之Scrapy框架(CrawlSpider)
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
- 16,Python网络爬虫之Scrapy框架(CrawlSpider)
今日概要 CrawlSpider简介 CrawlSpider使用 基于CrawlSpider爬虫文件的创建 链接提取器 规则解析器 引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话, ...
- Python分布式爬虫必学框架Scrapy打造搜索引擎
Python分布式爬虫必学框架Scrapy打造搜索引擎 部分课程截图: 点击链接或搜索QQ号直接加群获取其它资料: 链接:https://pan.baidu.com/s/1-wHr4dTAxfd51M ...
- Python分布式爬虫必学框架Scrapy打造搜索引擎 ✌✌
Python分布式爬虫必学框架Scrapy打造搜索引擎 ✌✌ (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 第1章 课程介绍 介绍课程目标.通过课程能学习到 ...
- Python分布式爬虫必学框架scrapy打造搜索引擎✍✍✍
Python分布式爬虫必学框架scrapy打造搜索引擎 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身 ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- 爬虫06 /scrapy框架
爬虫06 /scrapy框架 目录 爬虫06 /scrapy框架 1. scrapy概述/安装 2. 基本使用 1. 创建工程 2. 数据分析 3. 持久化存储 3. 全栈数据的爬取 4. 五大核心组 ...
随机推荐
- JBoss Web和Tomcat的区别
在Web2.0的时代,基于Tomcat内核的JBoss在J2EE应用服务器领域已成为发展最为迅速的应用服务器.这一青出于蓝而胜于蓝的产品与Tomcat的区别又在哪里? 基于Tomcat内核,青胜于蓝. ...
- 【LeetCode题解】160_相交链表
目录 160_相交链表 描述 解法一:哈希表 思路 Java 实现 Python 实现 解法二:双指针(推荐) 思路 Java 实现 Python 实现 160_相交链表 描述 编写一个程序,找到两个 ...
- 任务四十二:UI组件之日历组件(三)
任务四十二:UI组件之日历组件(三) 面向人群: 有一定基础的同学 难度: 困难 重要说明 百度前端技术学院的课程任务是由百度前端工程师专为对前端不同掌握程度的同学设计.我们尽力保证课程内容的质量以及 ...
- Ionic3 UI组件之 ImagePicker
ImagePicker插件实现设备上的多个图像选择的功能. 组件特性: 统一选择界面,避免不同设备选择界面不一样的问题: 支持多选,并且可以设置最多选择的张数: 选择数量超出设置时会提示: Camer ...
- 【转】从msql数据库处理高并发商品超卖
今天王总又给我们上了一课,其实mysql处理高并发,防止库存超卖的问题,在去年的时候,王总已经提过:但是很可惜,即使当时大家都听懂了,但是在现实开发中,还是没这方面的意识.今天就我的一些理解,整理一下 ...
- 【转】maven profile实现多环境打包
作为一名程序员,在开发的过程中,经常需要面对不同的运行环境(开发环境.测试环境.生产环境.内网环境.外网环境等等),在不同的环境中,相关的配置一般不一样,比如数据源配置.日志文件配置.以及一些软件运行 ...
- commons-fileupload-1.4使用及问题
文件上传 使用commons-fileupload-1.4控件及依赖的commons-io-2.6控件 jsp页面中内容 <form action="../servlet/FileUp ...
- Nginx面试
声明:此文章非本人所 原创,是别人分享所得,如有知道原作者是谁可以联系本人,如有转载请加上此段话 1.请解释一下什么是 Nginx? Nginx是一个 web服务器和反向代理服务器,用于 HTTP.H ...
- 高并发第十单:J.U.C AQS(AbstractQueuedSynchronizer) 组件:CountDownLatch. CyclicBarrier .Semaphore
这里有一篇介绍AQS的文章 非常好: Java并发之AQS详解 AQS全名:AbstractQueuedSynchronizer,是并发容器J.U.C(java.lang.concurrent)下lo ...
- 自动化构建工具--gulp的初识和使用
gulp 首先:什么是gulp? gulp是前端开发过程中对代码进行构建的工具,是自动化项目的构建利器:她不仅能对网站资源进行优化,而且在开发过程中很多重复的任务能够使用正确的工具自动完成:使用她,我 ...