Python学习---爬虫学习[scrapy框架初识]
Scrapy
Scrapy是一个框架,可以帮助我们进行创建项目,运行项目,可以帮我们下载,解析网页,同时支持cookies和自定义其他功能。
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
【更多参考】http://www.cnblogs.com/wupeiqi/articles/6229292.html
scrapy框架介绍以及安装
Linux
pip3 install scrapy
Windows
1. pip3 install wheel
1-1安装Twisted
a. http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted, 下载:Twisted-17.1.0-cp35-cp35m-win_amd64.whl
b. 进入文件所在目录
c. pip3 install Twisted-17.1.0-cp35-cp35m-win_amd64.whl
2. pip3 install scrapy
3. windows上scrapy依赖 https://sourceforge.net/projects/pywin32/files/
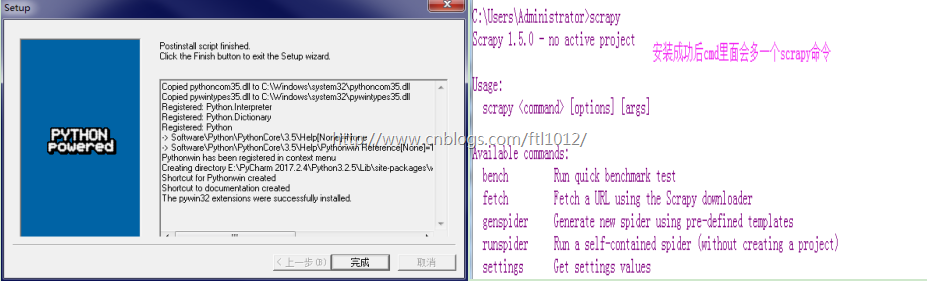
创建一个scrapy工程:
创建一个scrapy工程:
scrapy startproject scy
scrapy genspider baidu baidu.com

baidu.py里面的内容
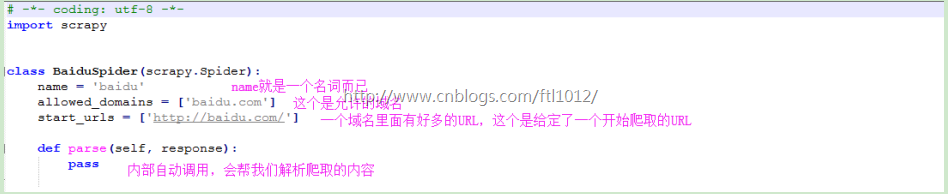
response.text可以打印具体的内容
scrapy crawl baidu
scrapy crawl baidu --nolog [不打印日志]

修改settting.py 让spider不去访问robot.txt文件

附: 查看spider文件的其他模板
scrapy genspider --list

项目结构以及爬虫应用简介
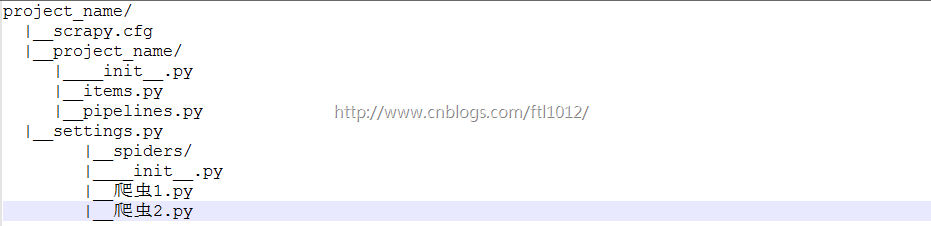
文件说明:
· scrapy.cfg 项目的主配置信息。(真正爬虫相关的配置信息在settings.py文件中)
· items.py 设置数据存储模板,用于结构化数据,如:Django的Model
· pipelines 数据处理行为,如:一般结构化的数据持久化
· settings.py 配置文件,如:递归的层数、并发数,延迟下载等
· spiders 爬虫目录,如:创建文件,编写爬虫规则
爬取笑话网
# -*- coding: utf-8 -*-
import scrapy
from scrapy.selector import HtmlXPathSelector
from scrapy.http import Request
class XiaohuarSpider(scrapy.Spider):
name = "xiaohuar"
allowed_domains = ["xiaohuar.com"]
start_urls = ['http://www.xiaohuar.com/list-1-0.html'] visited_set = set()
def parse(self, response):
self.visited_set.add(response.url)
# 1. 当前页面的所有校花爬下来
# 获取div并且属性为 class=item masonry_brick
hxs = HtmlXPathSelector(response)
item_list = hxs.select('//div[@class="item masonry_brick"]')
for item in item_list:
v = item.select('.//span[@class="price"]/text()').extract_first()
print(v) # 2. 在当前页中获取 http://www.xiaohuar.com/list-1-\d+.html,
# page_list = hxs.select('//a[@href="http://www.xiaohuar.com/list-1-1.html"]')
page_list = hxs.select('//a[re:test(@href,"http://www.xiaohuar.com/list-1-\d+.html")]/@href').extract()
for url in page_list:
if url in self.visited_set:
pass
else:
obj = Request(url=url,method='GET',callback=self.parse)
yield obj
view-source: http://www.521609.com/daxuexiaohua/

Django和scrapy框架的小对比
Django和scrapy框架的小对比
########## scrapy ##########
Django
django-admin startproject mysite # 创建Django工程
cd mysite
python3 namage.py startapp app01
python3 namage.py startapp app02
scrapy
scrapy startproject scy # 创建scrapy工程
cd scy
scrapy genspider chouti chouti.com
scrapy crawl 名字 --nolog
Python学习---爬虫学习[scrapy框架初识]的更多相关文章
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
- Python逆向爬虫之scrapy框架,非常详细
爬虫系列目录 目录 Python逆向爬虫之scrapy框架,非常详细 一.爬虫入门 1.1 定义需求 1.2 需求分析 1.2.1 下载某个页面上所有的图片 1.2.2 分页 1.2.3 进行下载图片 ...
- 16.Python网络爬虫之Scrapy框架(CrawlSpider)
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
- 16,Python网络爬虫之Scrapy框架(CrawlSpider)
今日概要 CrawlSpider简介 CrawlSpider使用 基于CrawlSpider爬虫文件的创建 链接提取器 规则解析器 引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话, ...
- Python分布式爬虫必学框架Scrapy打造搜索引擎
Python分布式爬虫必学框架Scrapy打造搜索引擎 部分课程截图: 点击链接或搜索QQ号直接加群获取其它资料: 链接:https://pan.baidu.com/s/1-wHr4dTAxfd51M ...
- Python分布式爬虫必学框架Scrapy打造搜索引擎 ✌✌
Python分布式爬虫必学框架Scrapy打造搜索引擎 ✌✌ (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 第1章 课程介绍 介绍课程目标.通过课程能学习到 ...
- Python分布式爬虫必学框架scrapy打造搜索引擎✍✍✍
Python分布式爬虫必学框架scrapy打造搜索引擎 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身 ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- 爬虫06 /scrapy框架
爬虫06 /scrapy框架 目录 爬虫06 /scrapy框架 1. scrapy概述/安装 2. 基本使用 1. 创建工程 2. 数据分析 3. 持久化存储 3. 全栈数据的爬取 4. 五大核心组 ...
随机推荐
- Linux的用户(组),权限,文件精妙的三角关系,和强大的帮助系统
在linux中一切都是文件(文件夹和硬件外设是特殊的文件),如果有可能尽量使用文本文件.文本文件是人和机器能理解的文件,也成为人和机器进行 交流的最好途径.由于所有的配置文件都是文本,所以你只需要一个 ...
- java面试⑦高级部分
2.6.2说一下Linux下面的一些常用命令 常用: pwd 获取当前路径 cd 跳转到目录 su -u 切换到管理员 ls 列举目录 文件操作命令: 文件 tail 查看 rm -rf 删除 vim ...
- Hdfs数据备份
Hdfs数据备份 一.概述 本文的hdfs数据备份是在两个集群之间进行的,如果使用snapshot在同一个集群上做备份,如果datanode损坏或误操作清空了数据,这样的备份就无法完全保证数据安全性. ...
- C#学习之文件操作
1 DirectoryInfo 类介绍 DirectoryInfo 类在 .net 开发中主要用于创建.移动和枚举目录和子目录的实例方法,此类不能被继承. 从事 .net 软件开发的同事对 Dir ...
- [C语言] 数据结构-预备知识动态内存分配
动态内存分配 静态内存分配数组 int a[5]={1,2,3,4,5} 动态内存分配数组 int len=5; int *parr=(int *)malloc(sizeof(int) * len) ...
- Java使用Redisson分布式锁实现原理
本篇文章摘自:https://www.jb51.net/article/149353.htm 由于时间有限,暂未验证 仅先做记录.有大家注意下哈(会尽快抽时间进行验证) 1. 基本用法 添加依赖 &l ...
- 各种IDE的使用
sharpdevelop http://blog.sina.com.cn/s/blog_d1001bff0101di7p.html
- wcf远程服务器返回错误404
最近根据quartz.net 和wcf做资讯内容定时推送,wcf调用的时候出现远程服务器返回错误404,一直找不到原因是什么,客户端和服务器地址和配置都没啥问题,最后发现wcf请求数据,有传输大小限制 ...
- 最简单的socket通信
服务器端程序 import socket # 套接字 sk = socket.socket() # 先买一部手机 # sk.bind(('192.168.13.2',9000)) # 绑定一个电话卡 ...
- 移动web模拟客户端实现多方框输入密码效果
不知道怎么描述标题,先看截图吧,大致的效果就是一个框输入一位密码. 最开始实现的思路是一个小方框就是一个type为password的input,每输入一位自动跳到下一位,删除一位就自动跳到前一位,an ...