scrapy的安装,scrapy创建项目
简要:

scrapy的安装
# 1)pip install scrapy -i https://pypi.douban.com/simple(国内源)

一步到位

# 2) 报错1: building 'twisted.test.raiser' extension
# error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++
# Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools
# 解决1
# http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
# Twisted‑20.3.0‑cp37‑cp37m‑win_amd64.whl
# cp是你的python版本
# amd是你的操作系统的版本

# 下载完成之后 使用pip install twisted的路径 安装
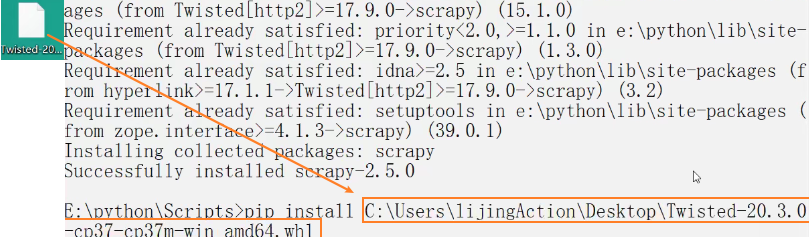
# 切记安装完twisted 再次安装scrapy
pip install scrapy -i https://pypi.douban.com/simple
# 3) 报错2:提示python -m pip install --upgrade pip
# 解决2 运行python -m pip install --upgrade pip
# 4) 报错3 win32的错误
# 解决3 pip install pypiwin32
# 5)使用 anaconda




scrapy创建项目
cmd 到项目文件夹中


或者直接拖入
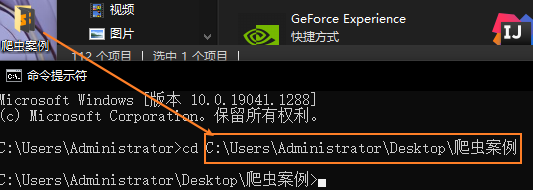
如果返回没有权限,使用管理员运行cmd
scrapy startproject scrapy_baidu
scrapy_baidu\下的文件夹


settings.py

spiders\baidu.py
import scrapy class BaiduSpider(scrapy.Spider):
# 爬虫的名字 用于运行爬虫的时候 使用的值
name = 'baidu'
# 允许访问的域名
allowed_domains = ['http://www.baidu.com']
# 起始的url地址 指的是第一次要访问的域名
# start_urls 是在allowed_domains的前面添加一个http://
# 在 allowed_domains的后面添加一个/
start_urls = ['http://www.baidu.com/'] # 是执行了start_urls之后 执行的方法 方法中的response 就是返回的那个对象
# 相当于 response = urllib.request.urlopen()
# response = requests.get()
def parse(self, response):
print('你好世界')
scrapy的安装,scrapy创建项目的更多相关文章
- C++框架_之Qt的开始部分_概述_安装_创建项目_快捷键等一系列注意细节
C++框架_之Qt的开始部分_概述_安装_创建项目_快捷键等一系列注意细节 1.Qt概述 1.1 什么是Qt Qt是一个跨平台的C++图形用户界面应用程序框架.它为应用程序开发者提供建立艺术级图形界面 ...
- Django在Win7下安装与创建项目hello word示例
Django在Win7下的安装及创建项目hello word的例子 有关python 的django 框架安装与开发的小例子.Django在Win7下的安装及创建项目hello word.1.安装:命 ...
- mac下配置Node.js开发环境、express安装、创建项目
mac下配置Node.js开发环境.express安装.创建项目 一.node.js的安装 去官网下载对应的平台版本就可以了,https://nodejs.org 二.express安装 sudo n ...
- Webpack指南(一):安装,创建项目,配置文件,开发环境以及问题汇总
Webpack是一个现代 JavaScript 应用程序的静态模块打包器(module bundler).当 webpack 处理应用程序时,它会递归地构建一个依赖关系图(dependency gra ...
- vue-cli 3.0 安装和创建项目流程
使用前我们先了解下3.0较2.0有哪些区别 一.3.0 新加入了 TypeScript 以及 PWA 的支持二.部分命令发生了变化: 1.下载安装 npm install -g vue@cli 2. ...
- vue安装及创建项目的几种方式
原文地址:https://www.wjcms.net/archives/vue安装及创建项目的几种方式 VUE安装的方式 直接用 script标签 引入 对于制作原型或学习,你可以这样使用最新版本: ...
- python爬虫框架—Scrapy安装及创建项目
linux版本安装 pip3 install scrapy 安装完成 windows版本安装 pip install wheel 下载twisted,网址:http://www.lfd.uci.edu ...
- scrapy框架安装及创建
介绍:大而全的爬虫组件 使用Anaconda conda install -c conda-forge scrapy 一.安装: windows 1.下载 https://www.lfd.uci.ed ...
- Maven入门学习,安装及创建项目
一.maven介绍: 1.maven是一个基于项目对象模型(POM Project Object Model),通过配置文件管理项目的工具(项目管理工具). 2.maven主要功能:发布项目(从编译到 ...
- [Scrapy] Mac安装Scrapy
Mac安装Scrapy Mac版本 10.11 El Captain. 前一段想在Mac上用Scrapy,各种问题.有一个不错的工具:Anaconda. 安装Anaconda 下载地址 我还是下pyt ...
随机推荐
- 从0到1使用Kubernetes系列——Kubernetes入门
基本概念 Docker 是什么 Docker 起初是 dotCloud 公司创始人 Solomon Hykes 在法国的时候发起的一项公司内部项目,Docker 是基于 dotCloud 公司多年云服 ...
- 极简SpringBoot指南-Chapter00-学习SpringBoot前的基本知识
仓库地址 w4ngzhen/springboot-simple-guide: This is a project that guides SpringBoot users to get started ...
- 生日礼物网页Javascript版本与锚点版本
<style> #dv1{ width:60px; height:36px; margin:0 auto; background-color:orange; display:none; } ...
- 串的模式匹配 BF算法和KMP算法
设有主串s和子串t,子串t的定位就是要在主串中找到一个与子串t相等的子串.通常把主串s称为目标串,把子串t称为模式串,因此定位也称为模式匹配. 模式匹配成功是指在目标串s中找到一个模式串t: 不成功则 ...
- Java(13)详解构造方法
作者:季沐测试笔记 原文地址:https://www.cnblogs.com/testero/p/15201600.html 博客主页:https://www.cnblogs.com/testero ...
- 如何在印刷品中使用遵循SIL Open Font License协议的字体
如何在印刷品中使用遵循SIL Open Font License协议的字体 昨天在知乎看到了一个问题,( 如何在设计中声明字体开源许可证? - 知乎 (zhihu.com),恰好最近在研究一些开源协议 ...
- javascript-jquery对象的事件处理
一.页面加载 1.页面加载顺序:先加载<head></head>之间的内容,然后加载<body></body>之间的内容 直接在head之间书写jque ...
- javascript的变量及数据类型
1.变量的概念 变量是储存数据的内存空间 2.变量的命名规则 js变量的命名规则如下:以字母或者下划线开头可以包含字母.数字.下划线,不能包含特殊字符 3.变量的创建及初始化方法 方法一:先创建后使用 ...
- ThreadLocal部分源码分析
结构演进 早起JDK版本中,ThreadLocal内部结构是一个Map,线程为key,线程在"线程本地变量"中绑定的值为Value.每一个ThreadLocal实例拥有一个Map实 ...
- 【c++ Prime 学习笔记】第3章 字符串、向量和数组
string和vector是两类最重要的标准库类型 strng表示可变长的字符序列 vector存放某种给定类型对象的可变长序列. 3.1 命名空间的using声明 using namespace:: ...