scrapy的安装,scrapy创建项目
简要:

scrapy的安装
# 1)pip install scrapy -i https://pypi.douban.com/simple(国内源)

一步到位

# 2) 报错1: building 'twisted.test.raiser' extension
# error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++
# Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools
# 解决1
# http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
# Twisted‑20.3.0‑cp37‑cp37m‑win_amd64.whl
# cp是你的python版本
# amd是你的操作系统的版本

# 下载完成之后 使用pip install twisted的路径 安装
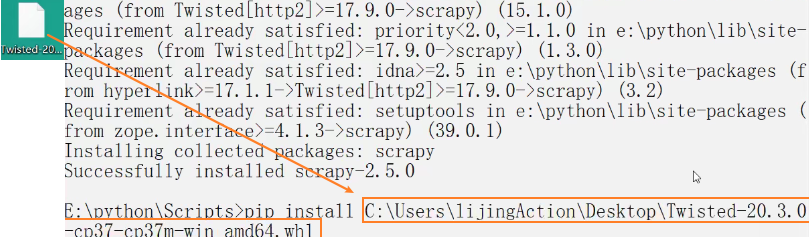
# 切记安装完twisted 再次安装scrapy
pip install scrapy -i https://pypi.douban.com/simple
# 3) 报错2:提示python -m pip install --upgrade pip
# 解决2 运行python -m pip install --upgrade pip
# 4) 报错3 win32的错误
# 解决3 pip install pypiwin32
# 5)使用 anaconda



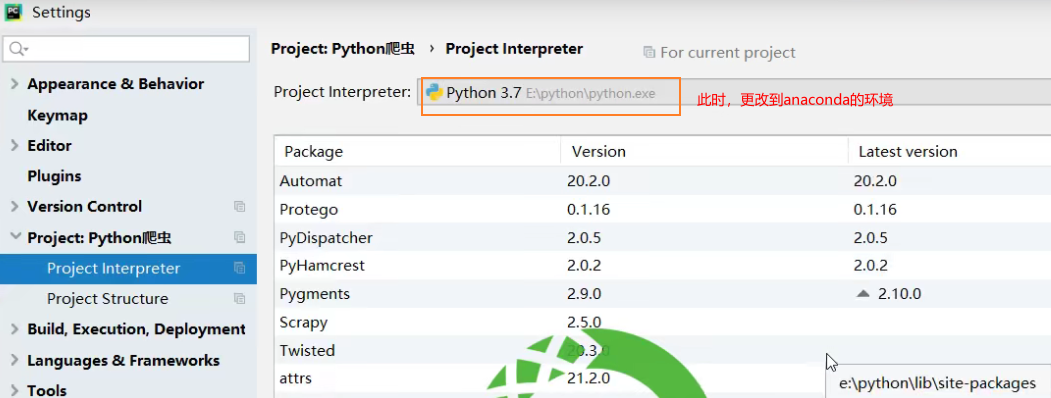

scrapy创建项目
cmd 到项目文件夹中


或者直接拖入
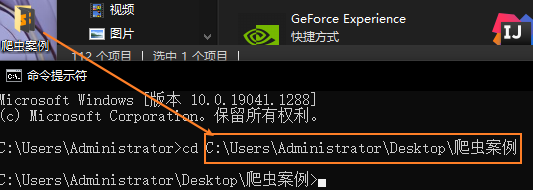
如果返回没有权限,使用管理员运行cmd
scrapy startproject scrapy_baidu
scrapy_baidu\下的文件夹


settings.py

spiders\baidu.py
import scrapy class BaiduSpider(scrapy.Spider):
# 爬虫的名字 用于运行爬虫的时候 使用的值
name = 'baidu'
# 允许访问的域名
allowed_domains = ['http://www.baidu.com']
# 起始的url地址 指的是第一次要访问的域名
# start_urls 是在allowed_domains的前面添加一个http://
# 在 allowed_domains的后面添加一个/
start_urls = ['http://www.baidu.com/'] # 是执行了start_urls之后 执行的方法 方法中的response 就是返回的那个对象
# 相当于 response = urllib.request.urlopen()
# response = requests.get()
def parse(self, response):
print('你好世界')
scrapy的安装,scrapy创建项目的更多相关文章
- C++框架_之Qt的开始部分_概述_安装_创建项目_快捷键等一系列注意细节
C++框架_之Qt的开始部分_概述_安装_创建项目_快捷键等一系列注意细节 1.Qt概述 1.1 什么是Qt Qt是一个跨平台的C++图形用户界面应用程序框架.它为应用程序开发者提供建立艺术级图形界面 ...
- Django在Win7下安装与创建项目hello word示例
Django在Win7下的安装及创建项目hello word的例子 有关python 的django 框架安装与开发的小例子.Django在Win7下的安装及创建项目hello word.1.安装:命 ...
- mac下配置Node.js开发环境、express安装、创建项目
mac下配置Node.js开发环境.express安装.创建项目 一.node.js的安装 去官网下载对应的平台版本就可以了,https://nodejs.org 二.express安装 sudo n ...
- Webpack指南(一):安装,创建项目,配置文件,开发环境以及问题汇总
Webpack是一个现代 JavaScript 应用程序的静态模块打包器(module bundler).当 webpack 处理应用程序时,它会递归地构建一个依赖关系图(dependency gra ...
- vue-cli 3.0 安装和创建项目流程
使用前我们先了解下3.0较2.0有哪些区别 一.3.0 新加入了 TypeScript 以及 PWA 的支持二.部分命令发生了变化: 1.下载安装 npm install -g vue@cli 2. ...
- vue安装及创建项目的几种方式
原文地址:https://www.wjcms.net/archives/vue安装及创建项目的几种方式 VUE安装的方式 直接用 script标签 引入 对于制作原型或学习,你可以这样使用最新版本: ...
- python爬虫框架—Scrapy安装及创建项目
linux版本安装 pip3 install scrapy 安装完成 windows版本安装 pip install wheel 下载twisted,网址:http://www.lfd.uci.edu ...
- scrapy框架安装及创建
介绍:大而全的爬虫组件 使用Anaconda conda install -c conda-forge scrapy 一.安装: windows 1.下载 https://www.lfd.uci.ed ...
- Maven入门学习,安装及创建项目
一.maven介绍: 1.maven是一个基于项目对象模型(POM Project Object Model),通过配置文件管理项目的工具(项目管理工具). 2.maven主要功能:发布项目(从编译到 ...
- [Scrapy] Mac安装Scrapy
Mac安装Scrapy Mac版本 10.11 El Captain. 前一段想在Mac上用Scrapy,各种问题.有一个不错的工具:Anaconda. 安装Anaconda 下载地址 我还是下pyt ...
随机推荐
- Java程序的种类
Java程序的种类 Application:Java应用程序,是可以由Java解释器直接运行的程序. Applet:即Java小应用程序,是可随网页下载到客户端由浏览器解释执行的Java程序. Ser ...
- 阿里云函数计算发布新功能,支持容器镜像,加速应用 Serverless 进程
我们先通过一段视频来看看函数计算和容器相结合后,在视频转码场景下的优秀表现.点击观看视频 >> FaaS 的门槛 Serverless 形态的云服务帮助开发者承担了大量复杂的扩缩容.运维. ...
- ls命令剖析
目录 ls命令剖析 资料翻译 SYNOPSIS 使用方式 DESCRIPTION 说明 参数的说明 -l 参数字符的解释 文件权限的解释 FILES 文件夹 实战演练 ls 命令 ls -l 命令 l ...
- SpringBoot-MVC自动配置原理
SpringBoot对SpringMVC做了哪些配置,如何扩展,如何定制? 文档地址 :https://docs.spring.io/spring-boot/docs/2.2.5.RELEASE/re ...
- Windows内核开发-10-监听对象
Windows内核开发-10-监听对象 Windows内核除了可以监听进程,线程.dll还可以监听特定的对象和注册表.这里先讲一下监听对象. 监听对象 内核提供了一种可以监听对特定的对象类型的句柄进行 ...
- Sequence Model-week3编程题2-Trigger Word Detection
1. Trigger Word Detection 我们的触发词将是 "Activate.".每当它听到你说 "Activate.",它就会发出 "c ...
- UltraSoft - Alpha - Scrum Meeting 6
Date: Apr 21th, 2020. Scrum 情况汇报 进度情况 组员 负责 昨日进度 后两日任务 CookieLau PM 验证了课程中心获取课程资源和作业的爬虫方式 细化前后端交互中的难 ...
- 团队任务拆解(alpha)
团队任务拆解(alpha阶段) 项目 内容 班级:2020春季计算机学院软件工程(罗杰 任健) 博客园班级博客 作业:团队任务拆解 团队任务拆解 我们在这个课程中的目标 写出令客户和自己都满意的代码同 ...
- 洛谷 P4867 Gty的二逼妹子序列
链接: P4867 题意: 给出长度为 \(n(1\leq n\leq 10^5)\) 的序列 \(s\),保证\(1\leq s_i\leq n\).有 \(m(1\leq m\leq 10^6)\ ...
- CSP-S 2021 退役记
写的比较草率,但的确是真实感受. 10.23 回寝室前敲了一个 dinic 板子,觉得不会考... 10.24 8:00 起床,还好今天宿管不在,可以起的晚一点. 吃了早饭来机房颓废. 10:00 似 ...