[炼丹术]使用Pytorch搭建模型的步骤及教程
使用Pytorch搭建模型的步骤及教程
我们知道,模型有一个特定的生命周期,了解这个为数据集建模和理解 PyTorch API 提供了指导方向。我们可以根据生命周期的每一个步骤进行设计和优化,同时更加方便调整各种细节。
模型的生命周期的五个步骤如下:
- 1.准备数据
- 2.定义模型
- 3.训练模型
- 4.评估模型
- 5.进行预测
注意:使用 PyTorch API 有很多方法可以实现这些步骤中的每一个,下面是一些使用Pytorch API最简单、最常见或最惯用的方法。
一、准备数据
第一步是加载和准备数据。
神经网络模型需要数值输入数据和数值输出数据。
您可以使用标准 Python 库来加载和准备表格数据,例如 CSV 文件。例如,Pandas 可用于加载 CSV 文件,scikit-learn 中的工具可用于编码分类数据,例如类标签。
PyTorch 提供了Dataset 类,您可以对其进行扩展和自定义以加载数据集。
例如,您的数据集对象的构造函数可以加载您的数据文件(例如 CSV 文件)。然后可以覆盖__len __()可以被用于获取数据集(行或样本数)的长度函数和__getitem __() ,其用于获得由索引的特定示例函数。
加载数据集时,您还可以执行任何所需的转换,例如缩放或编码。
下面提供了自定义数据集类的骨架。
# dataset definition
class CSVDataset(Dataset):
# load the dataset
def __init__(self, path):
# store the inputs and outputs
self.X = ...
self.y = ...
# number of rows in the dataset
def __len__(self):
return len(self.X)
# get a row at an index
def __getitem__(self, idx):
return [self.X[idx], self.y[idx]]
加载后,PyTorch 提供DataLoader 类以在模型的训练和评估期间导航Dataset实例。
可以为训练数据集、测试数据集甚至验证数据集创建一个DataLoader实例。
所述random_split()函数可以被用于将数据集分裂成训练集和测试集。拆分后,可以将数据集中的行选择提供给 DataLoader,同时提供批量大小以及是否应在每个 epoch 中对数据进行混洗。
random_split(dataset, lengths)
返回从原始数据集随机拆分的 n 个非重叠数据集。lengths 参数指定每个拆分的长度。
例如,我们可以通过传入数据集中的选定行样本来定义DataLoader。
DataLoader(dataset, batch_size=1, shuffle=False)
返回给定数据集的迭代,每批具有指定数量的样本。该函数还有许多其他参数。
shuffle参数设置为“True”,以便在每个epoch之后对数据进行shuffled。这对于验证和测试数据集是不必要的,因为我们将只对它们进行评估,而顺序并不重要。
...
# create the dataset
dataset = CSVDataset(...)
# select rows from the dataset
train, test = random_split(dataset, [[...], [...]])
# create a data loader for train and test sets
train_dl = DataLoader(train, batch_size=32, shuffle=True)
test_dl = DataLoader(test, batch_size=1024, shuffle=False)
定义后,可以枚举DataLoader,每次迭代产生一批样本。
# train the model
for i, (inputs, targets) in enumerate(train_dl):
...
二、定义模型
下一步是定义模型。
在 PyTorch 中定义模型的习惯用法涉及定义一个扩展Module 类的类。
nn.Module 是为所有神经网络模型扩展的基类。我们定义的模型有四个功能
1.__ init __(self)
该函数调用超类的构造函数。这是强制性的。
此处使用 torch.nn 库定义了该模型的不同层。层的类型和数量特定于手头的问题。它可以是单层线性模型,也可以是基于复杂数学模型的多层。
还声明了每一层的输入和输出大小以及其他必需的参数。每层的大小和其他值可以作为构造函数中的参数进行检索,从而允许模型实例具有可变架构或硬编码。
2.forward(self, x)
此函数定义数据如何通过一次前向传递。可以从 torch.nn.functional 库定义不同层的激活函数。
3.training_step(self,batch)
在这个函数中,我们定义了模型的一个训练步骤,该步骤接收一批数据并返回损失。
对于给定的批次,我们将输入和目标分开,这里是图像及其标签。输入通过使用“ self ”关键字调用的 forward 函数传递,以获得输出。
将适当的损失函数应用于输出和目标以计算损失。
4.validation_step(self,batch)
在这个函数中,我们定义了一个验证步骤,即我们评估当前状态的模型。
给定批次的损失是按照上面的 training_step() 函数中的描述计算的。除此之外,还可以评估其他几个指标,例如准确度、auc、精确度、召回率等等。
这些指标的结果用于评估模型的性能,而不是用于训练过程。因此,我们将.detach()应用于结果以将它们从梯度计算中排除。
对来自 DataLoader 对象的每批数据调用模型的 validation_step() 函数。输出列表可以看作是一个二维数组,每一行对应一个批次,每一行按顺序保存损失和 n 个度量的值。
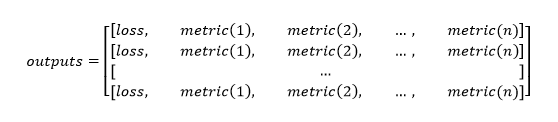
它的转置如下:

这使得使用 torch.mean() 函数更容易计算平均损失和其他指标。.item() 函数用于返回数值而不是单值张量。
fit拟合函数
fit 函数接受许多参数,其中一个是默认优化函数。创建了优化器的一个实例。在每个epoch:
- 每一批训练集都经过模型的training_step()函数得到loss。
- 梯度是使用 .backward() 函数计算的。
- 优化器根据梯度更新权重和偏差。
- 梯度值被重置为 0,这样它们就不会在 epoch 上累积。
- 在训练阶段结束时,将评估验证集并将结果附加到历史记录中。
你的类的构造函数定义了模型的层,而 forward() 函数是定义如何通过模型的定义层向前传播输入的覆盖。
此外,Pytorch Module还有许多网络层级可用,例如Linear用于全连接层,Conv2d用于卷积层,MaxPool2d用于池化层。
激活函数也可以定义为层,例如ReLU、Softmax和Sigmoid。
下面是一个具有一层的简单 MLP 模型的示例。
# model definition
class MLP(Module):
# define model elements
def __init__(self, n_inputs):
super(MLP, self).__init__()
self.layer = Linear(n_inputs, 1)
self.activation = Sigmoid()
# forward propagate input
def forward(self, X):
X = self.layer(X)
X = self.activation(X)
return X
给定层的权重也可以在构造函数中定义层后初始化。
...
xavier_uniform_(self.layer.weight)
三、训练模型
训练过程要求您定义损失函数和优化算法。
常见的损失函数包括:
- BCELoss:二元分类的二元交叉熵损失。
- CrossEntropyLoss:多类分类的分类交叉熵损失。
- MSELoss:回归的均方损失。
有关损失函数的更多信息,请参阅教程:
使用随机梯度下降进行优化,标准算法由SGD 类提供,尽管该算法的其他版本也可用,例如Adam。
# define the optimization
criterion = MSELoss()
optimizer = SGD(model.parameters(), lr=0.01, momentum=0.9)
训练模型涉及枚举训练数据集的DataLoader。
首先,训练时期的数量需要一个循环。然后,随机梯度下降的小批量需要一个内循环。
...
# enumerate epochs
for epoch in range(100):
# enumerate mini batches
for i, (inputs, targets) in enumerate(train_dl):
...
模型的每次更新都涉及相同的一般模式,包括:
- 清除最后一个误差梯度。
- 输入通过模型的前向传递。
- 计算模型输出的损失。
- 通过模型反向传播错误。
- 更新模型以减少损失。
...
# clear the gradients
optimizer.zero_grad()
# compute the model output
yhat = model(inputs)
# calculate loss
loss = criterion(yhat, targets)
# credit assignment
loss.backward()
# update model weights
optimizer.step()
四、评估模型
一旦模型拟合好,就可以在测试数据集上对其进行评估。
这可以通过将DataLoader用于测试数据集并收集测试集的预测,然后将预测与测试集的预期值进行比较并计算性能指标来实现。
...
for i, (inputs, targets) in enumerate(test_dl):
# evaluate the model on the test set
yhat = model(inputs)
...
五、进行预测
拟合模型可用于对新数据进行预测。
例如,您可能有一张图像或一行数据,并且想要进行预测。
这要求您将数据包装在PyTorch Tensor数据结构中。
Tensor只是用于保存数据的 NumPy 数组的 PyTorch 版本。它还允许您在模型图中执行自动微分任务,例如在训练模型时调用Backward()。
预测也将是一个Tensor,尽管您可以通过从自动微分图中分离张量并调用 NumPy 函数来检索 NumPy 数组。
...
# convert row to data
row = Variable(Tensor([row]).float())
# make prediction
yhat = model(row)
# retrieve numpy array
yhat = yhat.detach().numpy()
[炼丹术]使用Pytorch搭建模型的步骤及教程的更多相关文章
- 使用Pytorch搭建模型
本来是只用Tenorflow的,但是因为TF有些Numpy特性并不支持,比如对数组使用列表进行切片,所以只能转战Pytorch了(pytorch是支持的).还好Pytorch比较容易上手,几乎完美复制 ...
- 目标检测-基于Pytorch实现Yolov3(1)- 搭建模型
原文地址:https://www.cnblogs.com/jacklu/p/9853599.html 本人前段时间在T厂做了目标检测的项目,对一些目标检测框架也有了一定理解.其中Yolov3速度非常快 ...
- pytorch(11)模型创建步骤与nn.Module
模型创建与nn.Module 网络模型创建步骤 nn.Module graph LR 模型 --> 模型创建 模型创建 --> 构建网络层 构建网络层 --> id[卷积层,池化层, ...
- 一文弄懂pytorch搭建网络流程+多分类评价指标
讲在前面,本来想通过一个简单的多层感知机实验一下不同的优化方法的,结果写着写着就先研究起评价指标来了,之前也写过一篇:https://www.cnblogs.com/xiximayou/p/13700 ...
- Pytorch线性规划模型 学习笔记(一)
Pytorch线性规划模型 学习笔记(一) Pytorch视频学习资料参考:<PyTorch深度学习实践>完结合集 Pytorch搭建神经网络的四大部分 1. 准备数据 Prepare d ...
- ssh框架搭建的基本步骤(以及各部分作用)
ssh框架搭建的基本步骤(以及各部分作用) 一.首先,明确spring,struts,hibernate在环境中各自的作用. struts: 用来响应用户的action,对应到相应的类进行 ...
- pytorch搭建简单网络
pytorch搭建一个简单神经网络 import torch import torch.nn as nn # 定义数据 # x:输入数据 # y:标签 x = torch.Tensor([[0.2, ...
- 搭建ssm的步骤
搭建SSM的步骤 ----------------------------- 1.创建web工程 2.把SSM做需要的所有jar导入工程中 3.web.xml 1.Springmvc的前端控制器,如果 ...
- 测试那些事儿—Linux搭建环境基础步骤
Linux搭建环境基础步骤 准备工具:SecureCRT工具(Linux工具,连接服务器)FTP传输工具(上传文件到服务器)MySQL连接工具 安装包(以下文件均为压缩包rpm格式和tar.gz):J ...
随机推荐
- Spark相关知识点(一)
spark工作机制,哪些角色,作用. spark yarn模式下的cluster模式和client模式有什么区别.
- css通配样式初始化(多款,供君自选)
腾讯官网 body,ol,ul,h1,h2,h3,h4,h5,h6,p,th,td,dl,dd,form,fieldset,legend,input,textarea,select{margin:0; ...
- Linux学习 - 变量测试与内容替换
变量置换方式 变量y没有设置 变量y为空 变量y有值 x=${y-新值} x=新值 x空 x=$y x=${y:-新值} x=新值 x=新值 x=$y x=${y+新值} x空 x=新值 x=新值 x ...
- Output of C++ Program | Set 9
Predict the output of following C++ programs. Question 1 1 template <class S, class T> class P ...
- transient关键字和volatile关键字
看到HashSet的源代码的时候,有一个关键字不太认识它..transient,百度整理之: Java的Serialization提供了一种持久化对象实例的机制,当持久化对象时,可能有一些特殊的对象数 ...
- DOM解析xml学习笔记
一.dom解析xml的优缺点 由于DOM的解析方式是将整个xml文件加载到内存中,转化为DOM树,因此程序可以访问DOM树的任何数据. 优点:灵活性强,速度快. 缺点:如果xml文件比较大比较复杂会占 ...
- 学习Oracle遇到的实际问题(持续更新)
有三个用户参与这个事情: system用户,拥有表manager. sys create了一个用户item,并赋予权限: SQL> GRANT SELECT ON SYSTEM.MANAGER ...
- 【Java 8】函数式接口(一)—— Functional Interface简介
什么是函数式接口(Functional Interface) 其实之前在讲Lambda表达式的时候提到过,所谓的函数式接口,当然首先是一个接口,然后就是在这个接口里面只能有一个抽象方法. 这种类型的接 ...
- 注解开发中的@Results注解使用
package com.hope.dao;import com.hope.domain.User;import com.sun.xml.internal.bind.v2.model.core.ID;i ...
- 【Jenkins系列】-备份机制
Jenkins是主从模式,从节点可以做集群.负载,从而实现从节点的高可用,但是主节点是单节点,一旦主节点宕机,会导致Jenkins服务不可用.Jenkins主节点本身是不支持集群的,需要通过其他变通方 ...