kubernetes常见日志采集问题和解决方案分析
传统日志与kubernetes日志对比


- 传统服务
- 目录固定
- 重启不会丢失
- 不用关注标准与错误日志输出
- 容器服务
- 节点不固定
- 重启服务会漂移
- 需要关注标准与错误日志输出
- 日志文件重启会丢失
- 日志目录不固定
k8s中的日志处理
常见日志采集方案:


1.远程日志 将容器中日志直接写入远程kafka、es等,再由logstash等处理。劣势就是需要改造服务由写入本地的就要进行修改 传输到远端存储。
2.sidecar模式,在每个pod中运行一个filebeat,logstash等pod共享一个valume,由采集工具将日志内容采集发送。缺点每个pod都需要额外增加一个日志采集工具,对pod有侵入。
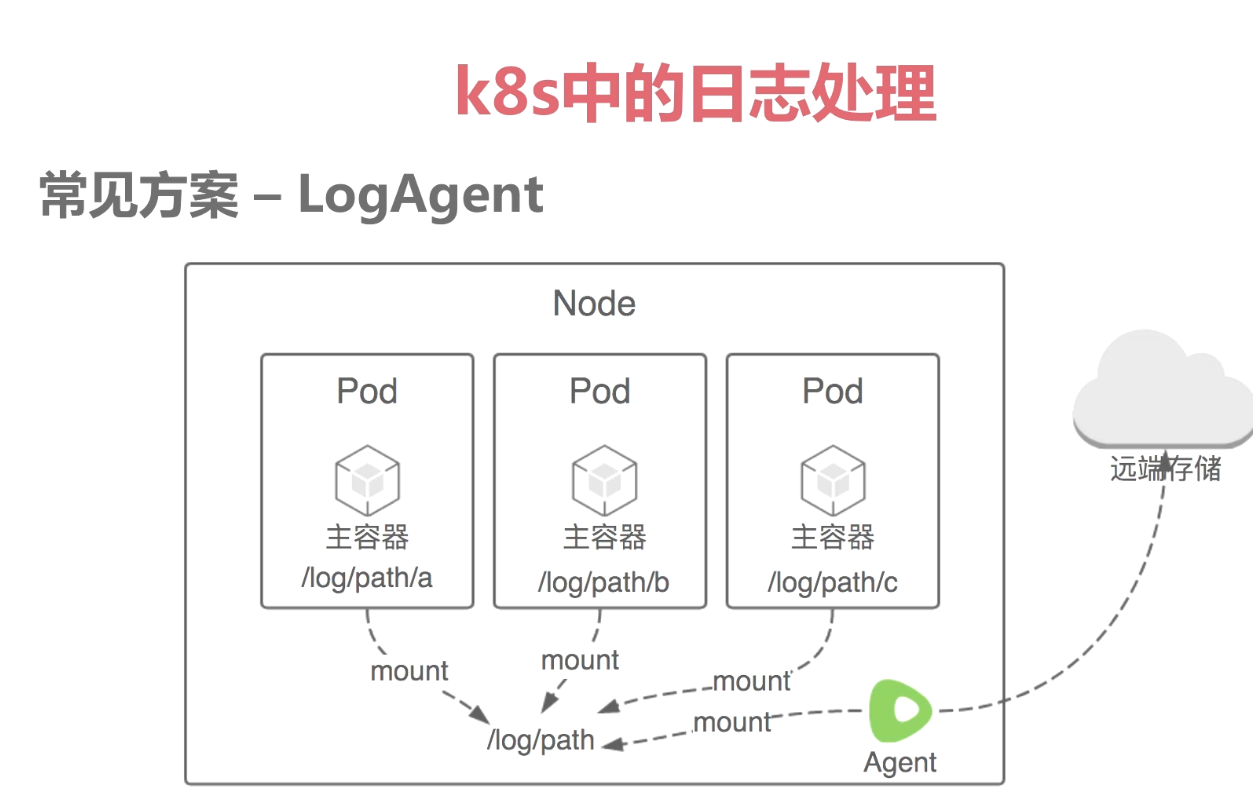
3.logagent模式,在node中运行一个filebeat,logstash等,通过将pod日志目录固定事先约定好,直接采集对应目录内容传输至远端。优点节约资源,对pod无侵入。缺点:文件后缀名尽量统一否则维护较为困难。目录预先定义好无法判断来源于哪个pod,只能区分node。
实践:

采用logagent模式
日志采集工具使用阿里开源logpilot(优点与docker主进程进行交互能够通过docker动态识别各个pod日志目录,底层采用filebeat)
常见日志采集工具 logpilot filebeat logstash Fluentd Logtail Flume(filebeat与flentd在容器环境中应用最多)缺点:都是采集监测静态目录。

搭建es:


---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-api
namespace: kube-system
labels:
name: elasticsearch
spec:
selector:
app: es
ports:
- name: transport
port: 9200
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-discovery
namespace: kube-system
labels:
name: elasticsearch
spec:
selector:
app: es
ports:
- name: transport
port: 9300
protocol: TCP
---
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: elasticsearch
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
spec:
replicas: 3
serviceName: "elasticsearch-service"
selector:
matchLabels:
app: es
template:
metadata:
labels:
app: es
spec:
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
serviceAccountName: dashboard-admin
initContainers:
- name: init-sysctl
image: busybox:1.27
command:
- sysctl
- -w
- vm.max_map_count=262144
securityContext:
privileged: true
containers:
- name: elasticsearch
image: registry.cn-hangzhou.aliyuncs.com/imooc/elasticsearch:5.5.1
ports:
- containerPort: 9200
protocol: TCP
- containerPort: 9300
protocol: TCP
securityContext:
capabilities:
add:
- IPC_LOCK
- SYS_RESOURCE
resources:
limits:
memory: 4000Mi
requests:
cpu: 100m
memory: 2000Mi
env:
- name: "http.host"
value: "0.0.0.0"
- name: "network.host"
value: "_eth0_"
- name: "cluster.name"
value: "docker-cluster"
- name: "bootstrap.memory_lock"
value: "false"
- name: "discovery.zen.ping.unicast.hosts"
value: "elasticsearch-discovery"
- name: "discovery.zen.ping.unicast.hosts.resolve_timeout"
value: "10s"
- name: "discovery.zen.ping_timeout"
value: "6s"
- name: "discovery.zen.minimum_master_nodes"
value: "2"
- name: "discovery.zen.fd.ping_interval"
value: "2s"
- name: "discovery.zen.no_master_block"
value: "write"
- name: "gateway.expected_nodes"
value: "2"
- name: "gateway.expected_master_nodes"
value: "1"
- name: "transport.tcp.connect_timeout"
value: "60s"
- name: "ES_JAVA_OPTS"
value: "-Xms2g -Xmx2g"
livenessProbe:
tcpSocket:
port: transport
initialDelaySeconds: 20
periodSeconds: 10
volumeMounts:
- name: es-data
mountPath: /data
terminationGracePeriodSeconds: 30
volumes:
- name: es-data
hostPath:
path: /es-data
es.yaml
搭建logpilot:
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: log-pilot
namespace: kube-system
labels:
k8s-app: log-pilot
kubernetes.io/cluster-service: "true"
spec:
template:
metadata:
labels:
k8s-app: log-es
kubernetes.io/cluster-service: "true"
version: v1.22
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
serviceAccountName: dashboard-admin
containers:
- name: log-pilot
image: registry.cn-hangzhou.aliyuncs.com/imooc/log-pilot:0.9-filebeat
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
env:
- name: "FILEBEAT_OUTPUT"
value: "elasticsearch"
- name: "ELASTICSEARCH_HOST"
value: "elasticsearch-api"
- name: "ELASTICSEARCH_PORT"
value: "9200"
- name: "ELASTICSEARCH_USER"
value: "elastic"
- name: "ELASTICSEARCH_PASSWORD"
value: "changeme"
volumeMounts:
- name: sock
mountPath: /var/run/docker.sock
- name: root
mountPath: /host
readOnly: true
- name: varlib
mountPath: /var/lib/filebeat
- name: varlog
mountPath: /var/log/filebeat
securityContext:
capabilities:
add:
- SYS_ADMIN
terminationGracePeriodSeconds: 30
volumes:
- name: sock
hostPath:
path: /var/run/docker.sock
- name: root
hostPath:
path: /
- name: varlib
hostPath:
path: /var/lib/filebeat
type: DirectoryOrCreate
- name: varlog
hostPath:
path: /var/log/filebeat
type: DirectoryOrCreate
logpilot.yaml
搭建kibana:
---
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: kube-system
labels:
component: kibana
spec:
selector:
component: kibana
ports:
- name: http
port: 80
targetPort: http
---
#ingress
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kibana
namespace: kube-system
spec:
rules:
- host: kibana.mooc.com
http:
paths:
- path: /
backend:
serviceName: kibana
servicePort: 80
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: kibana
namespace: kube-system
labels:
component: kibana
spec:
replicas: 1
selector:
matchLabels:
component: kibana
template:
metadata:
labels:
component: kibana
spec:
containers:
- name: kibana
image: registry.cn-hangzhou.aliyuncs.com/imooc/kibana:5.5.1
env:
- name: CLUSTER_NAME
value: docker-cluster
- name: ELASTICSEARCH_URL
value: http://elasticsearch-api:9200/
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 5601
name: http
kibana.yaml
kubernetes常见日志采集问题和解决方案分析的更多相关文章
- 自建Kubernetes logtail日志采集客户端安装方式
自建Kubernetes安装方式 前提条件 Kubernetes集群版本1.8及以上. 已经安装Helm命令,版本2.6.4及以上. 安装步骤 在日志服务控制台创建一个Project,Project名 ...
- Kubernetes Ingress 日志分析与监控的最佳实践
摘要: Ingress主要提供HTTP层(7层)路由功能,是目前K8s中HTTP/HTTPS服务的主流暴露方式.为简化广大用户对于Ingress日志分析与监控的门槛,阿里云容器服务和日志服务将Ingr ...
- Kubernetes Ingress日志分析入门
本文主要介绍如何基于日志服务构建Kubernetes Ingress日志分析平台,并提供一些简单的动手实验方便大家快速了解日志服务相关功能. 部署Ingress日志方案 登录容器服务管理控制台. 将上 ...
- SpringCloud微服务实战——搭建企业级开发框架(三十八):搭建ELK日志采集与分析系统
一套好的日志分析系统可以详细记录系统的运行情况,方便我们定位分析系统性能瓶颈.查找定位系统问题.上一篇说明了日志的多种业务场景以及日志记录的实现方式,那么日志记录下来,相关人员就需要对日志数据进行 ...
- 使用日志服务进行Kubernetes日志采集
阿里云容器服务Kubernetes集群集成了日志服务(SLS),您可在创建集群时启用日志服务,快速采集Kubernetes 集群的容器日志,包括容器的标准输出以及容器内的文本文件. 新建 Kubern ...
- Kubernetes日志采集
Kubernetes日志打印方式 标准输出 docker标准输出日志stdout和stderr,使用docker logs或者kubectl logs查看最新的日志(tail). 如果想看到更多的日志 ...
- 日志采集技术分析 Inode Inotify
日志采集技术分析[阿里] - 新手学习导向 - 中国红客联盟 - Powered by HUC http://www.cnhonkerarmy.com/thread-236973-1-1.html
- 「视频小课堂」ELK和Kafka是怎么就玩在一起成了日志采集解决方案文字版
视频地址:ELK和Kafka是怎么就玩在一起成了日志采集解决方案 视频文字版 今天呢我就带来了一期视频,主要就是讲ELK和Kafka之间的通讯关系通过对一张通讯图,和一些操作命令,让我们能更深入的去理 ...
- Kubernetes 常用日志收集方案
Kubernetes 常用日志收集方案 学习了 Kubernetes 集群中监控系统的搭建,除了对集群的监控报警之外,还有一项运维工作是非常重要的,那就是日志的收集. 介绍 应用程序和系统日志可以帮助 ...
随机推荐
- 在Anaconda环境下安装Tensorflow
安装Anaconda 下载Anaconda 个人版Individual Edition.如果下载速度慢,可以复制下载链接到迅雷或者在清华大学开源镜像站TUNA中找合适的版本. 注意在安装过程中的&qu ...
- AOJ/高等排序习题集
ALDS1_5_B-MergeSort. Description: Write a program of a Merge Sort algorithm implemented by the follo ...
- 极简SpringBoot指南-Chapter05-SpringBoot中的AOP面向切面编程简介
仓库地址 w4ngzhen/springboot-simple-guide: This is a project that guides SpringBoot users to get started ...
- $hadow$ocks与Privoxy基础原理
$hadow$ocks与Privoxy基础原理 以下所有提到$hadow$ocks的均以ss指代 为什么要用ss呢? 在早期(如今绝大多数也是),对于互联网的访问流程是及其简单的:浏览器(或其他客户端 ...
- Multidimension Tools(多维工具)
多维工具 # Process: 创建 NetCDF 栅格图层 arcpy.MakeNetCDFRasterLayer_md("", "", "&quo ...
- NOI 2017 Day1 题解
被虐爆了... T1 整数 题目传送门 Description 有一个整数 \(x\),有 \(n\) 此操作,每次操作为以下两种情况: 给出 \(a,b\),将 \(x\) 加上 \(a\times ...
- SignalR 在React/GO技术栈的生产应用
哼哧哼哧半年,优化改进了一个运维开发web平台. 本文记录SignalR在react/golang 技术栈的生产小实践. 1. 背景 有个前后端分离的运维开发web平台, 后端会间隔5分钟同步一次数据 ...
- LuckySheet一款在线Excel使用心得
1.LuckySheet简介 Luckysheet ,是一款国产的纯JS实现的类似excel的在线表格,功能强大.配置简单.完全开源. 开源地址 https://gitee.com/mengshuke ...
- Linux常用命令,查看树形结构、删除目录(文件夹)、创建文件、删除文件或目录、复制文件或目录(文件夹)、移动、查看文件内容、权限操作
5.查看树结构(tree) 通常情况下系统未安装该命令,需要yum install -y tree安装 直接使⽤tree显示深度太多,⼀般会使⽤ -L选项⼿⼯设定⽬录深度 格式:tree -L n [ ...
- 【c++ Prime 学习笔记】第10章 泛型算法
标准库未给容器添加大量功能,而是提供一组独立于容器的泛型算法 算法:它们实现了一些经典算法的公共接口 泛型:它们可用于不同类型的容器和不同类型的元素 利用这些算法可实现容器基本操作很难做到的事,例如查 ...