基于 Mysql 实现一个简易版搜索引擎
前言
前段时间,因为项目需求,需要根据关键词搜索聊天记录,这不就是一个搜索引擎的功能吗?
于是我第一时间想到的就是 ElasticSearch 分布式搜索引擎,但是由于一些原因,公司的服务器资源比较紧张,没有额外的机器去部署一套 ElasticSearch 服务,而且上线时间也比较紧张,数据量也不大,然后就想到了 Mysql 的全文索引。
简介
其实 Mysql 很早就支持全文索引了,只不过一直只支持英文的检索,从5.7.6 版本开始,Mysql 就内置了 ngram 全文解析器,用来支持中文、日文、韩文分词。
Mysql 全文索引采用的是倒排索引的原理,在倒排索引中关键词是主键,每个关键词都对应着一系列文件,这些文件中都出现了这个关键词。这样当用户搜索某个关键词时,排序程序在倒排索引中定位到这个关键词,就可以马上找出所有包含这个关键词的文件。
本文测试,基于 Mysql 8.0 版本,数据库引擎采用的是 InnoDB
ngram 全文解析器
ngram 就是一段文字里面连续的 n 个字的序列。ngram 全文解析器能够对文本进行分词,每个单词是连续的 n 个字的序列。例如,用 ngram 全文解析器对“你好靓仔”进行分词:
n=1: '你', '好', '靓', '仔'
n=2: '你好', '好靓', '靓仔'
n=3: '你好靓', '好靓仔'
n=4: '你好靓仔'
MySQL 中使用全局变量 ngram_token_size 来配置 ngram 中 n 的大小,它的取值范围是1到10,默认值是 2。通常 ngram_token_size 设置为要查询的单词的最小字数。如果需要搜索单字,就要把 ngram_token_size 设置为 1。在默认值是 2 的情况下,搜索单字是得不到任何结果的。因为中文单词最少是两个汉字,推荐使用默认值 2。
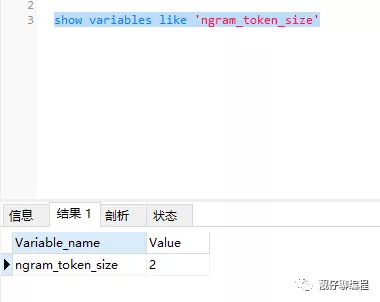
可以通过以下命令查看 Mysql 默认的 ngram_token_size 大小:
show variables like 'ngram_token_size'
有两种方式可以设置全局变量 ngram_token_size 的值:
1、启动 mysqld 命令时指定:
mysqld --ngram_token_size=2
2、修改 Mysql 配置文件 my.ini,末尾增加一行参数:
ngram_token_size=2
创建全文索引
1、建表时创建全文索引
CREATE TABLE `article` (
`id` bigint NOT NULL,
`url` varchar(1024) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '',
`title` varchar(256) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '',
`source` varchar(32) COLLATE utf8mb4_general_ci DEFAULT '',
`keywords` varchar(32) COLLATE utf8mb4_general_ci DEFAULT NULL,
`publish_time` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`id`),
FULLTEXT KEY `title_index` (`title`) WITH PARSER `ngram`
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
2、通过 alter table 方式
ALTER TABLE article ADD FULLTEXT INDEX title_index(title) WITH PARSER ngram;
3、通过 create index 方式
CREATE FULLTEXT INDEX title_index ON article (title) WITH PARSER ngram;
检索方式
1、自然语言检索(NATURAL LANGUAGE MODE)
自然语言模式是 MySQL 默认的全文检索模式。自然语言模式不能使用操作符,不能指定关键词必须出现或者必须不能出现等复杂查询。
示例
select * from article where MATCH(title) AGAINST ('北京旅游' IN NATURAL LANGUAGE MODE);
// 不指定模式,默认使用自然语言模式
select * from article where MATCH(title) AGAINST ('北京旅游');
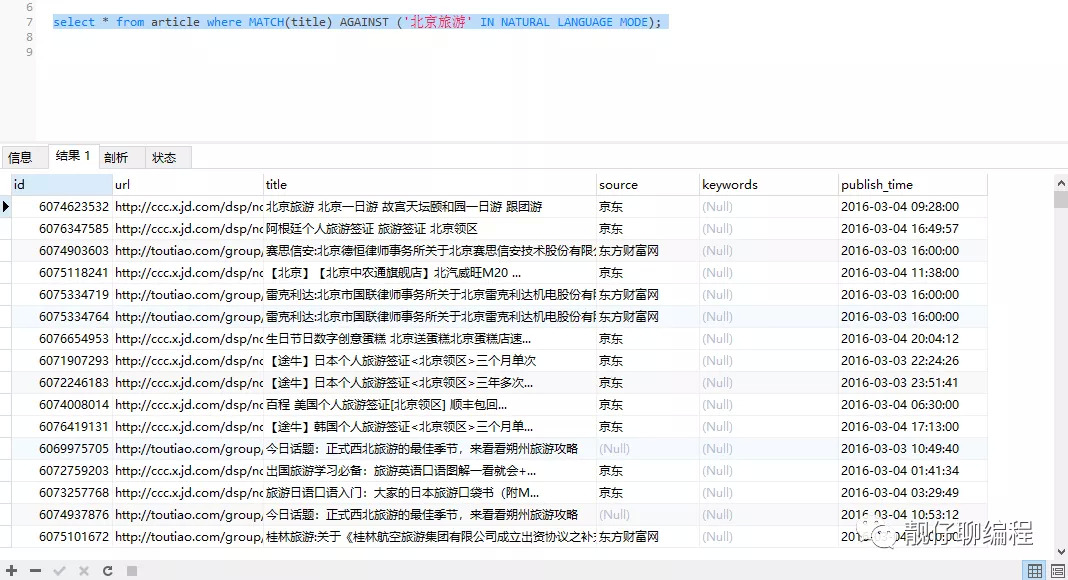
可以看出,该模式下根据“北京旅游”搜索,可以搜索出包含“北京”的或者包含“旅游”的内容,因为它是根据自然语言分成了两个关键词。
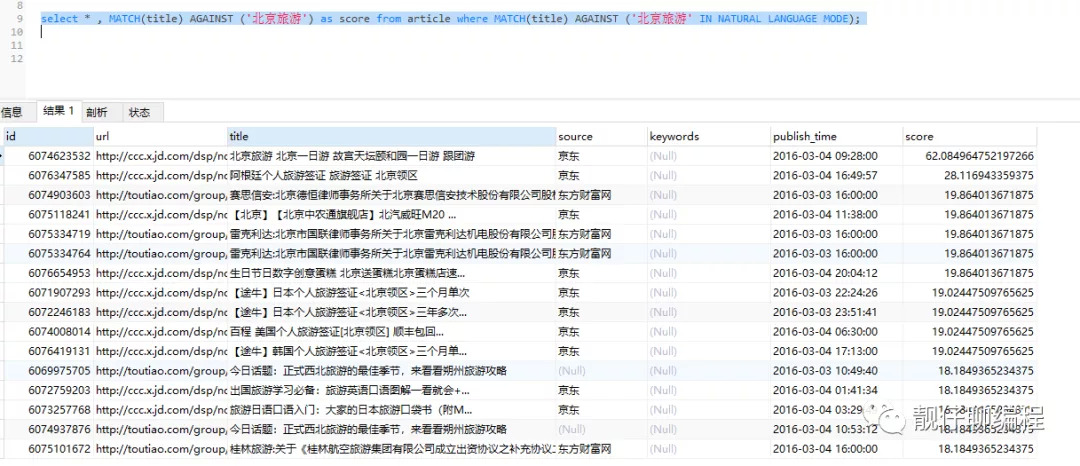
上面示例中返回的结果会自动按照匹配度排序,匹配度高的在前面,匹配度是一个非负浮点数。
示例
// 查看匹配度
select * , MATCH(title) AGAINST ('北京旅游') as score from article where MATCH(title) AGAINST ('北京旅游' IN NATURAL LANGUAGE MODE);
2、布尔检索(BOOLEAN MODE)
布尔检索模式可以使用操作符,可以支持指定关键词必须出现或者必须不能出现或者关键词的权重高还是低等复杂查询。
示例
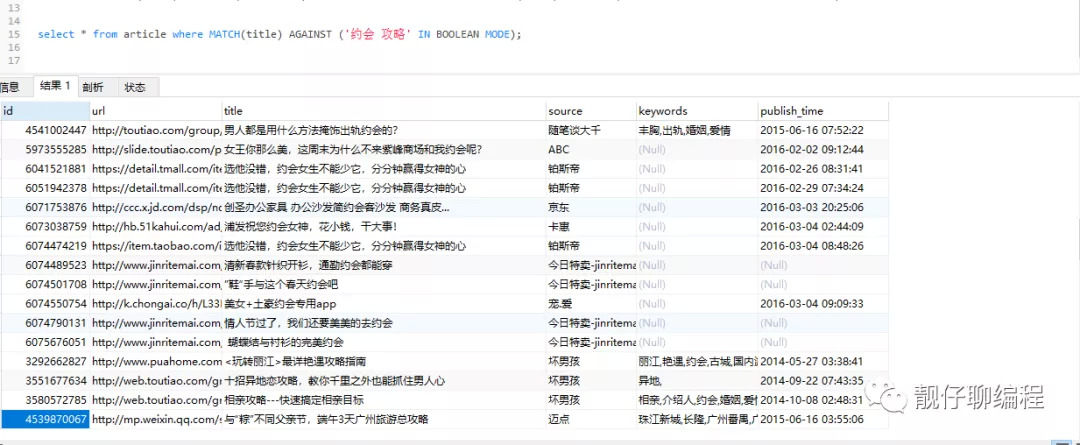
// 无操作符
// 包含“约会”或“攻略”
select * from article where MATCH(title) AGAINST ('约会 攻略' IN BOOLEAN MODE);
// 使用操作符
// 必须包含“约会”,可包含“攻略”
select * from article where MATCH(title) AGAINST ('+约会 攻略' IN BOOLEAN MODE);
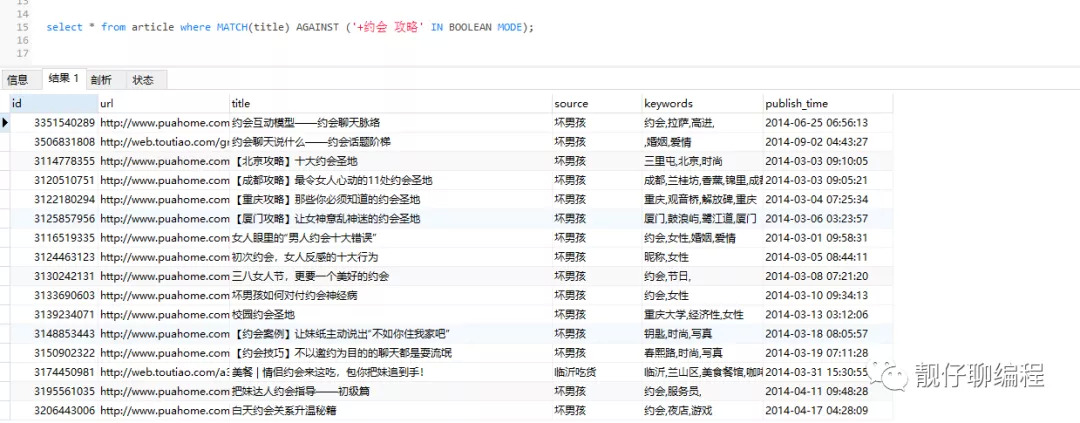
更多操作符示例:
'约会 攻略'
无操作符,表示或,要么包含“约会”,要么包含“攻略”
'+约会 +攻略'
必须同时包含两个词
'+约会 攻略'
必须包含“约会”,但是如果也包含“攻略”的话,匹配度更高。
'+约会 -攻略'
必须包含“约会”,同时不能包含“攻略”。
'+约会 ~攻略'
必须包含“约会”,但是如果也包含“攻略”的话,匹配度要比不包含“攻略”的记录低。
'+约会 +(>攻略 <技巧)'
查询必须包含“约会”和“攻略”或者“约会”和“技巧”的记录,但是“约会 攻略”的匹配度要比“约会 技巧”高。
'约会*'
查询包含以“约会”开头的记录。
'"约会攻略"'
使用双引号把要搜素的词括起来,效果类似于like '%约会攻略%',
例如“约会攻略初级篇”会被匹配到,而“约会的攻略”就不会被匹配。
与 Like 对比
全文索引和 like 查询对比,有以下优点:
- like 只是进行模糊匹配,全文索引却提供了一些语法语义的查询功能,会将要查的字符串进行分词操作,这决定于 Mysql 的词库。
- 全文索引可以自己设置词语的最小、最大长度,要忽略的词,这些都是可以设置的。
- 用全文索引去某个列查一个字符串,会返回匹配度,可以理解为匹配的关键字个数,是个浮点数。
而且全文检索的性能也是优于 like 查询的
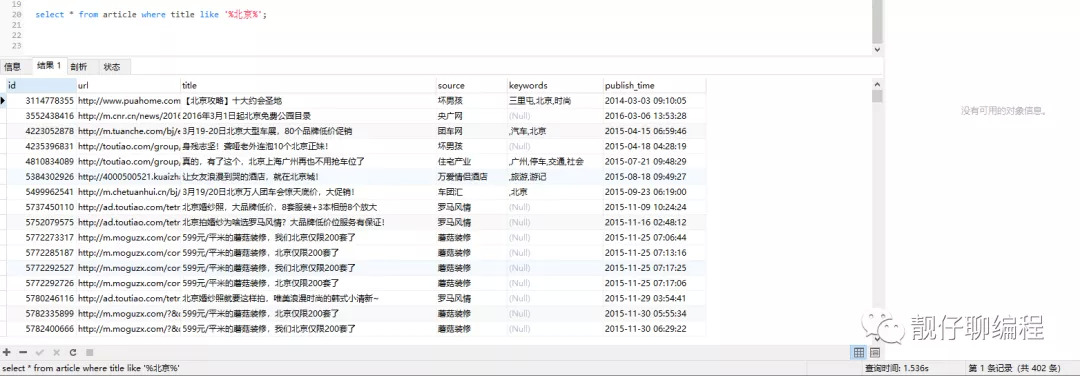
以下是以 50w 左右数据进行的测试:
// like 查询
select * from article where title like '%北京%';
// 全文索引查询
select * from article where MATCH(title) AGAINST ('北京' IN BOOLEAN MODE);
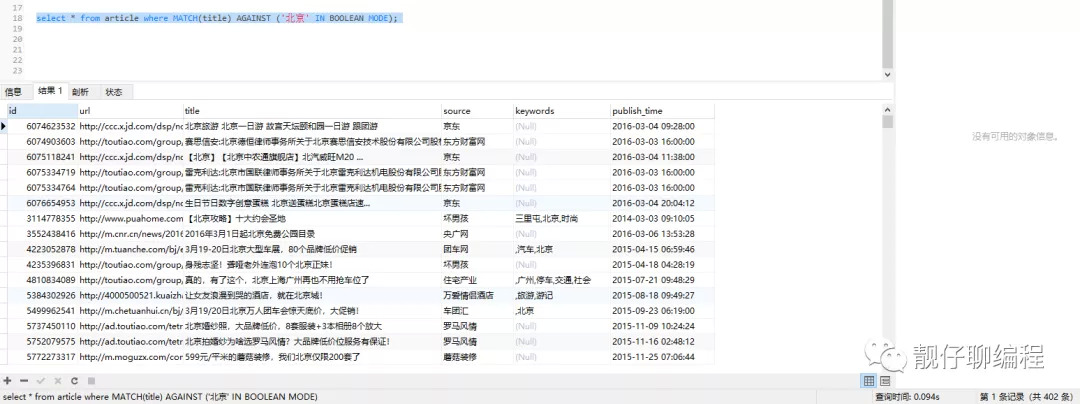
可以看出 like 查询是 1.536s,全文索引查询是 0.094s,快了16倍左右。
总结
全文索引能快速搜索,但是也存在维护索引的开销。字段长度越大,创建的全文索引也越大,会影响DML语句的吞吐量。数据量不大的情况下可以采用全文索引来做搜索,简单方便,但是数据量大的话还是建议用专门的搜索引擎 ElasticSearch 来做这件事。
END
往期推荐
基于 Mysql 实现一个简易版搜索引擎的更多相关文章
- 依赖注入[5]: 创建一个简易版的DI框架[下篇]
为了让读者朋友们能够对.NET Core DI框架的实现原理具有一个深刻而认识,我们采用与之类似的设计构架了一个名为Cat的DI框架.在<依赖注入[4]: 创建一个简易版的DI框架[上篇]> ...
- 依赖注入[4]: 创建一个简易版的DI框架[上篇]
本系列文章旨在剖析.NET Core的依赖注入框架的实现原理,到目前为止我们通过三篇文章(<控制反转>.<基于IoC的设计模式>和< 依赖注入模式>)从纯理论的角度 ...
- 如何实现一个简易版的 Spring - 如何实现 Setter 注入
前言 之前在 上篇 提到过会实现一个简易版的 IoC 和 AOP,今天它终于来了...相信对于使用 Java 开发语言的朋友们都使用过或者听说过 Spring 这个开发框架,绝大部分的企业级开发中都离 ...
- 如何实现一个简易版的 Spring - 如何实现 Constructor 注入
前言 本文是「如何实现一个简易版的 Spring」系列的第二篇,在 第一篇 介绍了如何实现一个基于 XML 的简单 Setter 注入,这篇来看看要如何去实现一个简单的 Constructor 注入功 ...
- 如何实现一个简易版的 Spring - 如何实现 @Component 注解
前言 前面两篇文章(如何实现一个简易版的 Spring - 如何实现 Setter 注入.如何实现一个简易版的 Spring - 如何实现 Constructor 注入)介绍的都是基于 XML 配置文 ...
- 如何实现一个简易版的 Spring - 如何实现 @Autowired 注解
前言 本文是 如何实现一个简易版的 Spring 系列第四篇,在 上篇 介绍了 @Component 注解的实现,这篇再来看看在使用 Spring 框架开发中常用的 @Autowired 注入要如何实 ...
- 如何实现一个简易版的 Spring - 如何实现 AOP(上)
前言 本文是「如何实现一个简易版的 Spring 系列」的第五篇,在之前介绍了 Spring 中的核心技术之一 IoC,从这篇开始我们再来看看 Spring 的另一个重要的技术--AOP.用过 Spr ...
- 如何实现一个简易版的 Spring - 如何实现 AOP(下)
前言 前面两篇 如何实现 AOP(上).如何实现 AOP(中) 做了一些 AOP 的核心基础知识简要介绍,本文进入到了实战环节了,去实现一个基于 XML 配置的简易版 AOP,虽然是简易版的但是麻雀虽 ...
- DI 原理解析 并实现一个简易版 DI 容器
本文基于自身理解进行输出,目的在于交流学习,如有不对,还望各位看官指出. DI DI-Dependency Injection,即"依赖注入":对象之间依赖关系由容器在运行期决定, ...
随机推荐
- 【剑指offer】51.构建乘积数组
51.构建乘积数组 知识点:数组: 题目描述 给定一个数组A[0,1,...,n-1],请构建一个数组B[0,1,...,n-1],其中B中的元素B[i]=A[0] * A[1] *... * A[i ...
- P2491 消防/P1099 树网的核
P2491 消防/P1099 树网的核 双倍经验,双倍快乐. 题意 在一个树上选择一段总长度不超过\(s\)的链使所有点到该链距离的最大值最小. 输出这个最小的值. 做法 Define:以下\(s\) ...
- TCP协议与HTTP协议区别
一.TCP协议与HTTP协议区别 1.直观认识 TCP协议对应于传输层,而HTTP协议对应于应用层,从本质上来说,二者没有可比性.Http协议是建立在TCP协议基础之上的,当浏览器需要从服务器获取网页 ...
- 什么是jstl表达式,怎么应用
1.介绍 JSTL(JSP Standard Tag Library),JSP标准标签库,可以嵌入在jsp页面中使用标签的形式完成业务逻辑等功能.jstl出现的目的同el一样也是要代替jsp页面中的脚 ...
- 创建多个Dialog时,namespace冲突问题的解决 -- 基于QT 5.2
问题来源: 我用MainWindow作为主界面,Dialog作为设置界面,还需要一个AboutDialog作为关于界面. 设置界面的Dialog头文件dialog.h是这样的: // dialog.h ...
- icmp介绍以及arp攻击
目录 一.ip数据包格式 二.ICMP协议介绍 三.ARP协议介绍 四.ARP攻击原理 一.ip数据包格式 网络层的功能: 定义了基于ip协议的逻辑地址 连接不同的媒介类型 选择是数据通过网络的最佳途 ...
- API接口测试
一.测试工具 二.测试方法 二.测试需要注意的点
- user-agent随笔
常用的user-agent: 一.pc端的user-agent汇总,各大浏览器 1.safari 5.1 – MAC Mozilla/5.0 (Macintosh; U; Intel Mac OS X ...
- linux笔记2随笔
124.diff命令:文件内容对比 diff命令用于比较多个文本文件之间的差异,这在系统安全防范中非常重要.比如当黑客入侵系统之后,往往会修改一些系统配置文件,从而留下一些后门. 所以作为运维人员.最 ...
- Kerberos相关的安全问题
用户名枚举 原理 不存在的用户 存在的用户 通过这个比较就可以写脚本改变cname的值进行用户名枚举. 利用 https://github.com/ropnop/kerbrute/ kerbrute. ...