Python—列表元组和字典
Python—列表元组和字典
列表
元组
字典
列表:
列表是Python中的一种数据结构,他可以存储不同类型的数据。尽量存储同一种类型
列表索引是从0开始的,我们可以通过索引来访问列表的值。
列表的赋值

案例
A=[1,'xiaoWang','a',[2,'b']]
a、lst = [1,2,3,4,5,6]#list使用[] , {}字典,()tuple
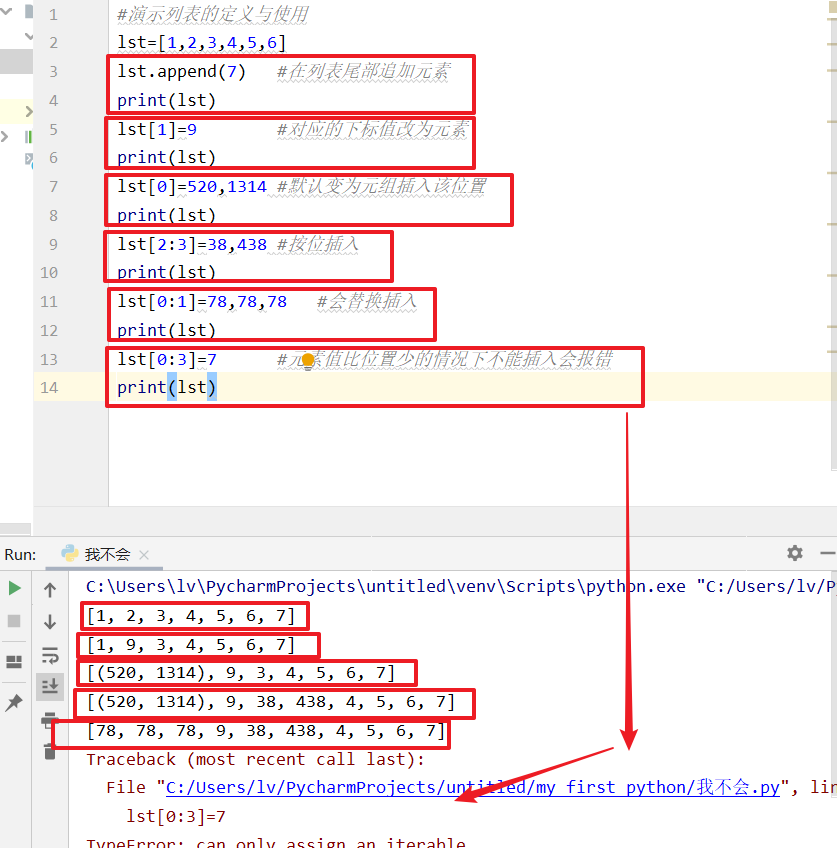
list.append(元素) 在列表尾部追加元素
第一种
lst.append(10)#再尾部追加
#结果:[1, 2, 3, 4, 5, 6, 10]
在前方插入/修改
第二种
print(lst[0:5:2]) #结果:[1, 3, 5]
lst[0]=5 #结果:[5, 2, 3, 4, 5, 6, 10]
lst[0:2]=7,12,3#结果:[7, 12, 3, 4, 5, 6, 10]
lst[0]=1,2 #默认变为元组插入该位置
extend 追加内容
第三种
lst2=[50,90] #追加的内容
lst.extend(lst2)# 追加到lst的末尾 [(1, 2), 12, 3, 3, 4, 5, 6, 10, 50, 90]
print(lst.__add__(lst2)) # 追加同时,返回追加的数字 结果:[(1, 2), 12, 3, 3, 4, 5, 6, 10, 50, 90, 50, 90]
insert 追加(少用)
第四种
lst.insert(0,66) #追加到首位 原位的值全部后移 [66, 1, 2, 3, 4, 5, 6] #当插入不在尾部时,直接转为链式表,结果时再转回
线性表,不适用,少用
存在与否
第五种
print(8 in lst) #是否存在 存在为true /false 结果False
print( 1 in lst)#结果 True
根据值查找下标
第六种
print(lst.index((5))) #返回值的下标 结果 :4
根据下标将值替代成指定元素
第七种
lst[2],lst[5]=22,55 #根据下标将值替代成指定元素 结果:[1, 2, 22, 4, 5, 55]
多元素替换多个位置的值
第八种
lst[0:5]=77,88 #多个元素替换多个位置的值 结果:[77, 88, 55] 但如果只有一个替换值,则报错
删除del
第九种
del lst[0] #直接删除下标 结果: [2, 3, 4, 5, 6]
#删除 remove
lst.remove(2) #直接移除值 劣势:容易让人误会
#删除 pop
lst.pop() #不加值,默认移除最后一个,若加下标,则删除下标 [3, 4, 5]
循环随机数列表遍历及用长度遍历
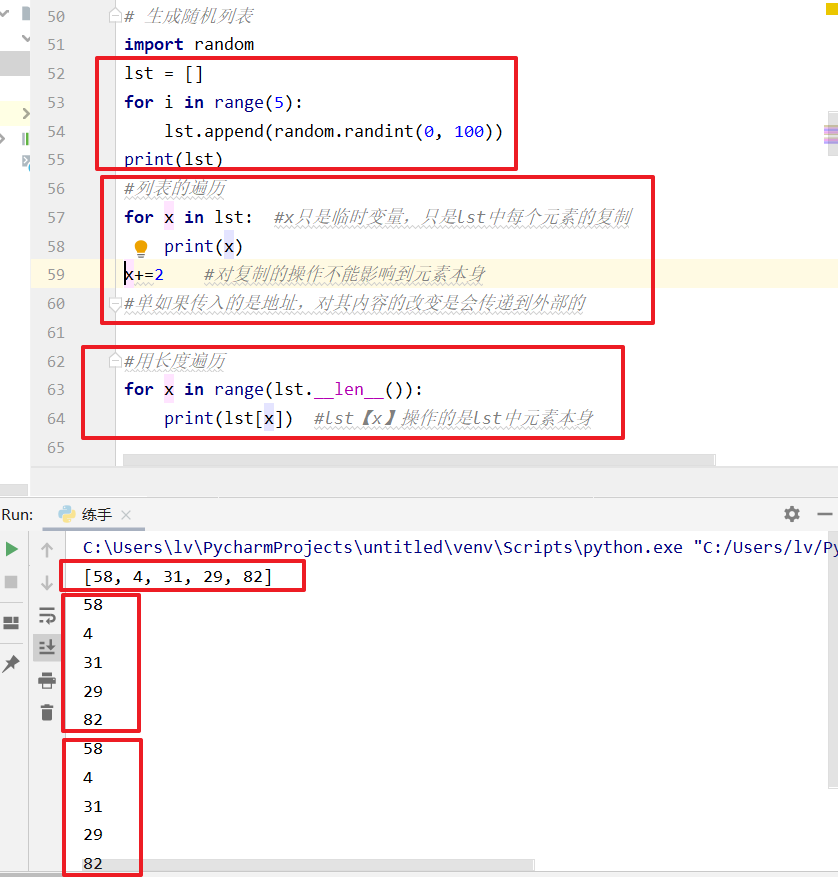
第一种
lst=[]
for i in range(5):
lst.append(random.randint(0,100))
print(lst)
#结果:[24, 26, 36, 92, 59] 第二种
b、随机数的遍历 [第一种]
for x in lst:
print(x)
#结果:
98
73
56
15
75 第三种
c、随机数长度遍历
for x in range(lst.__len__()): *****#使用下标遍历******
print(lst[x])
#结果:
98
73
56
15
75
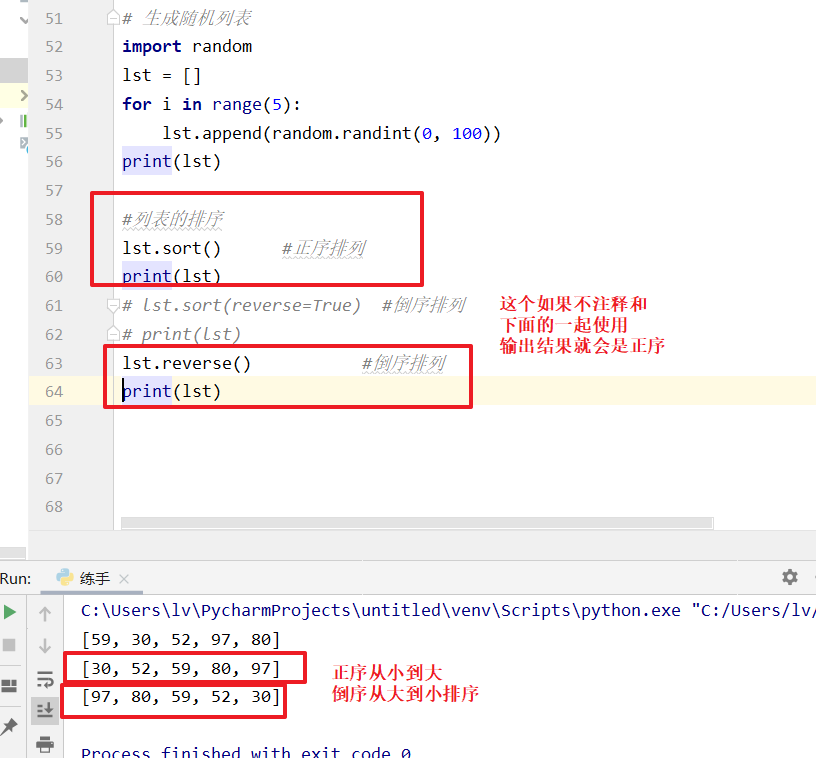
列表的排序操作
#列表的排序
lst.sort() #正序
lst.sort(reverse=True) #倒序
lst.reverse() #倒序
print(lst)
冒泡排序
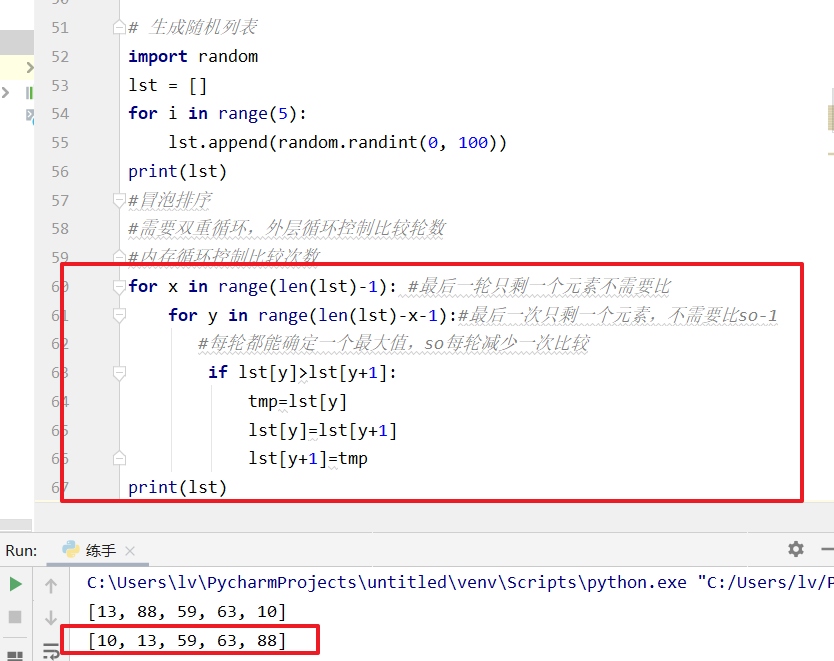
#冒泡排序
#双重循环、外层控制比较轮数,内层循环控制每轮比较次数
for i in range(len(lst)-1): #最后一轮只剩一个元素,不需要比较,因此减-1
for j in range(len(lst)-i-1):#最后一个只剩一个元素,不需要比较,所以-1
#每轮都能确定一个最大值,所以每轮减少一次比较
if lst[j] > lst[j+1]:
tmp=lst[j]
lst[j]=lst[j+1]
lst[j+1]=tmp
print(lst)
选择排序
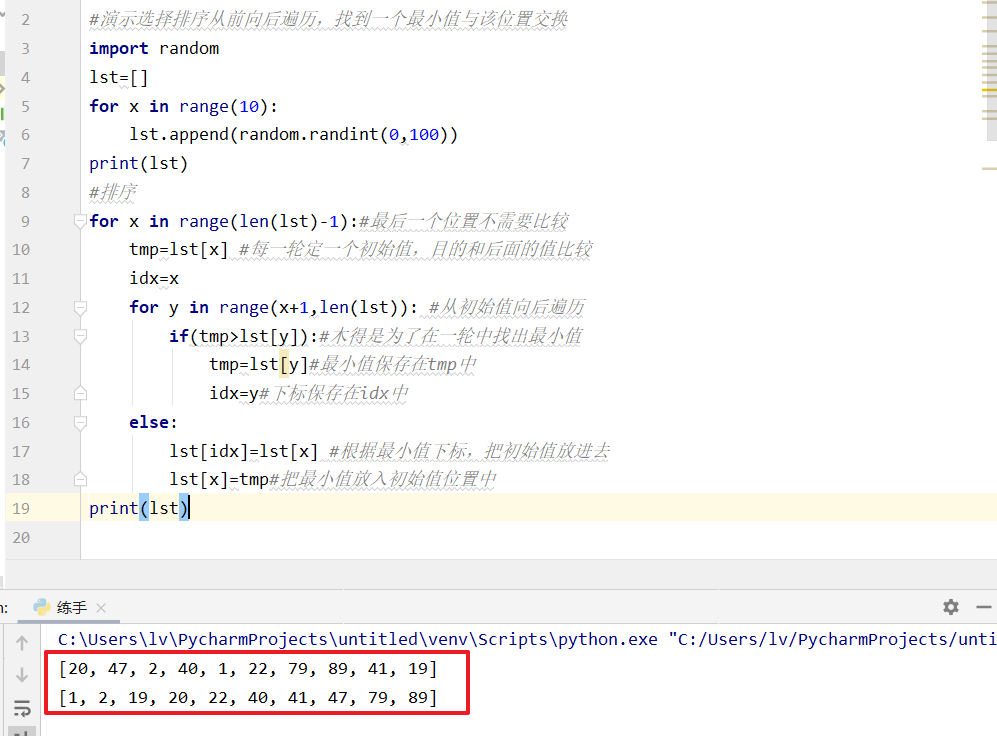
#演示选择排序 :从前向后遍历,找到一个最小值与该位置交换
import random
lst=[]
for x in range(10):
lst.append(random.randint(0,100))
print(lst)
#排序
for x in range(len(lst)-1):#最后一个位置不需要比较
tmp=lst[x] #每一轮定一个初始值,目的和后面的值比较
idx=x
for y in range(x+1,len(lst)): #从初始值向后遍历
if(tmp>lst[y]):#木得是为了在一轮中找出最小值
tmp=lst[y]#最小值保存在tmp中
idx=y#下标保存在idx中
else:
lst[idx]=lst[x] #根据最小值下标,把初始值放进去
lst[x]=tmp#把最小值放入初始值位置中
print(lst)
插入排序
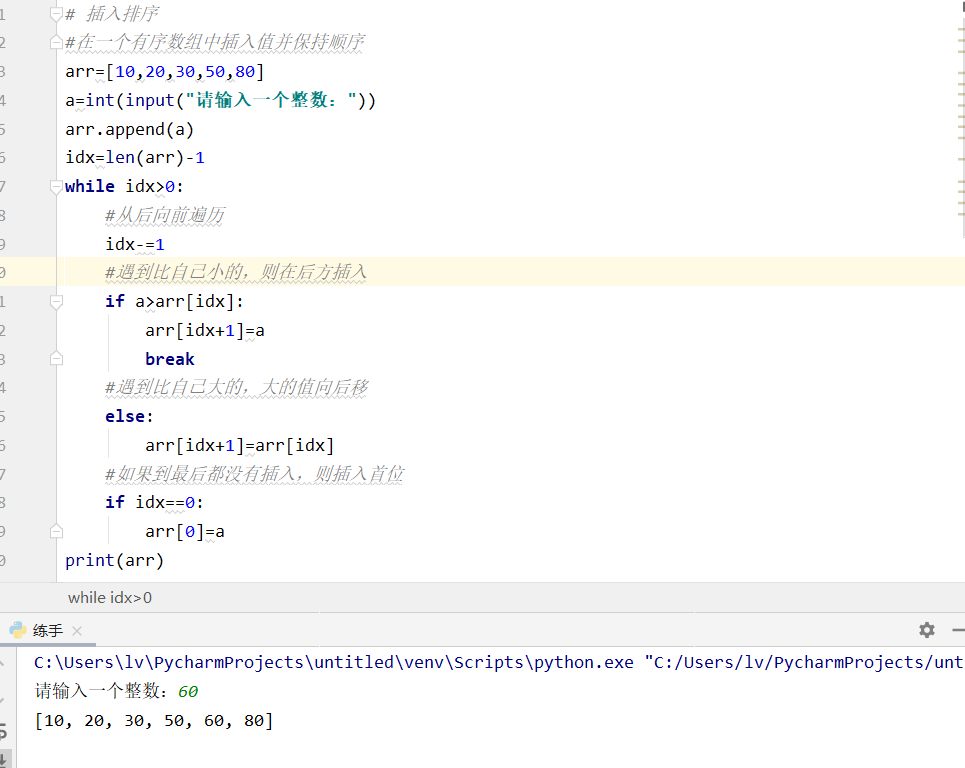
#插入排序1:
arr=[10,20,30,50,80]
a=int(input("请输入一个整数:"))
arr.append(a)
idx=len(arr)-1
while idx>0:
#从后向前遍历
idx-=1
#遇到比自己小的,则在后方插入
if a>arr[idx]:
arr[idx+1]=a
break
#遇到比自己大的,大的值向后移
else:
arr[idx+1]=arr[idx]
#如果到最后都没有插入,则插入首位
if idx==0:
arr[0]=a
print(arr)
插入排序
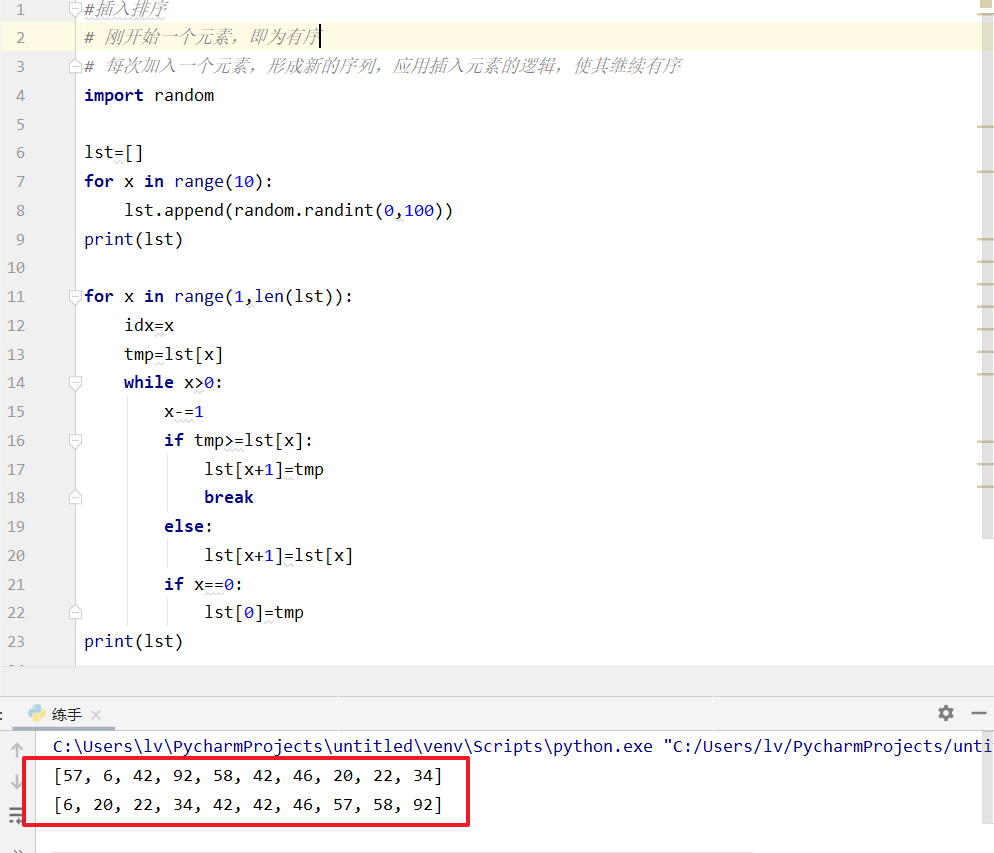
#插入排序2:
import random lst=[]
for x in range(10):
lst.append(random.randint(0,100))
print(lst) for x in range(1,len(lst)):
idx=x
tmp=lst[x]
while x>0:
x-=1
if tmp>=lst[x]:
lst[x+1]=tmp
break
else:
lst[x+1]=lst[x]
if x==0:
lst[0]=tmp
print(lst)
嵌套列表的遍历
指的是一个列表的元素又是一个列表 【遍历的区别】

案例一:
for x in school_name:
for y in range(len(x)):
print(x[y])
#结果:北大、清华、南开、中山、山大、苏大
案例二
for x in school_name:
for y in x:
print(y)
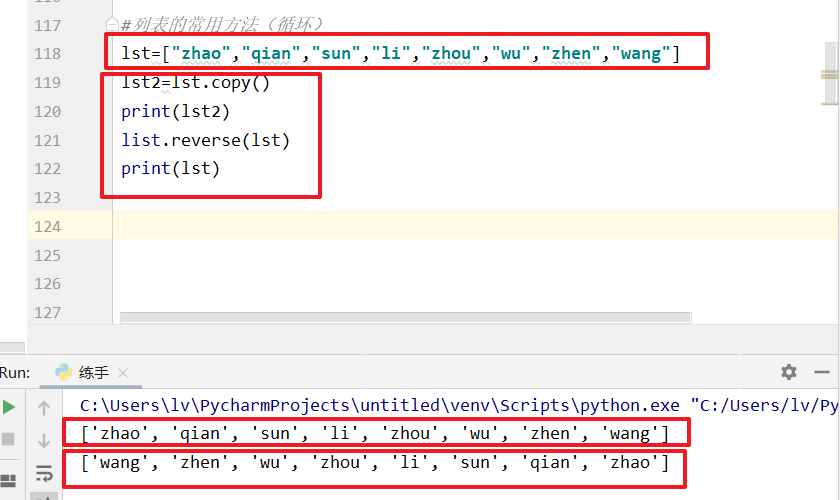
列表常用循环
列表常用循环
lst=["zhao","qian","sun","li","zhou","wu","zhen","wang"]
lst2=lst.copy() #赋值给指定的值
print(lst2) list.reverse(lst) #即将列表反序输出
print(lst)
元组
元素的元素不可修改,使用()包裹元素
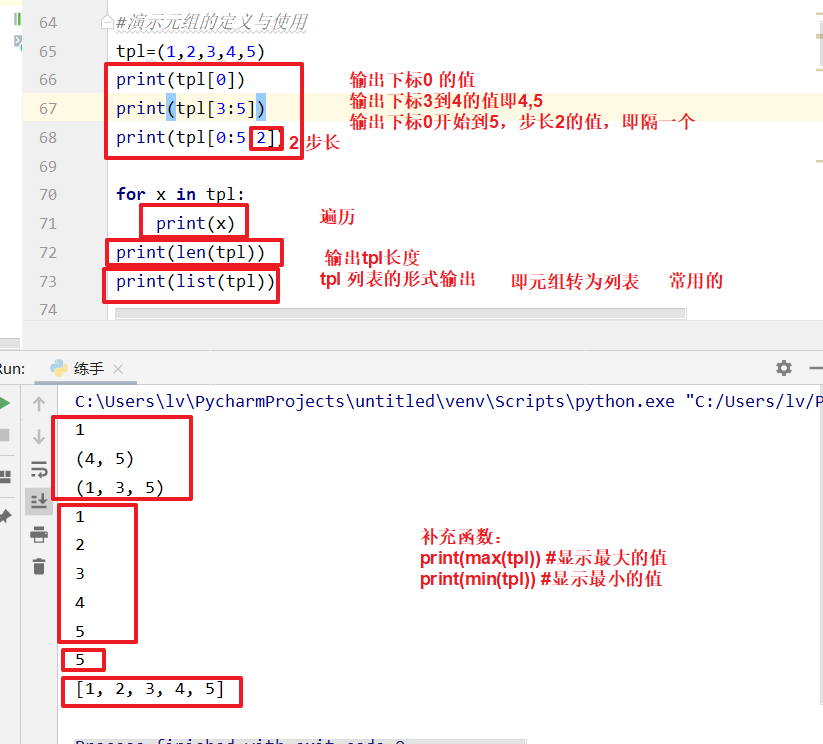
基本使用
tpl=(1,2,3,4,5)
print(type(tpl))
print(tpl[0])
print(tpl[0:3])
print(tpl[0:5:2]) #步长 显示单数
print(tpl[1:5:2]) #步长 显示双数
for x in tpl: #遍历
print(x)
函数
print(max(tpl)) #显示最大值
print(min(tpl)) #显示最小值
print(list(tpl)) #元组转为列表【常用】
字典
一种存储数据的容器,每一个元素由键值对构成
set用法
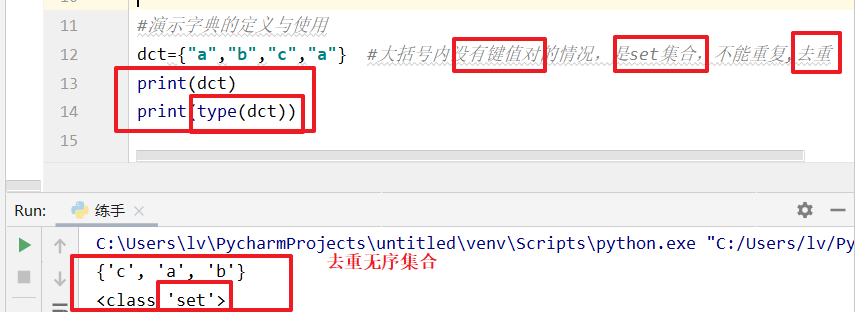
set
dct={'a','b','c','a'} #当大括号内没有键值对时,使用的是set(无序集合),特点是“去重”
print(dct)
print(type(dct))
案例
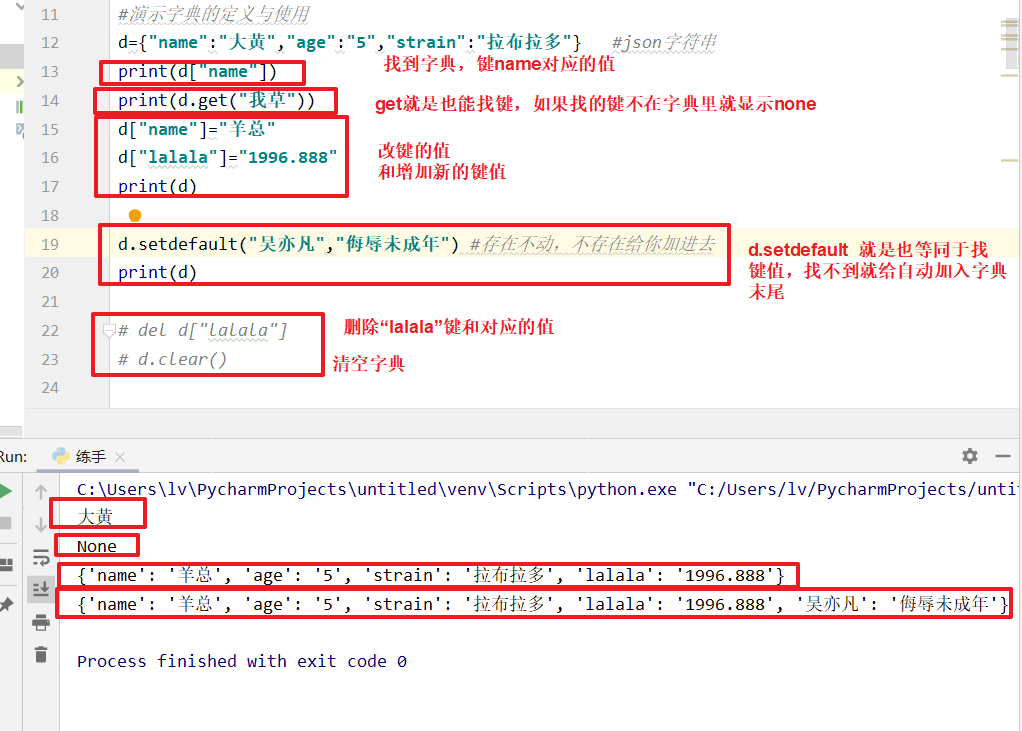
d={"name":"大黄","age":"5","strain":"拉布拉多"} #json字符串
print(d["name"])
print(d.get("我草"))
d["name"]="羊总"
d["lalala"]="1996.888"
print(d)
d.setdefault("吴亦凡","侮辱未成年") #存在不动,不存在给你加进去
print(d)
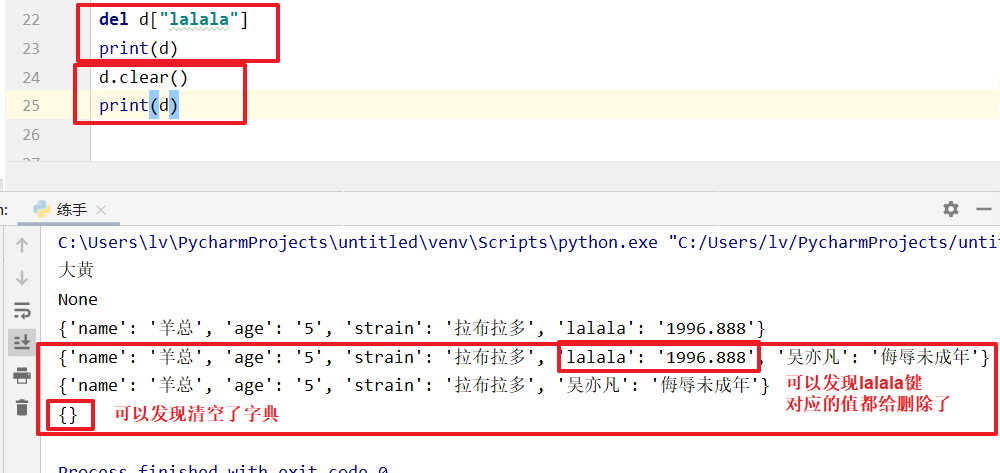
删除
d.clear()#清空 结果:{}
del d['result'] #结果:{'name': '羊总', 'mouth': 5, 'how': '2021-11'}
print(d)
keys用法
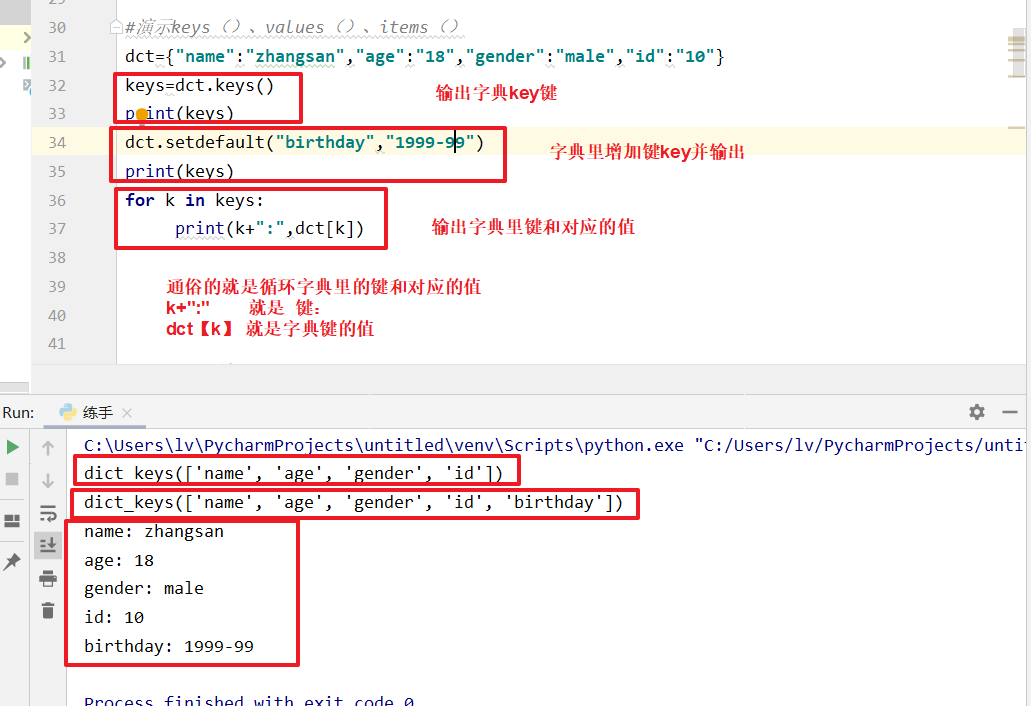
#演示keys()、values()、items()
dct={"name":"zhangsan","age":"18","gender":"male","id":"10"}
keys=dct.keys()
print(keys)
dct.setdefault("birthday","1999-99")
print(keys)
for k in keys:
print(k+":",dct[k])
items()用法
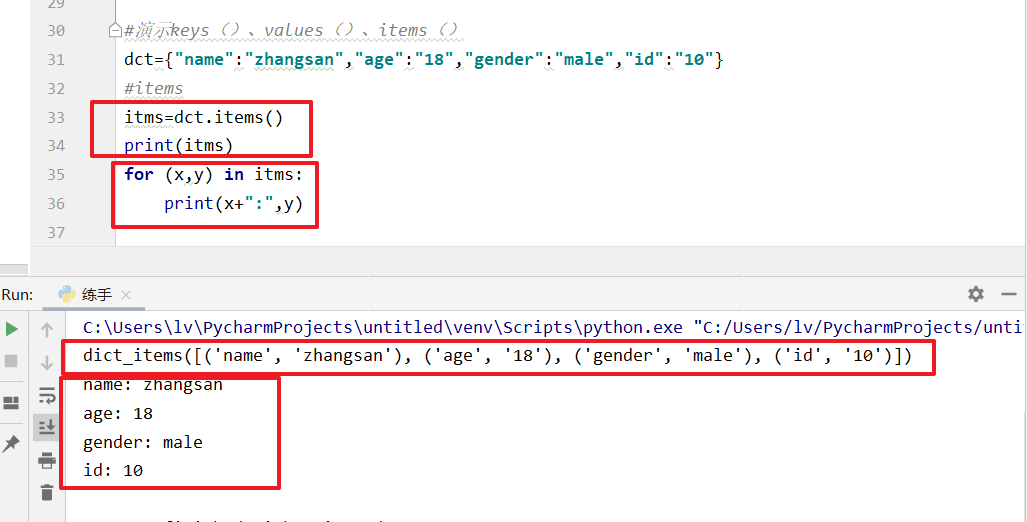
dct={"name":"zhangsan","age":"18","gender":"male","id":"10"}
#items
itms=dct.items()
print(itms)
for (x,y) in itms:
print(x+":",y)
values()用法
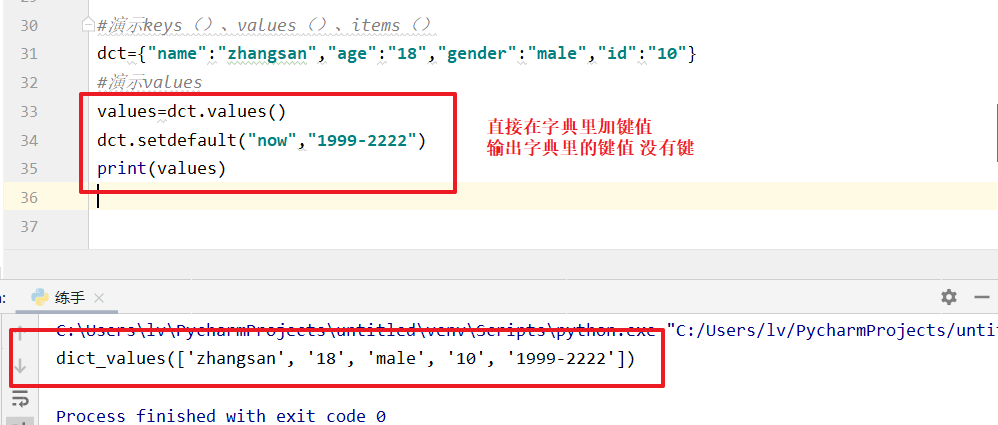
values=dct.values()
print(values) #结果: dict_values(['张三', 18, 'male', 10]) 注意 后出现的数值才会被使用
for (x,y) in items:
print(x+':',y)
Python—列表元组和字典的更多相关文章
- Python成长笔记 - 基础篇 (三)python列表元组、字典、集合
本节内容 列表.元组操作 字符串操作 字典操作 集合操作 文件操作 字符编码与转码 一.列表和元组的操作 列表是我们最以后最常用的数据类型之一,通过列表可以对数据实现最方便的存储.修改等操作 定义 ...
- python—列表,元组,字典
——列表:(中括号括起来:逗号分隔每个元素:列表中的元素可以是数字,字符串,列表,布尔值等等) (列表元素可以被修改) list(类) (有序的) [1]索引取值:切片取值:for循环:whi ...
- Python列表元组和字典解析式
目录 列表解析式List comprehensive 集合解析式Set comprehensive 字典解析式Dict comprehensive 总结 以下内容基于Python 3x 列表解析式Li ...
- python列表元组
python列表元组 索引 切片 追加 删除 长度 循环 包含 定义一个列表 my_list = [] my_list = list() my_list = ['Michael', ' ...
- 【277】◀▶ Python 列表/元组/字典说明
目录: 前言 一.访问列表中的值 二.更新列表 三.删除列表元素 四.Python 列表脚本操作符 五.Python 列表函数 & 方法 参考:Python 列表(List)使用说明 列表截取 ...
- Python 列表,元组,字典
0)字符串切片 py_str = 'python' >>>py_str[0] #取第一个字符串,返回值为"p",超出范围会报错 >>>py_st ...
- Python 列表/元组/字典总结
序列是Python中最基本的数据结构.序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推. Python有6个序列的内置类型,但最常见的是列表和元组. 序列 ...
- Python列表,元组,字典,字符串方法笔记
01. 列表 1.1 列表的定义 List(列表) 是 Python 中使用 最频繁 的数据类型,在其他语言中通常叫做 数组 专门用于存储 一串 信息 列表用 [] 定义,数据 之间使用 , 分隔 列 ...
- python3笔记十八:python列表元组字典集合文件操作
一:学习内容 列表元组字典集合文件操作 二:列表元组字典集合文件操作 代码: import pickle #数据持久性模块 #封装的方法def OptionData(data,path): # ...
随机推荐
- 【Linux】Linux没有网络,可能的解决方法
[root@localhost etc]# cd /etc/sysconfig/network-scripts/ [root@localhost network-scripts]# ll 修改此文件中 ...
- mysql组织结构
1.数据的组织结构 <1>层次型 <2>网状型 <3>关系型 2.mysql软件包格式 <1>.软件包管理器特有的格式:.rpm包 ...
- 第三代微服务架构:基于 Go 的博客微服务实战案例,支持分布式事务
这是一个可一键部署在 Kubernetes-Istio 集群中的,基于 Golang 的博客微服务 Demo,支持分布式事务. 项目地址:https://github.com/jxlwqq/blog- ...
- python+appium运行提示找不到adb.exe “An unknown server-side error occurred while processing the command. Original error: Could not find 'adb.exe' in ["D:\\adt\\sdk;\\platform-tools\\adb.exe"”
自己踩过的坑,不记下来就会忘掉,忘了就会不断的重复踩坑!! 重来在一台电脑上搭建了python的环境,在运行的时候,提示找不到adb.exe,看到这个问题我在想是不是我的环境变量配置有问题,我就去改了 ...
- 使用用支付宝时,返回的数据中subject为中文时验签失败
解决方法为: 来自为知笔记(Wiz)
- linux centos7 修改文件启动报错如何拯救
系统无法启动 CentOS启动的时候读条已经读满,但是没有反应,按下f5键跳出启动列表,最后一条信息:A start job is running for /etc/rc.d/rc.local Com ...
- 基于CentOS7.x gitlab环境搭建,卸载,汉化 --搭建篇
gitlab环境搭建,卸载,汉化 --搭建篇 环境搭建 安装依赖软件 yum -y install policycoreutils openssh-server openssh-clients pos ...
- 报错 java.sql.SQLException: Value '0000-00-00 00:00:00' can not be represented as java.sql.Timestamp 原因
sql异常 java.sql.SQLException: Value '0000-00-00 00:00:00' can not be represented as java.sql.Timestam ...
- 第10组 Beta冲刺 (5/5)
1.1基本情况 ·队名:今晚不睡觉 ·组长博客:https://www.cnblogs.com/cpandbb/p/14018671.html ·作业博客:https://edu.cnblogs.co ...
- VM搭建Hadoop环境静态IP未起作用
原文 https://www.toutiao.com/i6481452558941438478/ 问题描述 1.环境工具 VMware_workstation_full_12.5.2 CentOS-7 ...