MySQL索引篇之索引存储模型
本文重点介绍下索引的存储模型
二分查找
给定一个1~100的自然数,给你5次机会,你能猜中这个数字吗?
你会从多少开始猜?
为什么一定是50呢?这个就是二分查找的一种思想,也叫折半查找,每一次,我们都把候选数据缩小了一半。如果数据已经排过序的话,这种方式效率比较高。
所以第一个,既然索引是有序的,我们可以考虑用有序数组作为索引的数据结构。
有序数组的等值查询和比较查询效率非常高,但是更新数据的时候会出现一个问题,可能要挪动大量的数据(改变index),所以只适合存储静态的数据。
为了支持频繁的修改,比如插入数据,我们需要采用链表。链表的话,如果是单链表,它的查找效率还是不够高。
所以,有没有可以使用二分查找的链表呢?
为了解决这个问题,BST(Binary [ˈbaɪnəri] Search Tree)也就是我们所说的二叉查找树诞生了。
二叉查找树
BST Binary Search Tree 二叉查找树的特点:左子树所有的节点都小于父节点,右子树所有的节点都大于父节点。投影到平面以后,就是一个有序的线性表。

二叉查找树既能够实现快速查找,又能够实现快速插入。
但是二叉查找树有一个问题:查找耗时是和这棵树的深度相关的,在最坏的情况下时间复杂度会退化成O(n)。
什么情况是最坏的情况呢?
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
还是刚才的这一批数字,如果我们插入的数据刚好是有序的,2、6、11、13、17、22。
这个时候BST会变成链表( “斜树”),这种情况下不能达到加快检索速度的目的,和顺序查找效率是没有区别的。
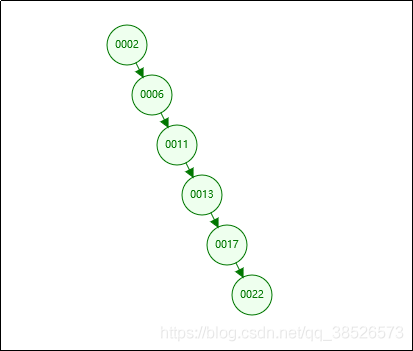
造成它倾斜的原因是什么呢?
因为左右子树深度差太大,这棵树的左子树根本没有节点——也就是它不够平衡。
所以,我们有没有左右子树深度相差不是那么大,更加平衡的树呢?
这个就是平衡二叉树,叫做Balanced binary search trees,或者AVL树(AVL是发明这个数据结构的人的名字)。
平衡二叉树
AVL Trees (Balanced binary search trees)
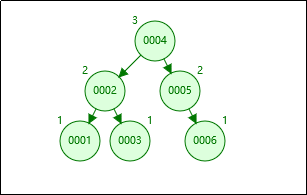
平衡二叉树的定义:左右子树深度差绝对值不能超过1。
是什么意思呢?比如左子树的深度是2,右子树的深度只能是1或者3。
这个时候我们再按顺序插入1、2、3、4、5、6,一定是这样,不会变成一棵“斜树”。
那AVL树的平衡是怎么做到的呢?怎么保证左右子树的深度差不能超过1呢?
https://www.cs.usfca.edu/~galles/visualization/AVLtree.html
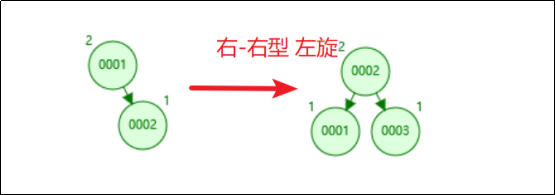
插入1、2、3。
当我们插入了1、2之后,如果按照二叉查找树的定义,3肯定是要在2的右边的,这个时候根节点1的右节点深度会变成2,但是左节点的深度是0,因为它没有子节点,所以就会违反平衡二叉树的定义。
那应该怎么办呢?因为它是右节点下面接一个右节点,右-右型,所以这个时候我们要把2提上去,这个操作叫做左旋。
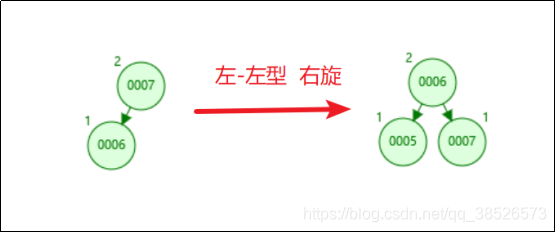
同样的,如果我们插入7、6、5,这个时候会变成左左型,就会发生右旋操作,把6提上去。
所以为了保持平衡,AVL树在插入和更新数据的时候执行了一系列的计算和调整的操作。
平衡的问题我们解决了,那么平衡二叉树作为索引怎么查询数据?
在平衡二叉树中,一个节点,它的大小是一个固定的单位,作为索引应该存储什么内容?
它应该存储三块的内容:
第一个是索引的键值。比如我们在id上面创建了一个索引,我在用where id =1的条件查询的时候就会找到索引里面的id的这个键值。
第二个是数据的磁盘地址,因为索引的作用就是去查找数据的存放的地址。
第三个,因为是二叉树,它必须还要有左子节点和右子节点的引用,这样我们才能找到下一个节点。比如大于26的时候,走右边,到下一个树的节点,继续判断。

当我们用树的结构来存储索引的时候,因为拿到一块数据就要在Server层比较是不是需要的数据,如果不是的话就要决定走左子树还是右子树,再读一一个节点。访问一个树的节点就是一次磁盘的I/O操作。
因为InnoDB操作磁盘的最小的单位是一页(或者叫一个磁盘块),page的默认大小是16KB(16384字节)。那么,读取一个树的节点就是读取16KB的大小。
如果我们一个节点只存一个键值+数据+引用,例如整形的字段,可能只用了十几个或者几十个字节,它远远达不到16384个字节的容量。所以访问一个树节点,进行一次I/O的时候,浪费了大量的空间。
所以如果每个节点存储的数据太少,从索引中找到我们需要的数据,就要访问更多的节点,意味着跟磁盘交互次数就会过多。
如果是机械硬盘时代,每次从磁盘读取数据需要10ms左右的寻址时间,交互次数越多,消耗的时间就越多。
比如上面这张图,我们一张表里面有6条数据,当我们查询id=37的时候,要查询两个子节点,就需要跟磁盘交互3次,如果我们有几百万的数据呢?这个时间更加难以估计。
所以我们的解决方案是什么呢?
第一个就是让每个节点存储更多的数据,充分利用16KB的大小,这样读取一个节点就能对比更多数据,较少对比次数。
第二个,节点上的关键字的数量越多,我们的指针数也越多,也就是意味着可以有更多的分叉(我们把它叫做“路数”)。
因为分叉数越多,树的深度就会减少(根节点是0)。
这样,我们的树是不是从原来的高瘦高瘦的样子,变成了矮胖矮胖的样子?
这个时候,我们的树就不再是二叉了,而是多叉,或者叫做多路。
多路平衡查找树
(Balanced Tree)
这个就是我们的多路平衡查找树,叫做B Tree(B代表平衡)。
跟AVL树一样,B树在枝节点和叶子节点存储键值、数据地址、节点引用。
它有一个特点:分叉数(路数)永远比关键字数多1。比如我们画的这棵树,每个节点存储两个关键字,那么就会有三个指针指向三个子节点。
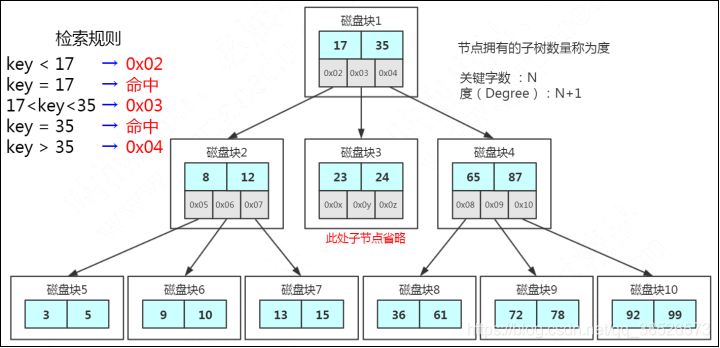
B Tree的查找规则是什么样的呢?
比如我们要在这张表里面查找15。
因为15小于17,走左边。
因为15大于12,走右边。
在磁盘块7里面就找到了15,只用了3次IO。
这个是不是比AVL 树效率更高呢?
那B Tree又是怎么实现一个节点存储多个关键字,还保持平衡的呢?跟AVL树有什么区别?
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
比如Max Degree(路数)是3的时候,我们插入数据1、2、3,在插入3的时候,本来应该在第一个磁盘块,但是如果一个节点有三个关键字的时候,意味着有4个指针,子节点会变成4路,所以这个时候必须进行分裂(其实就是B+Tree)。把中间的数据2提上去,把1和3变成2的子节点。
如果删除节点,会有相反的合并的操作。
注意这里是分裂和合并,跟AVL树的左旋和右旋是不一样的。
我们继续插入4和5,B Tree又会出现分裂和合并的操作。

从这个里面我们也能看到,在更新索引的时候会有大量的索引的结构的调整,所以解释了为什么我们不要在频繁更新的列上建索引,或者为什么不要更新主键。
节点的分裂和合并,其实就是InnoDB页(page)的分裂和合并。
B+树
加强版多路平衡查找树
因为B Tree的这种特性非常适合用于做索引的数据结构,所以很多文件系统和数据库的索引都是基于B Tree的。
但是实际上,MySQL里面使用的是B Tree的改良版本,叫做B+Tree(加强版多路平衡查找树)。
B+树的存储结构:
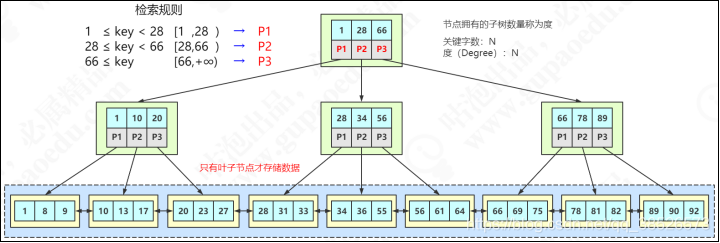
MySQL中的B+Tree有几个特点:
- 它的关键字的数量是跟路数相等的;
- B+Tree的根节点和枝节点中都不会存储数据,只有叶子节点才存储数据。InnoDB 中 B+ 树深度一般为 1-3 层,它就能满足千万级的数据存储。搜索到关键字不会直接返回,会到最后一层的叶子节点。比如我们搜索id=28,虽然在第一层直接命中了,但是全部的数据在叶子节点上面,所以我还要继续往下搜索,一直到叶子节点。
- B+Tree的每个叶子节点增加了一个指向相邻叶子节点的指针,它的最后一个数据会指向下一个叶子节点的第一个数据,形成了一个有序链表的结构。
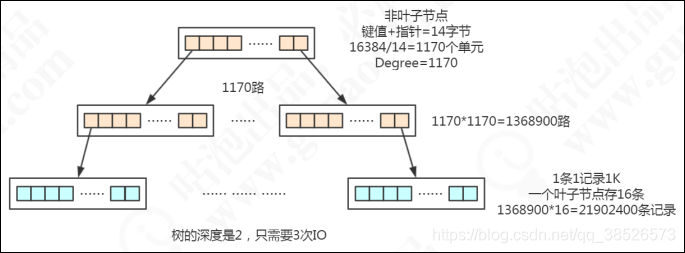
总结一下, B+Tree的特点带来的优势:
- 它是B Tree的变种,B Tree能解决的问题,它都能解决。B Tree解决的两大问题是什么?(每个节点存储更多关键字;路数更多)
- 扫库、扫表能力更强(如果我们要对表进行全表扫描,只需要遍历叶子节点就可以了,不需要遍历整棵B+Tree拿到所有的数据)
- B+Tree的磁盘读写能力相对于B Tree来说更强(根节点和枝节点不保存数据区,所以一个节点可以保存更多的关键字,一次磁盘加载的关键字更多)
- 排序能力更强(因为叶子节点上有下一个数据区的指针,数据形成了链表)
- 效率更加稳定(B+Tree永远是在叶子节点拿到数据,所以IO次数是稳定的)
MySQL索引篇之索引存储模型的更多相关文章
- MySQL数据库篇之索引原理与慢查询优化之一
主要内容: 一.索引的介绍 二.索引的原理 三.索引的数据结构 四.聚集索引与辅助索引 五.MySQL索引管理 六.测试索引 七.正确使用索引 八.联合索引与覆盖索引 九.查询优化神器--explai ...
- MySQL数据库篇之索引原理与慢查询优化之二
接上篇 7️⃣ 正确使用索引 一.索引未命中 并不是说我们创建了索引就一定会加快查询速度,若想利用索引达到预想的提高查询速度的效果, 我们在添加索引时,必须遵循以下问题: #1 范围问题,或者说条件 ...
- 【宇哥带你玩转MySQL】索引篇(一)索引揭秘,看他是如何让你的查询性能指数提升的
场景复现,一个索引提高600倍查询速度? 首先准备一张books表 create table books( id int not null primary key auto_increment, na ...
- 剖析Elasticsearch集群系列第一篇 Elasticsearch的存储模型和读写操作
剖析Elasticsearch集群系列涵盖了当今最流行的分布式搜索引擎Elasticsearch的底层架构和原型实例. 本文是这个系列的第一篇,在本文中,我们将讨论的Elasticsearch的底层存 ...
- 有评论就是我最大的动力~MySQL基础篇完结(存储引擎和图形化管理工具)
hi 今天登上来,发现竟然有了3个评论~~加油吧! 这周的计划其实远远没有达到,然后下周还有一大堆事情...那么...周末好好玩吧~ 今天试图完结MySQL的基础篇知识,小白变为大白? 1.MySQL ...
- ElasticSearch入门 第三篇:索引
这是ElasticSearch 2.4 版本系列的第三篇: ElasticSearch入门 第一篇:Windows下安装ElasticSearch ElasticSearch入门 第二篇:集群配置 E ...
- SQL优化 · 经典案例 · 索引篇
Introduction 在这些年的工作之中,由于SQL问题导致的数据库故障层出不穷,下面将过去六年工作中遇到的SQL问题总结归类,还原问题原貌,给出分析问题思路和解决问题的方法,帮助用户在使用数据库 ...
- 「 MySQL高级篇 」MySQL索引原理,设计原则
大家好,我是melo,一名大二后台练习生,大年初三,我又来充当反内卷第一人了!!! 专栏引言 MySQL,一个熟悉又陌生的名词,早在学习Javaweb的时候,我们就用到了MySQL数据库,在那个阶段, ...
- 「MySQL高级篇」MySQL索引原理,设计原则
大家好,我是melo,一名大二后台练习生,大年初三,我又来充当反内卷第一人了!!! 专栏引言 MySQL,一个熟悉又陌生的名词,早在学习Javaweb的时候,我们就用到了MySQL数据库,在那个阶段, ...
随机推荐
- docker 创建各容器命令合集
学习中...持续更新 docker-compose安装: curl -L https://github.com/docker/compose/releases/download/1.27.4/dock ...
- 17 shell break与continue
使用 while.until.for.select 循环时,如果想提前结束循环(在不满足结束条件的情况下结束循环),可以使用 break 或者 continue 关键字. 在C语言.Python.Ja ...
- Acunetix引入了Docker支持,扫描统计信息以及将漏洞发送到AWS WAF的功能
已针对Windows,Linux和macOS发布了新的Acunetix更新:14.2.210503151. 此Acunetix更新引入了Docker支持,针对每次扫描显示的新"扫描统计信息& ...
- Adaptive AUTOSAR 学习笔记 4 - 架构
本系列学习笔记基于 AUTOSAR Adaptive Platform 官方文档 R20-11 版本 AUTOSAR_EXP_PlatformDesign.pdf 缩写 AP:AUTOSAR Adap ...
- ROS2学习之旅(2)——配置ROS2环境
目录 1.source一下setup文件 2.自动source 3.自动进入工作区(不常用) 4.检查环境变量是否设置成功 5.总结 ROS2依赖于使用shell(终端)环境组合工作空间的概念.工作空 ...
- Android控件总结
最常用的控件:TextView.EditText.Button.ImageView TextView 文本 ...
- C语言:char 常量写法及变量赋值
#include <stdio.h> main() { char zfx_1,zfx_2,zfx_3,zfx_4,zfx_5,zfx_6,zfx_7,zfx_8; zfx_1='a';// ...
- xmind8 Mac序列号
1.首先去官网下载xmind8的安装包:XMind for Mac 也可以去我的百度网盘下载: 链接:https://pan.baidu.com/s/1eY52YsSaPmr-YFhB62Cli ...
- Kettle——shell交互命令
Kettle--shell交互命令 在kettle上开发了job或transform可以以单独的文件存在,也可以存放在资源库中.调用这些程序可以通过shell脚本调用,记录下: 资源库中的job: . ...
- 二进制方式安装 k8s
推荐个好用的安装k8s的工具 https://github.com/easzlab/kubeasz 该工具基于二进制方式部署 k8s, 利用 ansible-playbook 实现自动化 1.1 ...