MapReduce原理深入理解(一)
1.MapReduce概念
1)MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题.
2)MapReduce是分布式运行的,由两个阶段组成:Map和Reduce,Map阶段是一个独立的程序,有很多个节点同时运行,每个节点处理一部分数据。Reduce阶段是一个独立的程序,有很多个节点同时运行,每个节点处理一部分数据【在这先把reduce理解为一个单独的聚合程序即可】。
3)MapReduce框架都有默认实现,用户只需要覆盖map()和reduce()两个函数,即可实现分布式计算,非常简单。
4)两个函数的形参和返回值都是<key、value>,使用的时候一定要注意构造<k,v>。
2.MapReduce核心思想
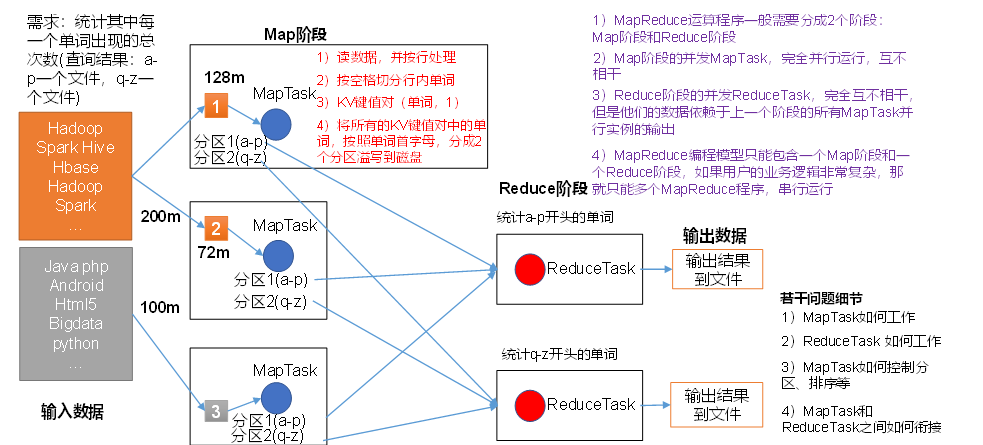
(1)分布式的运算程序往往需要分成至少2个阶段。
(2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。
(3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
(4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
总结:分析WordCount数据流走向深入理解MapReduce核心思想。

3. MapReduce 中的shuffle

4.Mapreduce代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class WordCount {
//分割任务
// 第一对kv,是决定数据输入的格式
// 第二队kv 是决定数据输出的格式
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
/*map阶段数据是一行一行过来的
每一行数据都需要执行代码*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
LongWritable longWritable = new LongWritable(1);
String s = value.toString();
context.write(new Text(s), longWritable);
}
}
//接收Map端数据
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
/* reduce 聚合程序 每一个k都会调用一次
* 默认是一个节点
* key:每一个单词
* values:map端 当前k所对应的所有的v
*/
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//设置统计的初始值为0
long sum = 0l;
for (LongWritable value : values) {
sum += value.get();
}
context.write(key, new LongWritable(sum));
}
} /**
* 是当前mapreduce程序入口
* 用来构建mapreduce程序
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//创建一个job任务
Job job=Job.getInstance();
//指定job名称
job.setJobName("第一个mr程序");
//构建mr
//指定当前main所在类名(识别具体的类)
job.setJarByClass(WordCount.class);
//指定map端类
// 指定map输出的kv类型
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//指定reduce端类
//指定reduce端输出的kv类型
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class); // 指定输入路径
Path in = new Path("/word");
FileInputFormat.addInputPath(job,in);
//输出路径指定
Path out = new Path("/output");
FileSystem fs = FileSystem.get(new Configuration());
//如果文件存在
if(fs.exists(out)){
fs.delete(out,true);
}
//存在
FileOutputFormat.setOutputPath(job,out); //启动
job.waitForCompletion(true);
System.out.println("MapReduce正在执行");
}
}
MapReduce原理深入理解(一)的更多相关文章
- MapReduce原理深入理解(二)
1.Mapreduce操作不需要reduce阶段 1 import org.apache.hadoop.conf.Configuration; 2 import org.apache.hadoop.f ...
- 大数据运算模型 MapReduce 原理
大数据运算模型 MapReduce 原理 2016-01-24 杜亦舒 MapReduce 是一个大数据集合的并行运算模型,由google提出,现在流行的hadoop中也使用了MapReduce作为计 ...
- MapReduce原理及其主要实现平台分析
原文:http://www.infotech.ac.cn/article/2012/1003-3513-28-2-60.html MapReduce原理及其主要实现平台分析 亢丽芸, 王效岳, 白如江 ...
- MapReduce 原理与 Python 实践
MapReduce 原理与 Python 实践 1. MapReduce 原理 以下是个人在MongoDB和Redis实际应用中总结的Map-Reduce的理解 Hadoop 的 MapReduce ...
- hadoop自带例子SecondarySort源码分析MapReduce原理
这里分析MapReduce原理并没用WordCount,目前没用过hadoop也没接触过大数据,感觉,只是感觉,在项目中,如果真的用到了MapReduce那待排序的肯定会更加实用. 先贴上源码 pac ...
- 04 MapReduce原理介绍
大数据实战(上) # MapReduce原理介绍 大纲: * Mapreduce介绍 * MapReduce2运行原理 * shuffle及排序 定义 * Mapreduce 最早是由googl ...
- Atitit 泛型原理与理解attilax总结
Atitit 泛型原理与理解attilax总结 1. 泛型历史11.1.1. 由来11.2. 为什么需要泛型,类型安全21.3. 7.泛型的好处22. 泛型的机制编辑22.1.1. 机制32.1.2. ...
- Hapoop原理及MapReduce原理分析
Hapoop原理 Hadoop是一个开源的可运行于大规模集群上的分布式并行编程框架,其最核心的设计包括:MapReduce和HDFS.基于 Hadoop,你可以轻松地编写可处理海量数据的分布式并行程序 ...
- Hadoop学习记录(4)|MapReduce原理|API操作使用
MapReduce概念 MapReduce是一种分布式计算模型,由谷歌提出,主要用于搜索领域,解决海量数据计算问题. MR由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce( ...
随机推荐
- 开源中国【面经】Java后台开发
2021.04.09 直接正文: 开场自我介绍,说一下自己 有没有实习经历?(毕业实习) 毕业实习学了什么?(前端) 有什么大项目吗?(除了课设就是毕设) 能说一下毕设的情况吗?(做了大概,没有开始登 ...
- 一种简易但设计全面的ID生成器思考
分布式系统中,全局唯一 ID 的生成是一个老生常谈但是非常重要的话题.随着技术的不断成熟,大家的分布式全局唯一 ID 设计与生成方案趋向于趋势递增的 ID,这篇文章将结合我们系统中的 ID 针对实际业 ...
- SQL 练习23
查询男生.女生人数 SELECT Ssex,COUNT(Ssex) 人数 from Student GROUP BY Ssex
- .net 温故知新:【5】异步编程 async await
1.异步编程 异步编程是一项关键技术,可以直接处理多个核心上的阻塞 I/O 和并发操作. 通过 C#.Visual Basic 和 F# 中易于使用的语言级异步编程模型,.NET 可为应用和服务提供使 ...
- CNN卷积神经网络详解
前言 在学计算机视觉的这段时间里整理了不少的笔记,想着就把这些笔记再重新整理出来,然后写成Blog和大家一起分享.目前的计划如下(以下网络全部使用Pytorch搭建): 专题一:计算机视觉基础 介 ...
- spring cloud 的hystrix 熔断器 和feign 调用的使用
1, 添加依赖 <dependency> <groupId>org.springframework.cloud</groupId> <artifactId&g ...
- uwp 的】listView 选择
xml 代码 ---------------------------------------------------------- <Page x:Class="ContentCont ...
- urllib3中学到的LRU算法
介绍 urllib3._collections.py::RecentlyUserContainer类,是一个线程安全的Dict类容器,用来维护一定数量(maxsize)的Key-Value映射, 当数 ...
- Ubuntu 系统安装、配置
windows下制作安装U盘 使用工具:Universal USB Installer ubuntu下制作安装U盘 使用工具:Startup Disk Creator(自带) 选择国内源:Switch ...
- 笔记本+ubuntu18.04 关闭触摸板touchpad
方法1: Settings -> Devices -> Mouse&Touchpad -> Touchpad OFF 方法2: 终端运行如下命令 touchpad off: ...