hdfs文件导入到hive(带资源)
前言
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行,下面来介绍如何将结构化文档数据导入hive。
一、安装Hive
1.1 官网下载或到本章最后地址下载hive 安装包
/opt/software 下新建hive 目录 并将安装包解压至此
tar -xzvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/software/hive
解压后的 hive 目录结构如下
1.2 添加环境变量
vim /etc/profile
文件末尾加上下面两行 分别为hive安装路径和引用
export HIVE_HOME=/usr/local/hive/apache-hive-3.1.2-bin
export PATH=$PATH:$HIVE_HOME/bin
使文件立即生效
source /etc/profile
1.3 进入hive 的jar包目录lib文件夹下
cd /usr/local/hive/apache-hive-3.1.2-bin/lib/
1.3.1 解决 log4j jar 包冲突
mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak
1.3.2 hive de guava-xx.jar 的guava-xx.jar 和hadoop的guava-xx.jar 包冲突,需要同步高版本jar,并删除低版本jar(两个jar包分别在/opt/hive/lib/ 以及 /opt/hadoop/share/hadoop/common/lib/)
1.3.3 添加mysql 驱动到hive 的 lib下(略)
1.4 修改配置文件
进入到hive安装目录conf下执行
mv hive-env.sh.template hive-env.sh
1.4.1 编辑hive-env.sh 配置hive_home
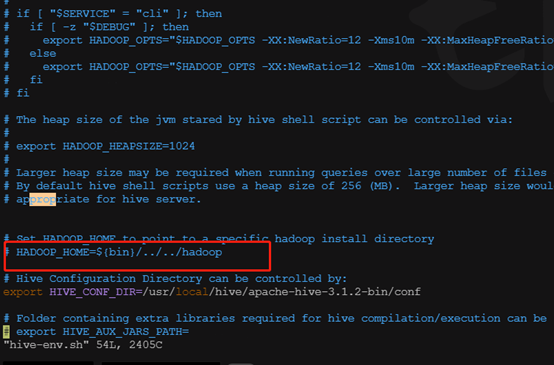
这里注意,如果hadoop和hive 不是安装在同一台机器上,会报错找不到hadoop_home,网上暂时没有找到好方案,暂时只能装在一起,所以这里不用配置
1.4.2 conf文件夹下配置hive-site.xml (如果无该文件,请自行创建 touch hive-site.xml)
<configuration>
<property>
<name>hive.server2.active.passive.ha.enable</name>
<value>true</value>
</property>
<!-- hive的相关HDFS存储路径配置 -->
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property> <property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/user/hive/log</value>
</property>
<!-- 以下是mysql相关配置 地址端口自行更改 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://ip:port/testhive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>userName</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>PASSWORD</value>
</property>
<!-- hive UI地址,不配置的话,默认只会在本机可以访问 -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>0.0.0.0</value>
</property>
</configuration>
1.5 后台启动hiveserver
nohup $HIVE_HOME/bin/hiveserver2 &

1.6 启动hive 自带client
bin/hive
进入hive 客户端

1.7 执行sql测试
hive> create table emp(
> id int,
> name string);
hive> insert into emp values(1,"lisi"); hive> select * from emp;
OK
1 lisi
Time taken: 0.395 seconds, Fetched: 1 row(s)
正常!
二 、 将hdfs中的文件导入hive
2.1 新建emp表,指定以空格切分字段,以换行切分数据条数
hive> create table student(
> id int,
> name string)
> row format delimited
> fields terminated by ' '
> lines terminated by '\n';
2.2 准备要导入的文件
先找到hdfs文件路径
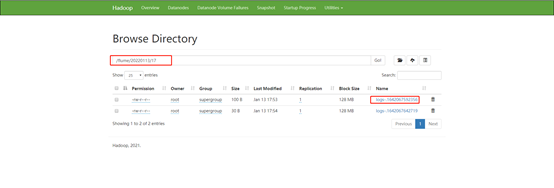
可以在Hadoop(Utilities-Browse the file system)上看到本次要导入的文件路径为 /flume/20220113/13/logs-.1642052912087
2.3 执行导入命令
hive> load data inpath '/flume/20220113/13/logs-.1642052912087' INTO TABLE emp;
Loading data to table default.emp
OK
执行查询emp语句,可以看到数据以成功导入
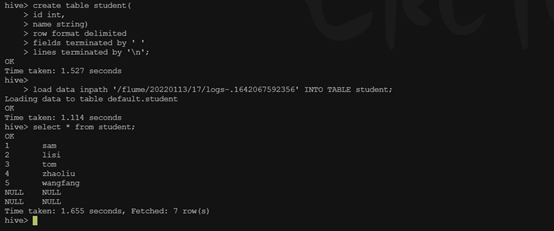
下面为hdfs 源文件(test.log)
1 sam
2 lisi
3 tom
4 zhaoliu
5 wangfang
到hadoop 控制台可以看到hive 的表文件
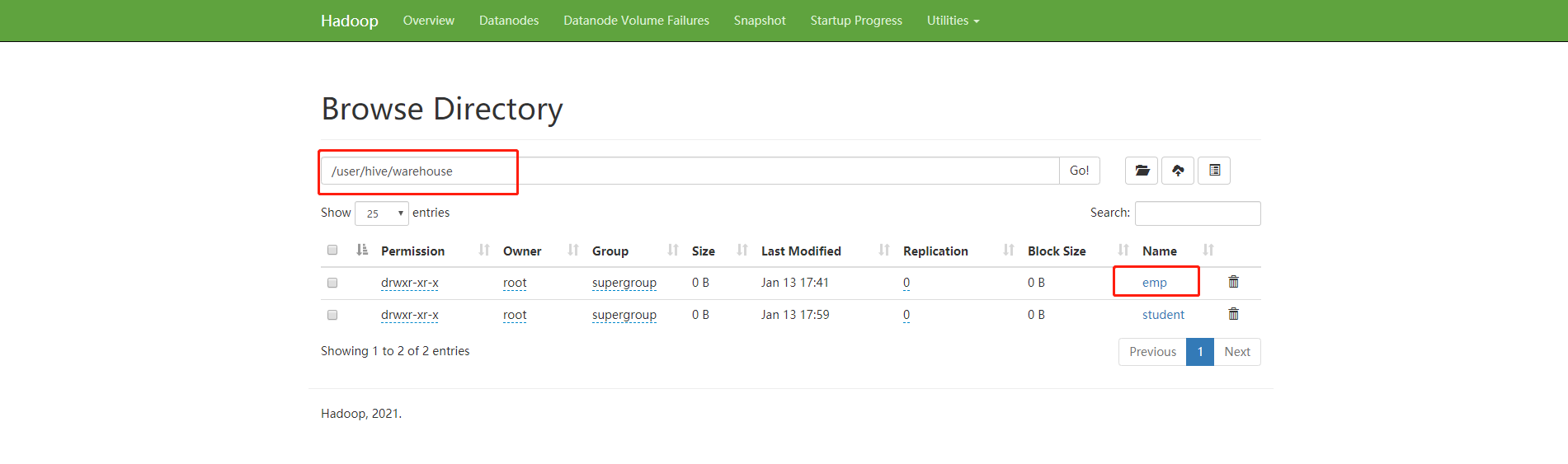
结束!
hive 安装包下载地址
链接:https://pan.baidu.com/s/1CIBq7V6m4yH7TYmI0tacRQ
提取码:6666
hdfs文件导入到hive(带资源)的更多相关文章
- [Spark][Hive]外部文件导入到Hive的例子
外部文件导入到Hive的例子: [training@localhost ~]$ cd ~[training@localhost ~]$ pwd/home/training[training@local ...
- 将CSV格式或者EXCEL格式的文件导入到HIVE数据仓库中
学习内容:数据导入,要求将CSV格式或者EXCEL格式的文件导入到HIVE数据仓库中: ①hive建表:test1 create table test1 (InvoiceNo String, Stoc ...
- 将CSV文件导入到hive数据库
将csv文件导入hive后出现了所有的字段只显示在新建的表的第一个字段中,后面的字段全是null. 出现这种的原因是hive以行分隔数据,需要修改为按逗号' , ‘ 进行分隔读取, 具体操作如下, ...
- Talend 将Oracle中数据导入到hive中,根据系统时间设置hive分区字段
首先,概览下任务图: 流程是,先用tHDFSDelete将hdfs上的文件删除掉,然后将oracle中的机构表中的数据导入到HDFS中:建立hive连接->hive建表->tJava获取系 ...
- 11.把文本文件的数据导入到Hive表中
先在hive里面创建一个表 create table mydb2.t3(id int,name string,age int) row format delimited fields terminat ...
- sqoop命令,mysql导入到hdfs、hbase、hive
1.测试MySQL连接 bin/sqoop list-databases --connect jdbc:mysql://192.168.1.187:3306/trade_dev --username ...
- 第3节 sqoop:4、sqoop的数据导入之导入数据到hdfs和导入数据到hive表
注意: (1)\001 是hive当中默认使用的分隔符,这个玩意儿是一个asc 码值,键盘上面打不出来 (2)linux中一行写不下,可以末尾加上 一些空格和 “ \ ”,换行继续写余下的命令: bi ...
- 如何快速把hdfs数据动态导入到hive表
1. hdfs 文件 {"retCode":1,"retMsg":"Success","data":[{" ...
- HDFS文件和HIVE表的一些操作
1. hadoop fs -ls 可以查看HDFS文件 后面不加目录参数的话,默认当前用户的目录./user/当前用户 $ hadoop fs -ls 16/05/19 10:40:10 WARN ...
随机推荐
- Hyper-v安装Centos7
开篇语 知识库地址:https://azrng.gitee.io/kbms 介绍 可以让你在你的电脑上以虚拟机的形式运行多个操作系统(至于为什么选择这个,主要是系统已经自带了,所以能不装其他我就先不装 ...
- CF667A Pouring Rain 题解
Content 一个水桶直径为 \(d\) 厘米,初始时水面高度为 \(h\) 厘米.你每秒钟喝 \(v\) 毫升水,而由于下雨,水桶里面的水在不喝水的时候每秒会上升 \(e\) 厘米.求你最少需要多 ...
- python 快速启动http监听服务
python3 [root@vm10-20-9-45 ~]# python3 -m http.server 2378 Serving HTTP on 0.0.0.0 port 2378 (http:/ ...
- mysql如何查询某个库,某个表都有哪些字段
如下语句便可查看 SELECT column_name FROM Information_schema.columns WHERE table_Name = 'columns' AND TABLE_ ...
- host-manager does not exist or is not a readable directory
当tomcat启动出现这个错误时,按照如下步骤可以解决: 1.删掉F:\tomcat20111101\apache-tomcat-6.0.26\conf\Catalina目录下的localhost文件 ...
- centos使用docker安装ActiveMQ
拉取镜像 docker pull webcenter/activemq 启动镜像 docker run --name=activemq -itd -p 8161:8161 -p 61616:61616 ...
- JAVA判断某个元素是否在某个数组中
先把数组转为list 然后再利用contains方法 String[] strArr = new String[] { "a1", "b1", "c1 ...
- 【LeetCode】72. Edit Distance 编辑距离(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 递归 记忆化搜索 动态规划 日期 题目地址:http ...
- 【LeetCode】738. Monotone Increasing Digits 解题报告(Python)
[LeetCode]738. Monotone Increasing Digits 解题报告(Python) 标签(空格分隔): LeetCode 作者: 负雪明烛 id: fuxuemingzhu ...
- 【LeetCode】840. Magic Squares In Grid 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 利用河图规律 暴力解法 日期 题目地址:https: ...