Kafka经典三大问:数据有序丢失重复
Kafka经典三大问:数据有序丢失重复
在kafka中有三个经典的问题:
- 如何保证数据有序性
- 如何解决数据丢失问题
- 如何处理数据重复消费
这些不光是面试常客,更是日常使用过程中会遇到的几个问题,下面分别记录一下产生的原因以及如何解决。
1. 消息有序
kafka 的数据,在同一个partition下是默认有序的,但在多个partition中并不一定能够保证其顺序性。kafka因为其自身的性质,适合高吞吐的流式大数据,对数据有序性要求不严格的场景比较适用。
1.1. 为什么只保证单partition有序?
如果Kafka要保证多个partition有序,不仅broker保存的数据要保持顺序,消费时也要按序消费。假设partition1堵了,为了有序,那partition2以及后续的分区也不能被消费,这种情况下,Kafka 就退化成了单一队列,毫无并发性可言,极大降低系统性能。因此Kafka使用多partition的概念,并且只保证单partition有序。这样不同partiiton之间不会干扰对方。
1.2. 解决方式
kafka自身没有提供整个topic级别的消息顺序性,但我们可以在业务层面来处理。
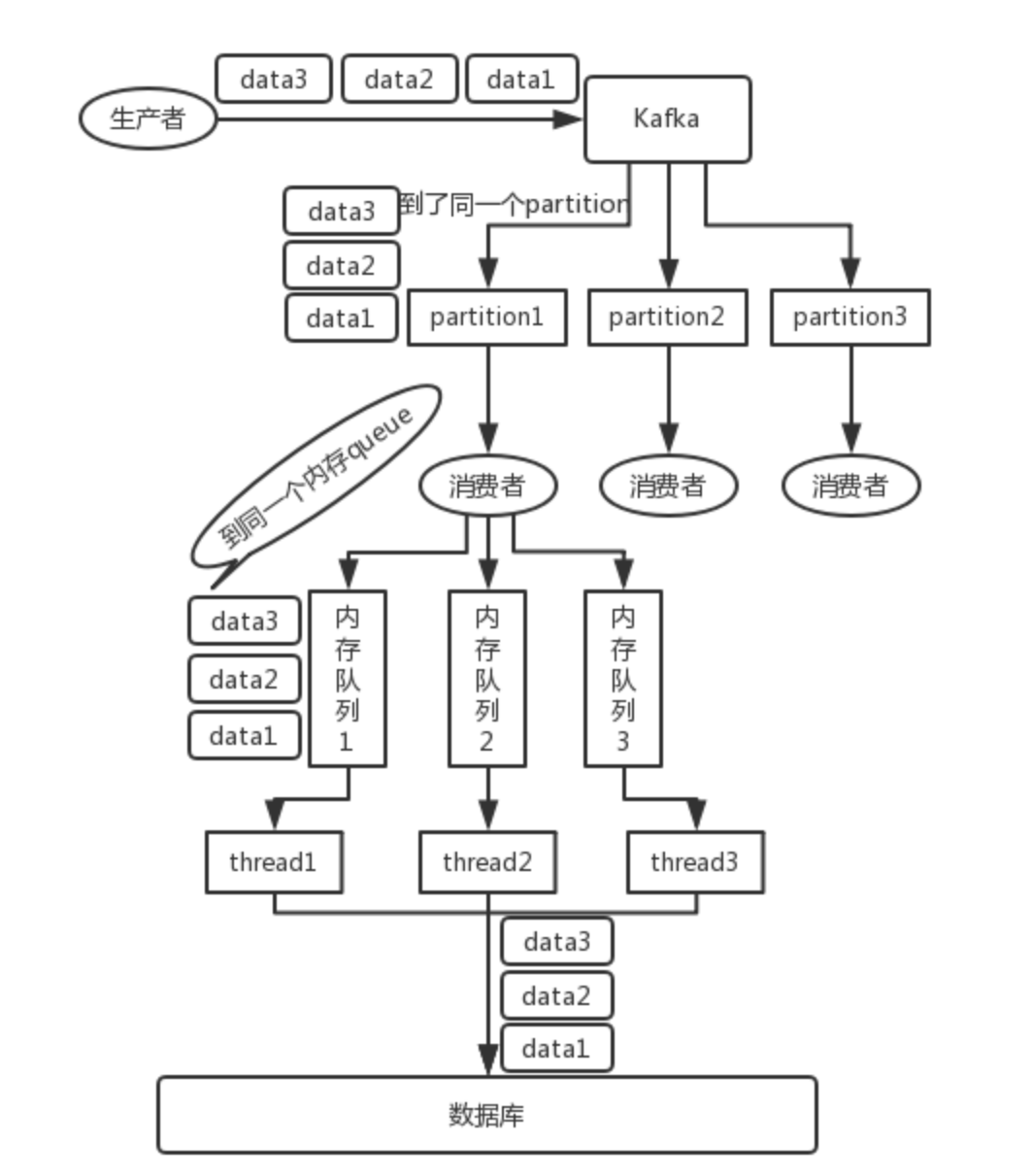
可以通过message key来保证你需要保持顺序性的数据发送到同一个partition,即send方法,可以指定三个参数(topic, partition, key), partition和key是可选的,如果指定了同一个partition的话,那么数据就是有序的。
同时在消费端,只创建一个消费者来消费topic,但后续的话这个消费者可以写入N个内存队列,保证具有相同key的数据写入同一个内存队列即可。引入内存队列是为了解决业务处理单线程处理太慢的问题,多个内存队列可以起多个线程进行消费,同时具有相同key的数据在同一个内存队列中,这样就能保证顺序性。
2. 数据丢失
丢失数据一般分为两种情况:mq自己弄丢了,业务处理弄丢了。
2.1. kafka弄丢了数据
kafka的某个broker宕机,重新选举partition的leader时,如果其他的follower还没有完成数据同步,此时leader挂了,那么就有可能造成数据丢失的问题。
kafka提供了几个参数来保证数据不丢失:
replication.factor:分区副本数,最低设置为2,即要求每个Partition至少拥有两个副本;min.insync.replicas:要求一个leader感知到有至少一个follower还跟自己保持联系,没掉队,这样才能确保leader挂了还有一个follower;acks:在producer发送数据成功后,kafka会给生产者返回一个ack信息,这个称为kafka的ack机制;ack有3个可选值,-1、0、1;
ack=1:producer只要收到一个分区副本写入成功的通知就认为推送消息成功,这个分区副本特指leader副本;
ack=0:producer发送一次就不再发送了,不管是否发送成功;
ack=-1:producer只有收到分区内所有副本的成功写入通知才算推送消息成功;
retries:重试次数,如果写入失败就会进行重试,直到超过retries设置的值;
2.2. 消费端弄丢了数据
例如消费者已经获取到这个数据,并且提交了offset,但后续在对数据进行业务操作的时候挂掉了,导致数据没有成功处理,这时候kafka认为你已经成功获取了,但实际没有,就造成了数据丢失的问题。
一般情况下用手动提交的方式来解决,当数据处理成功后再提交offset。
3. 重复消费
在ack=1的情况下,是有可能存在消息丢失的情况的,因为producer收到leader写入成功的通知就认为推送成功,但实际上leader副本在把消息同步到follower副本的时候失败了,这时候消息就丢失了。
为了处理这种推送失败的情况,kakfa引入了回调机制来处理,实际上就是一种重试的方式,这时候会出现因为重试机制导致消息乱序的情况。
3.1. 解决重试机制引起的消息乱序
生产者Producer
为了实现producer的幂等性,kafka引入了Producer ID和Sequence Number两个参数,对于每个生产者,该Producer发送的消息都对应一个单调增的Sequence Number。同样的Broker端也会为每个生产者的每条消息维护一个序号,并且每commit一条数据时就会将其序号递增。
对于接收到的数据,如果其序号比Borker维护的序号大一(即表示是下一条数据),Broker会接收它,否则将其丢弃。
如果消息序号比Broker维护的序号差值比一大,说明中间有数据尚未写入,即乱序,此时Broker拒绝该消息,Producer抛出InvalidSequenceNumber
如果消息序号小于等于Broker维护的序号,说明该消息已被保存,即为重复消息,Broker直接丢弃该消息,Producer抛出DuplicateSequenceNumber
Sender发送失败后会重试,这样可以保证每个消息都被发送到broker
消费者Consumer
同样的也是利用幂等性的原理来解决,可以给每条数据加上一个唯一标识,进行数据处理的时候校验这个标识是否存在,如果存在即为重复数据,丢弃。
Kafka经典三大问:数据有序丢失重复的更多相关文章
- [转帖]kafka 如何保证数据不丢失
kafka 如何保证数据不丢失 https://www.cnblogs.com/MrRightZhao/p/11498952.html 一般我们在用到这种消息中件的时候,肯定会考虑要怎样才能保证数 ...
- kafka 如何保证数据不丢失
一般我们在用到这种消息中件的时候,肯定会考虑要怎样才能保证数据不丢失,在面试中也会问到相关的问题.但凡遇到这种问题,是指3个方面的数据不丢失,即:producer consumer 端数据不丢失 b ...
- Kafka在高并发的情况下,如何避免消息丢失和消息重复?kafka消费怎么保证数据消费一次?数据的一致性和统一性?数据的完整性?
1.kafka在高并发的情况下,如何避免消息丢失和消息重复? 消息丢失解决方案: 首先对kafka进行限速, 其次启用重试机制,重试间隔时间设置长一些,最后Kafka设置acks=all,即需要相应的 ...
- Oracle Goldengate是如何保证数据有序和确保数据不丢失的?
工作中一直在用Oracle 的中间件Oracle GondenGate 是如何保证消息的有序和不丢失呢? Oracle GoldenGate逻辑架构 首先,先看一下Oracle GoldenGate ...
- Spark Streaming消费Kafka Direct方式数据零丢失实现
使用场景 Spark Streaming实时消费kafka数据的时候,程序停止或者Kafka节点挂掉会导致数据丢失,Spark Streaming也没有设置CheckPoint(据说比较鸡肋,虽然可以 ...
- Spark Streaming和Kafka整合保证数据零丢失
当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢失机制.为了体验这个关键的特性,你需要满足以下几个先决条件: 1.输入的数据来自可靠的数据源 ...
- Spark Streaming使用Kafka保证数据零丢失
来自: https://community.qingcloud.com/topic/344/spark-streaming使用kafka保证数据零丢失 spark streaming从1.2开始提供了 ...
- Kafka如何保证数据不丢失
Kafka如何保证数据不丢失 1.生产者数据的不丢失 kafka的ack机制:在kafka发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够被收到,其中状态有0,1,-1. 如果是 ...
- 160728、Spark Streaming kafka 实现数据零丢失的几种方式
定义 问题开始之前先解释下流处理中的一些概念: At most once - 每条数据最多被处理一次(0次或1次) At least once - 每条数据最少被处理一次 (1次或更多) Exactl ...
随机推荐
- 实习之bii--配置esxi重启时,虚拟机也跟随重启
由于初创环境不稳定又是服务器会重启,而内部安装的多部虚拟机并不默认跟随启动,需要设置,方法如下: 1.在本地通过vsphere client 登录到esxi的服务器上,然后点击配置找到虚拟机启动/关机 ...
- golang中的标准库flag
Go语言内置的flag包实现了命令行参数的解析,flag包使得开发命令行工具更为简单. os.Args 如果你只是简单的想要获取命令行参数,可以像下面的代码示例一样使用os.Args来获取命令行参数. ...
- 集合框架-工具类-JDK5.0特性-函数可变参数
1 package cn.itcast.p4.news.demo; 2 3 public class ParamterDemo { 4 5 public static void main(String ...
- 不难懂------react-flux
一.什么是Flux Flux 是一种架构思想,专门解决软件的结构问题.它跟MVC 架构是同一类东西,但是更加简单和清晰. 二.flux的基本概念 (1) .Flux由4部分组成 1.View:视图层 ...
- 不难懂------适配移动端flexible
基于 vue-cli 配置手淘的 lib-flexible + rem,实现移动端自适应 安装 flexible npm install lib-flexible --save 引入 flexible ...
- PowerDotNet平台化软件架构设计与实现系列(12):HCRM人员管理平台
技术服务于业务,良好的技术设计和实现能够大幅提升业务质量和效率. PowerDotNet已经形成了自己的开发风格,很多项目已被应用于生产环境,可行性可用性可靠性都得到了生产环境验证. 编程是非常讲究动 ...
- 负载均衡的比例(权重,ip_hash,轮询)
目录 一:负载均衡的比例 1.轮询 2.权重 3.ip_hash 二:测试轮询 1.测试 2.重启 3.网址测试 三:测试ip_hash 一:负载均衡的比例 1.轮询 # 默认情况下,Nginx负载均 ...
- 合宙AIR105使用Keil MDK + DAP-Link 烧录和调试
关于AIR105 AIR105是合宙LuatOS生态下的一款芯片, 1月初上市, 开发板与摄像头一起搭售(赠送). 从配置信息看, 芯片性能相当不错: Cortex-M4F内核, 最高频率204Mhz ...
- Nginx实现跨域配置详解
主要给大家介绍了关于Nginx跨域使用字体文件的相关内容,分享出来供大家参考学习,下面来一起看看详细的介绍: 问题描述 今天在使用子域名访问根域名的CSS时,发现字体无法显示,在确保CSS和Font字 ...
- 2019年1月9日 ES6 学习心得
ES6为我们创建对象提供了新的语法糖,这就是Class语法.如果你对ES5中面向对象的方式比较熟悉的话,Class掌握起来也是非常迅速的,因为除了写法的不同,它并不会增加新的难以理解的知识点.我们先利 ...