Python学习笔记总结
Python学习笔记总结
前言
由于有其他高级语言的开发经验,所以入门学起来就快很多,不用像初学那样详细的看,我根据《Python编程:从入门到实践(第2版)》做个简单笔记总结。
安装
安装就不记录了,傻瓜式的下载Python安装包,然后运行python来确定是否已经添加到环境变量、安装完毕,当然还要安装pip.

数据类型
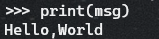
Hello,World
先来写个简单的Hello,World看看
msg = "Hello,World!"
print(msg)
变量
和其他高级语言意思一样,Python推荐命名规范用下划线划分单词,比如greeting_message,有空格会引发错误比如greeting message.
字符串
在编程中最常用的应该就是字符串相关的处理了。
Python中推荐字符串用""来包括单引号,用'来包括双引号,比如:
"The language `Python` is named after Monty Python,not the snake."
'I told my friend,"Python is my favorite language!"'
首字母大写
name = "ada lovelace"
print(name.title())
#输出
Ada Lovelace
全部小写
name = "Ada Lovelace"
print(name.lower())
#输出
ada lovelace
全部大写
name = "Ada Lovelace"
print(name.upper())
#输出
ADA LOVELACE
Tab和换行符
hello="\thello,world!\r\n"
print(hello)
#输出
hello,world!
格式化
first_name = "ada"
last_name = "lovelace"
full_name = f"{first_name} {last_name}"
print(full_name)
#也可以用format
first_name = "ada"
last_name = "lovelace"
full_name = "{0} {1}".format(first_name,last_name)
print(full_name)
去除空格
#删除左边空格
s = ' hello,world '
print(s.lstrip())
#删除右边空格
print(s.rstrip())
#删除两端的空格
print(s.strip())
'hello,world '
' hello,world'
'hello,world'
List列表
列表由一系列按特定顺序排列的元素组成。你可以创建包含字母表中所有字母、数字0~9或所有家庭成员姓名的列表;也可以将任何东西加入列表中,其中的元素之间可以没有任何关系。
列表增删改查排序
list.append('添加某元素')
list.insert('插入某元素')
del list[0] #删除元素
print(list[0]) #打印元素
print(list.pop(0)) #打印弹出的值
list.remove('删除某值元素')
list.sort()#进行字母排序
list.sorted()#进行临时排序
list.reverse()#倒序
遍历列表
mobiles = ['小米','华为','Oppo','iPhone','Vivo']
print(mobiles[3])
for mobile in mobiles:
print(f"{mobile},",end='')
#还可以用range 创建数值列表
for value in range(1,5):
print(value)
#对数值列表进行统计计算
digits=[1,2,3,4,5,6,7,8,9]
min(digits)
max(digits)
sum(digits)
Slice切片
处理列表的部分元素,Python称之为切片。
mobiles = ['小米','华为','Oppo','iPhone','Vivo']
#切片练习
print("输出前3个元素:")
print(mobiles[0:3])
print("索引位置从1开始,到索引4位置结束")
print(mobiles[1:4])
print("从列表头开始,到索引4位置结束")
print(mobiles[:4])
print("索引位置从2开始,到列表尾")
print(mobiles[2:])
print("负数索引,从末尾开始")
print(mobiles[-3:])

遍历切片
mobiles = ['小米','华为','Oppo','iPhone','Vivo']
#遍历切片
for mobile in mobiles[:3]: #遍历3个元素
print(mobile)
for re_mobile in mobiles[-3:]: #遍历倒数3个元素
print(re_mobile)
复制列表
我们经常需要根据既有列表创建全新的列表。下面来介绍复制列表的工作原理,以及复制列表可提供极大帮助的一种情形。
要复制列表,可创建一个包含整个列表的切片,方法是同时省略起始索引和终止索引([:])
my_foods = ['pizza','falafel','carrot cake']
friend_foods = my_foods[:] #复制了一份我的食物
friend_foods.append('ice cream')
print(my_foods)
print(friend_foods)
Tup元组
元组看起来很像列表,但使用圆括号而非中括号来标识。定义元组后,就可使用索引来访问其元素,就像访问列表元素一样。
例如,如果有一个大小不应改变的矩形,可将其长度和宽度存储在一个元组中,从而确保它们是不能修改的:
dimensions=(200,50,1,23,4,5,6,7)
print(dimensions[0])
print(dimensions[1])
#遍历元组数据
for dimension in dimensions:
print(dimension)
修改元组变量
虽然不能修改元组的元素,但可以给存储元组的变量赋值。因此,如果要修改前述矩形的尺寸,可重新定义整个元组:
dimensions = (1,2,3,4,5)
for dimension in dimensions:
print(dimension)
#修改
dimensions = (2,3,4,5,6)
for dimension in dimensions:
print(dimension)
Dictionary字典
在Python中,字典是一系列键值对。每个键都与一个值相关联,你可使用键来访问相关联的值。与键相关联的值可以是数、字符串、列表乃至字典。事实上,可将任何Python对象用作字典中的值。
tel = {'jack':4098,'space':4139}
tel['guido'] = 4127
tel['space'] = 4056
print(tel)#打印字典
print(tel['jack'])#访问字典的值
del tel['space']#删除键值space的字典
print(list(tel)) #遍历字典键值
if 'jack' in tel:
print("yes")
else:
print("no")
#通过get函数来避免报错
test_key = tel.get('test','no key')
print(test_key)
遍历字典
一个Python字典可能只包含几个键值对,也可能包含数百万个键值对。鉴于字典可能包含大量数据,Python支持对字典进行遍历。字典可用于以各种方式存储信息,因此有多种遍历方式:可遍历字典的所有键值对,也可仅遍历键或值。
knights = {'gallahad': 'the pure', 'robin': 'the brave'}
for k,v in knights.items():
print(f"\nKey:{k}")
print(f"\nValue:{v}")
#遍历所有键 Key
for name in knights.keys():
print(key.title())
#遍历所有值 Value
for knight in knights.values():
print(knight.title())
#按照顺序遍历
for name in sorted(knights.keys()):
print(key.title())
While循环
for循环用于针对集合中的每个元素都执行一个代码块,而While循环则不断运行,直到指定的条件不满足为止。
current_number = 1
while current_number <= 5:
print(current_number)
current_number += 1
让用户来选择何时退出!
msg = "\nTell me something, and I will repeat it back to you:"
msg += "\nEnter 'quit' to end the program. "
message = ""
while message != 'quit':
message = input(msg)
print(message)
用While循环处理列表和字典
#创建一个待验证用户列表
unconfirmed_users = ['alice','brian','candace']
#用来存储已验证的用户列表
confirmed_users = []
while unconfirmed_users:
current_user = unconfirmed_users.pop()
print(f"Verifying user:{current_user.title()}")
confirmed_users.append(current_user)
#显示所有已经验证过的用户
print("\nThe following users have been confirmed:")
for confirmed_user in confirmed_users:
print(confirmed_user.title())
def 函数
定义函数
使用关键字def来告诉Python,你要定义一个函数。
def greet_user():
"""显示简单的问候语"""
print("Hello!")
greet_user()
传递参数
def greet_user(username):
"""像谁问好"""
print(f"Hello! {username}")
greet_user("Hacker!")
形参和实参
在函数greet_user()的定义中,变量username是一个形参(parameter),即函数完成工作所需的信息。在代码greet_user('jesse')中,值'jesse'是一个实参(argument)
调用函数时,Python必须将函数调用中的每个实参都关联到函数定义中的一个形参。为此,最简单的关联方式是基于实参的顺序。这种关联方式称为位置实参。
def describe_pet(animal_type,pet_name):
"""显示宠物的信息."""
print(f"\nI have a {animal_type}.")
print(f"My {animal_type}'s name is {pet_name.title()}'.")
describe_pet('hamster','harry')
关键字实参
关键字实参是传递给函数的名称值对。因为直接在实参中将名称和值关联起来,所以向函数传递实参时不会混淆。关键字实参的顺序无关紧要.
def describe_pet(animal_type,pet_name):
"""显示宠物的信息。"""
print(f"\nI have a {animal_type}.")
print(f"My {animal_type}'s name is {pet_name.title()}.'")
describe_pet(pet_name='harry',animal_type='hamster')
默认值
编写函数时,可给每个形参指定默认值。这个在其他高级语言里面也有,就是定义函数的时候直接给形参赋值了。
def describe_pet(animal_type,pet_name='dog'):
"""显示宠物的信息。"""
print(f"\nI have a {animal_type}.")
print(f"My {animal_type}'s name is {pet_name.title()}.'")
describe_pet('willie')
返回值
Python的函数的返回值和C++的不太一样,C++在定义函数的时候必须要明确的声明返回的是什么类型,而Python是根据return 关键字来判断你需要返回什么类型。
def test():
return 1
print(test()+2)
禁止函数修改列表
有时候,需要禁止函数修改列表,可向函数传递列表的副本而非原件。
def function_name(list_name[:]):
...
class 类
Python中和其他语言一样,用关键字class来定义一个类。
__init__方法,这个类似C++中的构造函数,self类似C++中的this指针,python中声明定义熟悉直接在__init__中用self来定义.
class Dog:
"""一次模拟小狗的简单尝试"""
def __init__(self,name,age):
"""初始化属性name和age,类似构造函数"""
self.name = name
self.age = age
def sit(self):
"""模拟小狗收到命令时蹲下!"""
print(f"{self.name.title()} is now sittring.")
def roll_over(self):
"""模拟小狗收到命令时打滚。"""
print(f"{self.name.title()} rolled over!")
my_dog = Dog('Willie',6)
print(f"My dog's name is {my_dog.name}.")
print(f"My dog is {my_dog.age} years old.")
my_dog.sit()
my_dog.roll_over()
继承
面向对象的灵魂三大要素:封装、继承、多态,所以在class中继承必不可少.
在python中,在既有类的基础上编写新类时,通常要调用父类的方法__init__()。这将初始化在父类__init__()方法中定义的所有属性,从而让子类包含这些属性.
子类继承父类的关键字:(父类),在子类中可以用super()来调用父类的方法.
class Animal:
def __init__(self,name,age):
self.name = name
self.age = age
def eat(self):
print(f"eating....")
def run(self):
print(f"running....")
def sleep(self):
print(f"sleeping....")
class Dog(Animal):
def __init__(self,name,age):
self.tails = True
super().__init__(name,age)
def roll_over(self):
"""模拟小狗收到命令时打滚。"""
print(f"{self.name.title()} rolled over!")
my_dog = Dog('Willie',6)
print(f"My dog's name is {my_dog.name}.")
print(f"My dog is {my_dog.age} years old.")
print(f"My dog's tails is {my_dog.tails}.")
my_dog.eat()
my_dog.run()
my_dog.sleep()
my_dog.roll_over()
模块
模块就是单独的一个类文件,将类写在了.py文件中.
car模块
"""一个用户表示汽车的类"""
class Car:
"""一次模拟汽车的尝试。"""
def __init__(self,make,model,year):
"""初始化描述汽车的属性。"""
self.make = make
self.model = model
self.year = year
self.odometer_reading = 0
def get_descriptive_name(self):
"""返回整洁的描述性名称。"""
long_name = f"{self.year} {self.make} {self.model}"
return long_name.title()
def read_odometer(self):
"""打印一条消息,指出汽车的里程。"""
print(f"This car has {self.odometer_reading} miles on it.")
def update_odometer(self,mileage):
"""
将里程表读数设置为指定的值。
拒绝将里程表往回调。
"""
if mileage >= self.odometer_reading:
self.odometer_reading = mileage
else:
print("You can't roll back an odometer!")
def increment_odometer(self,miles):
"""将里程表读数增加指定的量"""
self.odometer_reading += miles
my_car.py代码
此处的import语句让python打开模块car并且导入其中的Car类,因为在一个模块中可能包含多个类 class
from car import Car
my_new_car = Car('audi','a4',2019)
print(my_new_car.get_descriptive_name())
my_new_car.odometer_reading = 23
my_new_car.read_odometer()
导入类是一种有效的编程方式。如果这个程序包含整个Class类,它该有多长啊!通过将这个类移到一个模块中并导入该模块,依然可以使用其所有功能,但主程序文件变得整洁而易于阅读了。这还让你能够将大部分逻辑存储在独立的文件中。确定类像你希望的那样工作后,就可以不管这些文件,而专注于主程序的高级逻辑了。
导入模块中的多个类
利用逗号分隔,可以导入模块中的多个类。
from car import Car,..,....
导入整个模块
可以直接用import导入整个模块
import car #可以使用car模块中的所有类
car.Car()#使用Car类
导入模块中的所有类
不推荐这种做法,因为这种方式可能引发名称方面的迷惑,如果不小心导入了一个与程序文件中其他东西同名的类,将引发难以诊断的错误。
需要从一个模块中导入很多类时,最好导入整个模块
from module_name import *
使用别名
使用模块来组织项目代码时,别名大有裨益。导入类时,也可为其指定别名。
例如,要在程序中创建大量电动汽车实例,需要反复输入ElectricCar,非常烦琐。为避免这种烦恼,可在import语句中给ElectricCar指定一个别名:
from electric_car import ElectricCar as EC
文件操作
Python open() 函数用于打开一个文件,创建一个 file 对象,相关的方法才可以调用它进行读写。
和C语言中的差不多,前面是打开文件的路径,后面是打开文件的方式,as上面说过用来创建别名,那么file_object即使他的对象名。
显式地调用close关闭了这个文件句柄,但前提是只有在read成功的情况下。如果有任意异常正好在f = open(...)之后产生,f.close()将不会被调用(取决于Python解释器的做法,文件句柄可能还是会被归还,但那是另外的话题了)。为了确保不管异常是否触发,文件都能关闭,我们将其包裹成一个with语句:
with open('hello.txt') as file_object:
text = file_object.read()
print(text)
bytes类型和str互相转换
bytes
Python中bytes表示字节序列(二进制形式),是一个不可变的数据类型,对应的可变形式是bytearray,也就是字节数组。
可以通过字符串来创建 bytes 对象,或者说将字符串转换成 bytes 对象有以下三种方法可以达到这个目的:
- 如果字符串的内容都是 ASCII 字符,那么直接在字符串前面添加
b前缀就可以转换成 bytes。 bytes 是一个类,调用它的构造方法,也就是bytes(),可以将字符串按照指定的字符集转换成 bytes;如果不指定字符集,那么默认采用 UTF-8。- 字符串本身有一个
encode()方法,该方法专门用来将字符串按照指定的字符集转换成对应的字节串;如果不指定字符集,那么默认采用 UTF-8
#通过构造函数创建空 bytes
b1 = bytes()
#通过空字符串创建空 bytes
b2 = b''
#通过b前缀将字符串转换成 bytes
b3 = b'http://c.biancheng.net/python/'
print("b3: ", b3)
print(b3[3])
print(b3[7:22])
#为 bytes() 方法指定字符集
b4 = bytes('C语言中文网8岁了', encoding='UTF-8')
print("b4: ", b4)
#通过 encode() 方法将字符串转换成 bytes
b5 = "C语言中文网8岁了".encode('UTF-8')
print("b5: ", b5)
运行结果:
b3: b'http://c.biancheng.net/python/'
112
b'c.biancheng.net'
b4: b'C\xe8\xaf\xad\xe8\xa8\x80\xe4\xb8\xad\xe6\x96\x87\xe7\xbd\x918\xe5\xb2\x81\xe4\xba\x86'
b5: b'C\xe8\xaf\xad\xe8\xa8\x80\xe4\xb8\xad\xe6\x96\x87\xe7\xbd\x918\xe5\xb2\x81\xe4\xba\x86'
bytes.decode()方法
#通过 encode() 方法将字符串转换成 bytes
print(b5.decode('UTF-8'))
运行结果:
b5: C语言中文网8岁了
python中字节字符和非字节字符
python3中默认输入字符串以非字节字符编码,使用unicode字符集表示,可以使用encode方法转化为ascii,utf-8, utf-16等各种编码形式的字节字符;因此仅非字节字符才被python3认为是标准字符串.
Python 3.5.2 (default, Nov 23 2017, 16:37:01)
[GCC 5.4.0 20160609] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> uni_str = 'abc'
>>> type(uni_str)
<class 'str'>
>>> utf8_str = uni_str.encode('utf-8')
>>> type(utf8_str)
<class 'bytes'>
>>> asc_str = uni_str.encode('utf-8')
>>> type(asc_str)
<class 'bytes'>
>>> uni_str
'abc'
>>> utf8_str
b'abc'
>>> asc
asc_str ascii(
>>> asc_str
b'abc'
python2中输入字符串默认使用ascii编码的字节字符,因此默认不支持中文(存疑),可以使用decode方法将默认字节编码的字符串转化为非字节字符,使用unicode字符集表示,进而使用encode方法将unicode字符集的非字节字符转化为其他编码形式的字符如utf-8, utf-16;因此编码后字符串,即字节字符才被python2认为是字符串格式
Python 2.7.12 (default, Dec 4 2017, 14:50:18)
[GCC 5.4.0 20160609] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> str = 'abc'
>>> type(str)
<type 'str'>
>>> uni_str = str.decode('ascii')
>>> uni_str
u'abc'
>>> type(uni_str)
<type 'unicode'>
>>> utf8_str = uni_str.encode('utf-8')
>>> utf8_str
'abc'
>>> type(utf8_str)
<type 'str'>
Struct解析二进制数据
有的时候需要用python处理二进制数据,比如,存取文件,socket操作时.这时候,可以使用python的struct模块来完成.可以用 struct来处理c语言中的结构.
官方解释是:在Python值和C结构之间转换的函数。Python bytes对象用于保存表示C结构的数据
直白一点,在c语言中c语言包含不同类型的数据(int,char,bool等等),方便对某一结构对象进行处理。而在网络通信当中,大多传递的数据是以二进制流(binary data)存在的。当传递字符串时,那你就需要有一种机制将某些特定的结构体类型打包成二进制流的字符串然后再网络传输,而接收端也应该可以通过某种机制进行解包还原出原始的结构体数据。python中的struct模块就提供了这样的机制,该模块的主要作用就是对python基本类型值与用python字符串格式表示的C struct类型间的转化,以下原话来自https://www.cnblogs.com/coser/archive/2011/12/17/2291160.html
格式字符串
格式字符串是用来在打包和解包数据时指定预期布局的机制。 它们使用指定被打包/解包数据类型的 格式字符 进行构建。 此外,还有一些特殊字符用来控制 字节顺序,大小和对齐方式。
字节顺序,大小和对齐方式
默认情况下,C类型以机器的本机格式和字节顺序表示,并在必要时通过跳过填充字节进行正确对齐(根据C编译器使用的规则)。
或者,根据下表,格式字符串的第一个字符可用于指示打包数据的字节顺序,大小和对齐方式:
| 字符 | 字节顺序 | 大小 | 对齐方式 |
|---|---|---|---|
@ |
按原字节 | 按原字节 | 按原字节 |
= |
按原字节 | 标准 | 无 |
< |
小端 | 标准 | 无 |
> |
大端 | 标准 | 无 |
! |
网络(=大端) | 标准 | 无 |
如果第一个字符不是其中之一,则假定为 '@' 。
格式字符
格式字符具有以下含义;C 和 Python 值之间的按其指定类型的转换应当是相当明显的。 标准大小列是指当使用标准大小时以字节表示的已打包值大小;也就是当格式字符串以 '<', '>', '!' 或 '=' 之一开头的情况。 当使用本机大小时,已打包值的大小取决于具体的平台。
| 格式 | C 类型 | Python 类型 | 标准大小 | 备注 |
|---|---|---|---|---|
x |
填充字节 | 无 | ||
c |
char | 长度为 1 的字节串 | 1 | |
b |
signed char | 整数 | 1 | (1), (2) |
B |
unsigned char | 整数 | 1 | (2) |
? |
_Bool | bool | 1 | (1) |
h |
short | 整数 | 2 | (2) |
H |
unsigned short | 整数 | 2 | (2) |
i |
int | 整数 | 4 | (2) |
I |
unsigned int | 整数 | 4 | (2) |
l |
long | 整数 | 4 | (2) |
L |
unsigned long | 整数 | 4 | (2) |
q |
long long | 整数 | 8 | (2) |
Q |
unsigned long long | 整数 | 8 | (2) |
n |
ssize_t |
整数 | (3) | |
N |
size_t |
整数 | (3) | |
e |
(6) | float | 2 | (4) |
f |
float | float | 4 | (4) |
d |
double | float | 8 | (4) |
s |
char[] | 字节串 | ||
p |
char[] | 字节串 | ||
P |
void* | 整数 | (5) |
格式字符之前可以带有整数重复计数。 例如,格式字符串 '4h' 的含义与 'hhhh' 完全相同。
格式之间的空白字符会被忽略;但是计数及其格式字符中不可有空白字符。
10s 表示10个字节的字节串
10c 表示10个字符
0s 表示空字符串
0c 表示0个字符
Example:(三个整数)
打包/解包三个整数的基础示例:
import struct
pack_data = pack('hhl',1,2,3) #打包两个short类型一个long类型的数值,即0x00 0x01|0x00 0x02|0x00 0x00 0x00 0x03
print(pack_data)
在C语言中一个short占用2个字节即word,一个long占用4个字节即dword,
可以看到我当前系统上他以小端格式输出了如下的数据。
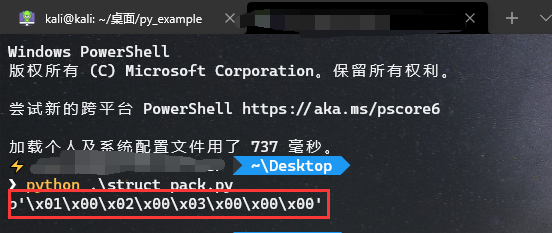
如果需要转成大端格式比较可视化,只要在改成这种格式>hhl即可。

接下来是解包,我们从文件或网络得到C格式的字节流后需要转成对应的python数据。
import struct
unpack_data = struct.unpack('hhl',b'\x00\x01\x00\x02\x00\x00\x00\x03')
print(unpack_data)
执行后发现数据对不上,如下图:
这是因为他默认以小端的方式去解包了,所以刚好对应的十进制数据就是256.
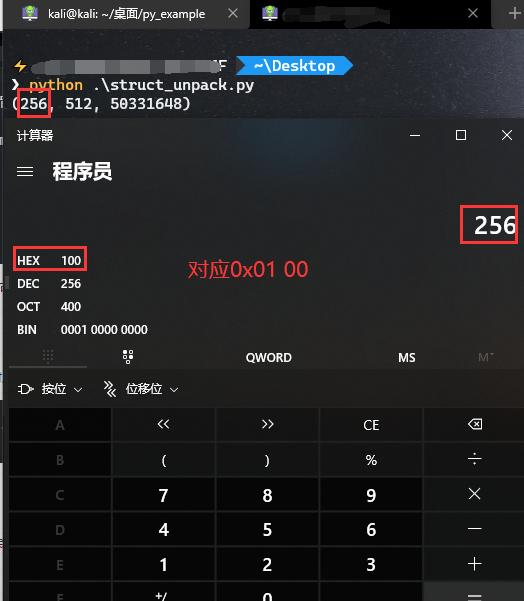
所以在解包的时候我们必须要明确解包的顺序,是大端还是小端,这里我们需要解成大端的格式即>hhl

Example:(元组)
record = b'raymond \x32\x12\x08\x01\x08'
name, serialnum, school, gradelevel = unpack('<10sHHb', record)
#小端模式
#10s 长度10的字节串
#unsigned short
#unsigned short
#一个字节
Example:(填充)
以下格式 'llh0l' 指定在末尾有两个填充字节,假定 long 类型按 4 个字节的边界对齐:
>>> pack('llh0l', 1, 2, 3)
b'\x00\x00\x00\x01\x00\x00\x00\x02\x00\x03\x00\x00'
参考文献:
《Python编程从入门到实践》
http://c.biancheng.net/view/2175.html [Python bytes类型及用法]
https://www.cnblogs.com/blili/p/11798504.html#综述python中字符串分为字节字符和非字节字符 [python字符串的encode与decode]
https://docs.python.org/zh-cn/3/library/struct.html#format-strings [struct --- 将字节串解读为打包的二进制数据]
Python学习笔记总结的更多相关文章
- python学习笔记整理——字典
python学习笔记整理 数据结构--字典 无序的 {键:值} 对集合 用于查询的方法 len(d) Return the number of items in the dictionary d. 返 ...
- VS2013中Python学习笔记[Django Web的第一个网页]
前言 前面我简单介绍了Python的Hello World.看到有人问我搞搞Python的Web,一时兴起,就来试试看. 第一篇 VS2013中Python学习笔记[环境搭建] 简单介绍Python环 ...
- python学习笔记之module && package
个人总结: import module,module就是文件名,导入那个python文件 import package,package就是一个文件夹,导入的文件夹下有一个__init__.py的文件, ...
- python学习笔记(六)文件夹遍历,异常处理
python学习笔记(六) 文件夹遍历 1.递归遍历 import os allfile = [] def dirList(path): filelist = os.listdir(path) for ...
- python学习笔记--Django入门四 管理站点--二
接上一节 python学习笔记--Django入门四 管理站点 设置字段可选 编辑Book模块在email字段上加上blank=True,指定email字段为可选,代码如下: class Autho ...
- python学习笔记--Django入门0 安装dangjo
经过这几天的折腾,经历了Django的各种报错,翻译的内容虽然不错,但是与实际的版本有差别,会出现各种奇葩的错误.现在终于找到了解决方法:查看英文原版内容:http://djangobook.com/ ...
- python学习笔记(一)元组,序列,字典
python学习笔记(一)元组,序列,字典
- Pythoner | 你像从前一样的Python学习笔记
Pythoner | 你像从前一样的Python学习笔记 Pythoner
- OpenCV之Python学习笔记
OpenCV之Python学习笔记 直都在用Python+OpenCV做一些算法的原型.本来想留下发布一些文章的,可是整理一下就有点无奈了,都是写零散不成系统的小片段.现在看 到一本国外的新书< ...
- python学习笔记(五岁以下儿童)深深浅浅的副本复印件,文件和文件夹
python学习笔记(五岁以下儿童) 深拷贝-浅拷贝 浅拷贝就是对引用的拷贝(仅仅拷贝父对象) 深拷贝就是对对象的资源拷贝 普通的复制,仅仅是添加了一个指向同一个地址空间的"标签" ...
随机推荐
- Percolator模型及其在TiKV中的实现
一.背景 Percolator是Google在2010年发表的论文<Large-scale Incremental Processing Using Distributed Transactio ...
- qGPU on TKE - 腾讯云发布下一代 GPU 容器共享技术
背景 qGPU 是腾讯云推出的 GPU 共享技术,支持在多个容器间共享 GPU卡,并提供容器间显存.算力强隔离的能力,从而在更小粒度的使用 GPU 卡的基础上,保证业务安全,达到提高 GPU 使用率. ...
- PHP设计模式之命令模式
命令模式,也称为动作或者事务模式,很多教材会用饭馆来举例.作为顾客的我们是命令的下达者,服务员是这个命令的接收者,菜单是这个实际的命令,而厨师是这个命令的执行者.那么,这个模式解决了什么呢?当你要修改 ...
- python学习笔记(二)-字符串方法
python的字符串内建函数: #====================常用方法=============================name = 'besttest' new_name = n ...
- iNeuOS工业互联网操作系统部署在华为欧拉(openEuler)国产系统,vmware、openEuler、postgresql、netcore、nginx、ineuos一站式部署
目 录 1. 概述... 3 2. 创建虚拟机&安装华为欧拉(openEuler)系统... 4 2.1 创建新的虚拟机... 4 2.2 ...
- P2490-[SDOI2011]黑白棋【博弈论,dp】
正题 题目链接:https://www.luogu.com.cn/problem/P2490 题目大意 一个长度为\(n\)的棋盘上放下\(k\)个棋子. 第一个要是白色,下一个要是黑色,在下一个是白 ...
- Spring,IOC源码分析
有错勿喷 1.首先是Spring,IOC的基本概念 IOC是一个容器 容器启动的时候创建所有单实例对象 我们可以直接从容器中获取到这个对象 2.调试流程 ioc容器的启动过程?启动期间都做了什么(什么 ...
- Jetbrains CLion 安装与激活 详解
1. 下载与安装 1.1 下载 这里提供了三个操作系统的官网下载地址 Mac Windows Linux 进入页面后向下拉点击蓝色按钮即可下载. 1.2 安装 这里将用 MacOS 来进行示例,Win ...
- 在昨天夜黑风高的晚上,我偷了隔壁老王的Python入门课件,由浅入深堪称完美!
隔壁老王是一个资深码农,就业教育事业的秃顶之才昨天我下楼打酱油,看他迎面走来,满目春光我好奇的问道:老王,有什么好事,隔壁小花叫你上门了吗?老王:秘密!!我心想:哎呦~不错啊半晚之时,连猫狗都睡着了, ...
- MSSQL还原数据库,更改用户登陆权限
有的时候还原完数据库后,使用账号登陆不进去,报告没有这个用户的时候,可以使用以下sql解决: sp_change_users_login 'update_one','username','userna ...