【Python机器学习实战】决策树与集成学习(五)——集成学习(3)GBDT应用实例
前面对GBDT的算法原理进行了描述,通过前文了解到GBDT是以回归树为基分类器的集成学习模型,既可以做分类,也可以做回归,由于GBDT设计很多CART决策树相关内容,就暂不对其算法流程进行实现,本节就根据具体数据,直接利用Python自带的Sklearn工具包对GBDT进行实现。
数据集采用之前决策树中的红酒数据集,之前的数据集我们做了类别的处理(将连续的数据删除了,且小批量数据进行了合并),这里做同样的处理,将其看为一个多分类问题。
首先依旧是读取数据,并对数据进行检查和预处理,这里就不再赘述,所得数据情况如下:
wine_df = pd.read_csv('./winequality-red.csv', delimiter=';', encoding='utf-8')
columns_name = list(wine_df.columns)
for name in columns_name:
q1, q2, q3 = wine_df[name].quantile([0.25, 0.5, 0.75])
IQR = q3 - q1
lower_cap = q1 - 1.5 * IQR
upper_cap = q3 + 1.5 * IQR
wine_df[name] = wine_df[name].apply(lambda x: upper_cap if x > upper_cap else (lower_cap if (x < lower_cap) else x))
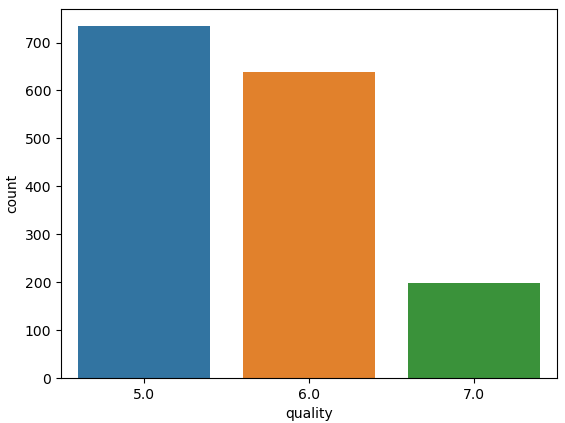
sns.countplot(wine_df['quality'])
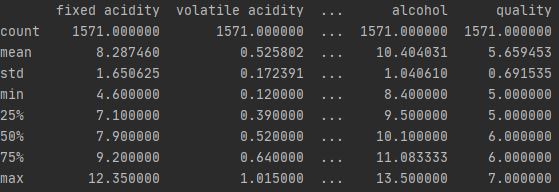
wine_df.describe()
接下来就是先导入使用GBDT所需要用到的工具包:
# 这里采用的是回归,因此是GradientBoostingRegressor,如果是分类则使用GradientBoostingClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import mean_squared_error
from sklearn import metrics
from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt
然后依旧是对数据进行切分,将数据分为训练集和测试集:
trainX, testX, trainY, testY = train_test_split(wine_df.drop(['quality']), wine_df['quality'], test_size=0.3, random_state=22)
然后就是建立模型:
model = GradientBoostingClssifier()
这里模型就有很多可选参数,用于调整模型,下面进行具体介绍:
首先是Boosting的框架的参数,这里在使用GradientBoostingRegressor和GradientBoostingClassifier是一样的,具体包括:
- n_estimators:弱分类器的最大迭代次数,也就是多少个弱分类器组成,默认值为100。当该值越小时容易欠拟合,太大又会过拟合;
- learning_rate:学习率,这在前面原理部分有进行介绍,默认值为1,较小的learning_rate意味着步长较小,需要更多的分类器才能够达到效果,通常需要与上面n_eatimators结合共同调参;
- subsample:这也是一种正则化的方法,在正则化中有提到过,取值为(0,1],默认值为1,即不进行子采样;
- init:初始化的弱分类器,即f0(x),默认为采用训练样本初始化的分类回归预测,若赋予值需要根据一定的先验知识或者预拟合;
- loss:即损失函数,在原理篇介绍过相关损失函数,对于分类和回归中损失函数是不相同的:
- 在分类模型中,有对数似然损失函数“deviance”和指数损失函数“exponential”,默认为对数似然损失函数,一般选择默认,因为选择指数损失函数“exponential”又退回到AdaBoost了;
- 在回归模型中,有方差损失“ls”、绝对损失“lad”、Huber损失“huber”和分位数损失“quantile”,默认为均方差损失“ls”,一般来说,数据的噪音不多,采用均方差损失即可,噪音点较多,则推荐使用抗噪能力较强的Huber损失,如果需要对训练集进行分段预测时则采用分位数损失“quantile”;
- alpha:这个参数只存在于GradientBoostingRegressor中,当使用Huber损失和分位数损失时,需要指定分位数的值,默认为0.9,如果噪音数据较多,可以适当降低这个值。
然后就是弱分类器有关的参数值,弱分类器采用的CART回归树,决策树中的相关参数在决策树实现部分已经进行介绍,这里主要对其中一些重要的参数再进行解释:
- max_features:划分树时所用到的最大特征数,默认为None,即使用全部的特征,当取值为“log2”时,划分时使用log2N个特征,如果是“sqrt”和“auto”则分别对应着最多考虑√N¯个特征,如果是整数,则代表考虑特征的绝对数,如果是浮点数,则代表考虑总特征数的百分比。一般来说样本总特征数小于50,直接采用50即可,当样本特征数量较大时,再考虑其他特征数;
- max_depth:每个弱分类器的最大深度,默认为不输入,树的深度为3,一般对于数据较少或者特征较少,该值不需要输入,当样本数量和特征数量过于庞大,推荐使用最大深度限制,一般选择10~100;
- min_samples_split:内部节点再划分所需最小的样本数,它限制了子树进一步划分的条件,如果节点的样本数小于min_samples_split则不再进行分裂。默认值为2,若样本数量较大,则推荐增大该值;
- min_samples_leaf:叶子节点最小样本数,该值限定了叶子节点的最小样本数,默认值为1,如果叶子节点样本数量小于该值,则会和兄弟节点一起被剪枝,如果样本量巨大,则推荐增加该值;
- min_weight_fraction_leaf:叶子节点最小样本权重和,该值限制了叶子节点所有样本权重和的最小值,若小于该值,则会和兄弟节点被剪枝,默认值为0,即不考虑权重。当样本分类问题中类别分布偏差较大,则会引入样本权重,需要调整该值;
- max_leaf_nodes:最大叶子节点数,通过限制最大叶子结点数防止过拟合,默认为None。如果加入了限制,则算法会建立在最大叶子节点数内最优的决策树,当样本特征数量过多的话,可以限制该值;
- min_impurity_split:节点划分最小不纯度,这个值限定了决策树的生长,若节点的不纯度(即基尼系数)小于这个值,则该节点不再生长,即为叶子结点,默认值为1e-7,一般不推荐修改。
上述即为模型的主要参数,这里首先全部使用默认值,对样本进行训练:
model.fit(trainX, trainY)
print("模型在训练集上分数为%s"%model.score(trainX, trainY))
pred_prob = model.predict_proba(trainX)
print('AUC:', metrics.roc_auc_score(np.array(trainY), pred_prob, multi_class='ovo'))
模型在训练集上分数为0.8817106460418562
AUC: 0.9757763363472337
可以看到在训练集上AUC表现还不错,模型的分数但并不高,尝试调整训练参数,首先对于迭代次数和学习率共同进行调整:
param_test1 = {'n_estimators': range(10, 501, 10), 'learning_rate': np.linspace(0.1, 1, 10)}
gsearch = GridSearchCV(estimator=GradientBoostingClassifier(learning_rate=1,
min_samples_split=2,
min_samples_leaf=1,
max_depth=3,
max_features=None,
subsample=0.8,
), param_grid=param_test1, cv=5)
gsearch.fit(trainX, trainY)
means = gsearch.cv_results_['mean_test_score']
params = gsearch.cv_results_['params']
for i in range(len(means)):
print(params[i], means[i])
print(gsearch.best_params_)
print(gsearch.best_score_)
# {'learning_rate': 0.2, 'n_estimators': 100}
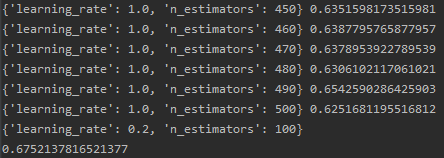
找出最好的n_estimators=100和learning_rate=0.2,将其定下来,带回模型,再次验证:
model = GradientBoostingClassifier(n_estimators=100, learning_rate=0.2,subsample=0.8)
model.fit(trainX, trainY)
print("模型在训练集上分数为%s"%model.score(trainX, trainY))
pred_prob = model.predict_proba(trainX)
print('AUC:', metrics.roc_auc_score(np.array(trainY), pred_prob, multi_class='ovo'))
模型在训练集上分数为0.9663330300272975
AUC: 0.9977791940084874
可以看到拟合效果已经很好了,再次调整参数,接下来调整弱分类器中的参数,max_depth和min_samples_split:
param_test1 = {'max_depth': range(1, 6, 1), 'min_samples_split': range(1, 101, 10)}
gsearch2 = GridSearchCV(estimator=GradientBoostingClassifier(n_estimators=100,
learning_rate=0.2,
max_features=None,
min_samples_leaf=1,
subsample=0.8,
), param_grid=param_test1, cv=5)
gsearch2.fit(trainX, trainY)
means = gsearch2.cv_results_['mean_test_score']
params = gsearch2.cv_results_['params']
for i in range(len(means)):
print(params[i], means[i])
print(gsearch2.best_params_)
print(gsearch2.best_score_)
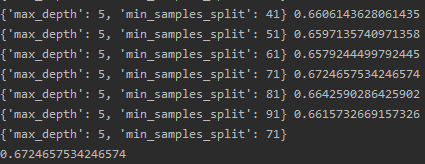
找出了树的最大深度为5,由于最小样本划分数量同叶子节点最小样本数量有一定关系,暂时不能定下min_samples_split,将其同min_samples_leaf共同调整:
param_test1 = {'min_samples_leaf': range(1, 101, 10), 'min_samples_split': range(1, 101, 10)}
gsearch3 = GridSearchCV(estimator=GradientBoostingClassifier(n_estimators=100,
learning_rate=0.2,
max_features=None,
max_depth=5,
subsample=0.8,
), param_grid=param_test1, cv=5)
gsearch3.fit(trainX, trainY)
means = gsearch3.cv_results_['mean_test_score']
params = gsearch3.cv_results_['params']
for i in range(len(means)):
print(params[i], means[i])
print(gsearch3.best_params_)
print(gsearch3.best_score_)
# {'min_samples_leaf': 21, 'min_samples_split': 41}
可以找出最小样本划分数量21和叶子节点最小数量,我们将这些参数再带回模型:
model = GradientBoostingClassifier(n_estimators=100, learning_rate=0.2, max_depth=5, min_samples_leaf=21, min_samples_split=41, subsample=0.8)
model.fit(trainX, trainY)
print("模型在训练集上分数为%s"%model.score(trainX, trainY))
pred_prob = model.predict_proba(trainX)
print('AUC:', metrics.roc_auc_score(np.array(trainY), pred_prob, multi_class='ovo'))
模型在训练集上分数为1.0
AUC: 1.0
可以看到在训练集上已经完美拟合了,但为了验证模型,我们需要再分离出一部分用于验证模型的数据集:
validX, tX, validY, tY = train_test_split(testX, testY, test_size=0.2)
然后使用验证集,验证模型:
print("模型在测试集上分数为%s"%metrics.accuracy_score(validY, model.predict(validX)))
pred_prob = model.predict_proba(validX)
print('AUC test:', metrics.roc_auc_score(np.array(validY), pred_prob, multi_class='ovo'))
模型在测试集上分数为0.726790450928382
AUC test: 0.8413890948027345
可以看到模型在验证集上表现并不是很好,上面模型存在一定的过拟合问题,继续调整参数,通过调整max_features来提高模型的泛华能力:
param_test1 = {'max_features': range(3, 12, 1)}
gsearch4 = GridSearchCV(estimator=GradientBoostingClassifier(n_estimators=100,
learning_rate=0.2,
min_samples_leaf=21,
min_samples_split=41,
max_depth=5,
subsample=0.8,
), param_grid=param_test1, cv=5)
gsearch4.fit(trainX, trainY)
means = gsearch4.cv_results_['mean_test_score']
params = gsearch4.cv_results_['params']
for i in range(len(means)):
print(params[i], means[i])
print(gsearch4.best_params_)
print(gsearch4.best_score_)
# {'max_features': 5}
进一步调整subsamples:
param_test1 = {'subsample': np.linspace(0.1, 1, 10)}
gsearch5 = GridSearchCV(estimator=GradientBoostingClassifier(n_estimators=100,
learning_rate=0.2,
min_samples_leaf=21,
min_samples_split=41,
max_depth=5,
max_features=5
), param_grid=param_test1, cv=5)
gsearch5.fit(trainX, trainY)
means = gsearch5.cv_results_['mean_test_score']
params = gsearch5.cv_results_['params']
for i in range(len(means)):
print(params[i], means[i])
print(gsearch5.best_params_)
print(gsearch5.best_score_)
# {'subsample': 0.7}
到这里基本主要参数都进行了调整,带回到模型中:
model = GradientBoostingClassifier(n_estimators=100, learning_rate=0.2, max_depth=5, min_samples_leaf=21, min_samples_split=41, max_features=5, subsample=0.7)
model.fit(trainX, trainY)
print("模型在训练集上分数为%s"%model.score(trainX, trainY))
pred_prob = model.predict_proba(trainX)
print('AUC:', metrics.roc_auc_score(np.array(trainY), pred_prob, multi_class='ovo'))
模型在训练集上分数为0.9990900818926297
AUC: 0.9999992641648271
有略微下降,因为通过提高模型的泛华能力,会增大模型的偏差,然后利用验证集验证模型:
print("模型在测试集上分数为%s"%metrics.accuracy_score(validY, model.predict(validX)))
pred_prob = model.predict_proba(validX)
print('AUC test:', metrics.roc_auc_score(np.array(validY), pred_prob, multi_class='ovo'))
模型在测试集上分数为0.7161803713527851
AUC test: 0.8429467644071055
进一步将模型的迭代次数增加一倍,学习率减半:
model = GradientBoostingClassifier(n_estimators=200, learning_rate=0.1, max_depth=5, min_samples_leaf=21, min_samples_split=41, max_features=5, subsample=0.7)
model.fit(trainX, trainY)
print("模型在训练集上分数为%s"%model.score(trainX, trainY))
pred_prob = model.predict_proba(trainX)
print('AUC:', metrics.roc_auc_score(np.array(trainY), pred_prob, multi_class='ovo'))
# validX, tX, validY, tY = train_test_split(testX, testY, test_size=0.2)
print("模型在测试集上分数为%s"%metrics.accuracy_score(validY, model.predict(validX)))
pred_prob = model.predict_proba(validX)
print('AUC test:', metrics.roc_auc_score(np.array(validY), pred_prob, multi_class='ovo'))
模型在训练集上分数为0.9990900818926297
AUC: 1.0
模型在测试集上分数为0.7427055702917772
AUC test: 0.851199242237048
可以看到模型泛化能力有略微增强,可以尝试进一步上述步骤,当迭代次数增加到一定程度,学习率减小到一定程度,模型泛化能力下降,可能是由于步长过小导致拟合和泛化能力下降。
以上就是GBDT的一个实例和参数调整过程,这里使用的是CvGrid网格遍历搜索调参的方法,从结果来看并不理想,可能是由于样本分布的问题,还有就是在进行数据处理的时候采用了replace直接更改了样本的标签,在测试集中这部分数据可能会预测错误。 后面会继续查找原因,调整数据集再次进行训练。
本例仅作为一个调参的学习过程,主要对GBDT中的参数有一个初步的了解,也是刚开始学习调参的方法,参数设置的也比较粗糙,后续会找一些新的数据集进一步对调参进行学习。
【Python机器学习实战】决策树与集成学习(五)——集成学习(3)GBDT应用实例的更多相关文章
- 【Python机器学习实战】决策树和集成学习(一)
摘要:本部分对决策树几种算法的原理及算法过程进行简要介绍,然后编写程序实现决策树算法,再根据Python自带机器学习包实现决策树算法,最后从决策树引申至集成学习相关内容. 1.决策树 决策树作为一种常 ...
- 机器学习实战(Machine Learning in Action)学习笔记————03.决策树原理、源码解析及测试
机器学习实战(Machine Learning in Action)学习笔记————03.决策树原理.源码解析及测试 关键字:决策树.python.源码解析.测试作者:米仓山下时间:2018-10-2 ...
- Python 机器学习实战 —— 监督学习(下)
前言 近年来AI人工智能成为社会发展趋势,在IT行业引起一波热潮,有关机器学习.深度学习.神经网络等文章多不胜数.从智能家居.自动驾驶.无人机.智能机器人到人造卫星.安防军备,无论是国家级军事设备还是 ...
- Python 机器学习实战 —— 无监督学习(上)
前言 在上篇<Python 机器学习实战 -- 监督学习>介绍了 支持向量机.k近邻.朴素贝叶斯分类 .决策树.决策树集成等多种模型,这篇文章将为大家介绍一下无监督学习的使用.无监督学习顾 ...
- Python 机器学习实战 —— 监督学习(上)
前言 近年来AI人工智能成为社会发展趋势,在IT行业引起一波热潮,有关机器学习.深度学习.神经网络等文章多不胜数.从智能家居.自动驾驶.无人机.智能机器人到人造卫星.安防军备,无论是国家级军事设备还是 ...
- Python 机器学习实战 —— 无监督学习(下)
前言 在上篇< Python 机器学习实战 -- 无监督学习(上)>介绍了数据集变换中最常见的 PCA 主成分分析.NMF 非负矩阵分解等无监督模型,举例说明使用使用非监督模型对多维度特征 ...
- python机器学习实战(一)
python机器学习实战(一) 版权声明:本文为博主原创文章,转载请指明转载地址 www.cnblogs.com/fydeblog/p/7140974.html 前言 这篇notebook是关于机器 ...
- python机器学习实战(二)
python机器学习实战(二) 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7159775.html 前言 这篇noteboo ...
- python机器学习实战(四)
python机器学习实战(三) 版权声明:本文为博主原创文章,转载请指明转载地址 www.cnblogs.com/fydeblog/p/7364317.html 前言 这篇notebook是关于机器学 ...
- 机器学习实战(Machine Learning in Action)学习笔记————09.利用PCA简化数据
机器学习实战(Machine Learning in Action)学习笔记————09.利用PCA简化数据 关键字:PCA.主成分分析.降维作者:米仓山下时间:2018-11-15机器学习实战(Ma ...
随机推荐
- xxe 回显与无回显
转载学习于红日安全 一.有回显 (1)直接将外部实体引用的URI设置为敏感目录 <!DOCTYPE foo [<!ELEMENT foo ANY > <!ENTITY xxe ...
- Git常用命令和基础使用
Git 参考:廖雪峰的Git教程 Git 常用命令 git config --global user.name "name" #配置git使用用户 git config --glo ...
- Hadoop 3.1.1 - Yarn - 使用 GPU
在 Yarn 上使用 GPU 前提 目前,Yarn 只支持 Nvidia GPU. YARN NodeManager 所在机器必须预先安装了 Nvidia 驱动器. 如果使用 Docker 作为容器的 ...
- 使用 C++ WinRT 组件
创建 C++ WinRT 组件 通过 Cpp/WinRT 项目模板创建一个 WinRT 组件工程 CppWinrtComponent.vcxproj,主要接口定义如下: namespace CppWi ...
- etcd raft 处理流程图系列2-transport
本章给出了raftexample中使用的传输层代码,补全了上一节中传输层与raft节点(raft server和channel server)的交互细节.下图中流程的核心在于传输层中的streamRt ...
- 02.反射Reflection
1. 基本了解 1.1 反射概述 文字说明 审查元数据并收集关于它的类型信息的能力称为反射,其中元数据(编译以后的最基本数据单元)就是一大堆的表,当编译程序集或者模块时,编译器会创建一个类定义表,一个 ...
- 小程序中多个echarts折线图在同一个页面的使用
最近做小程序的业务中遇到一个页面要同时显示几个echarts图,刚开始遇到各种冲突,死数据可以,动态数据就报错的问题,折磨了一天,仔细看了官网和查在各种资料之后,终于解决了. 直接上代码: commi ...
- burp暴力破解之md5和绕过验证码
Burpsuite是一个功能强大的工具,也是一个比较复杂的工具 本节主要说明一下burp的intruder模块中的2个技巧 1.md5加密 我们在payload Processing中的add选项可以 ...
- 自学vue第二天,从入门到放弃(生命周期的理解)
生命周期的理解 beforeCreate 创建前 数据还没有监听,没有绑定到vue对象实例,同时也没有挂载对象 没有数据也没有方法 created 在创建后 数据和方法已经 data数据已经绑定好了 ...
- 深入理解SPI机制
一.什么是SPI SPI ,全称为 Service Provider Interface,是一种服务发现机制.它通过在ClassPath路径下的META-INF/services文件夹查找文件,自动加 ...