【Mysql】一个简易的索引方案
一、没有索引的时候如何查找
先忽略掉索引这个概念,如果现在直接要查某条记录,要如何查找呢?
在一个页中查找
如果表中的记录很少,一个页就够放,那么这时候有 2 种情况:
- 用主键为搜索条件:这时就是之前文章提过的方式,页面目录中用二分法快速定位到槽,然后遍历该槽对应分组的记录,最终找到指定记录。
- 用其他非主键的列为搜索条件:因为数据页中没有为非主键列建立页目录,无法通过二分法快速定位槽,只能从 Infimum 记录开始一次遍历单链表的每条记录,效率低下。
在很多页中查找
当表中的记录非常多,就会用到很多的数据页来存储,这时候需要 2 个步骤:
- 定位到记录所在页。
- 重复上述在一个页中查找的过程。
总得来说,当没有索引,我们无法快速定位到记录所在页,只能从第一页沿着双向链表(页有前一页和后一页)一直找下去,然后在每一页中重复上述的过程查询指定的记录,需要遍历所有记录,这种方式非常耗时。
二、一个简易索引
既然是因为页数太多导致定位记录太慢,那如何解决呢?不妨参考一下“页目录”。
页目录就是为了根据主键快速定位一条记录在页中的位置而设置的。那么我们也可以想办法为快速定位记录所在的页,搞一个“别的目录”。
但是这个“别的目录”要想完成还得干好 2 件事。
1. 下一页用户记录的主键值必须大于上一页的
假设,每个数据页最多可以放 3 条记录(实际上可以放很多),那么现在向表里插入 3 条记录,每条记录有3个列 c1、c2、c3。为了看着方便,存储行格式也简化下,只留关键属性。注意中间3条是用户记录,首尾的2条是虚拟记录 Infimum 和 Supremum。

此时,继续插入 1 条记录。按照假设的情况,现在需要多分配一个新的页,所以 2 个页之间就变成了这样。
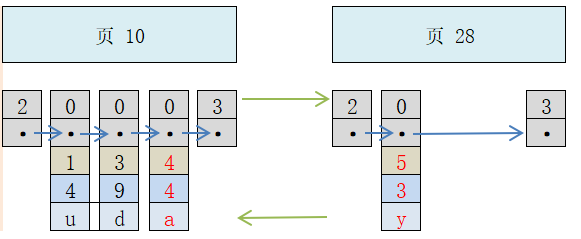
注意红色字体显示的2条记录,本来主键 4 的记录是新插入的,按理应该放在新的页。但是,为了满足下一页用户记录的主键值必须大于上一页的用户记录主键值,做了诸如记录移动的操作,这个过程也可以称为“页分裂”。
另外,为什么新页是页 28,而不是 11?因为页在磁盘上可能并不挨着,它们只是通过维护上一页和下一页的编号而建立了链表关系。
2. 给所有的页建立一个目录项
现在继续向表里增加数据,最终多个页的关系是这样:

因为这些页在磁盘上可能不挨着,所有想要快速从这么多页中根据主键快速定位某记录,就要给它们编制一个目录。
每个页对应一个目录项,每个目录项包括:
- 页的用户记录中最小的主键值,用 key 来表示
- 页号,用 page_no 表示
所以,给它们编好目录之后就是这样的关系:
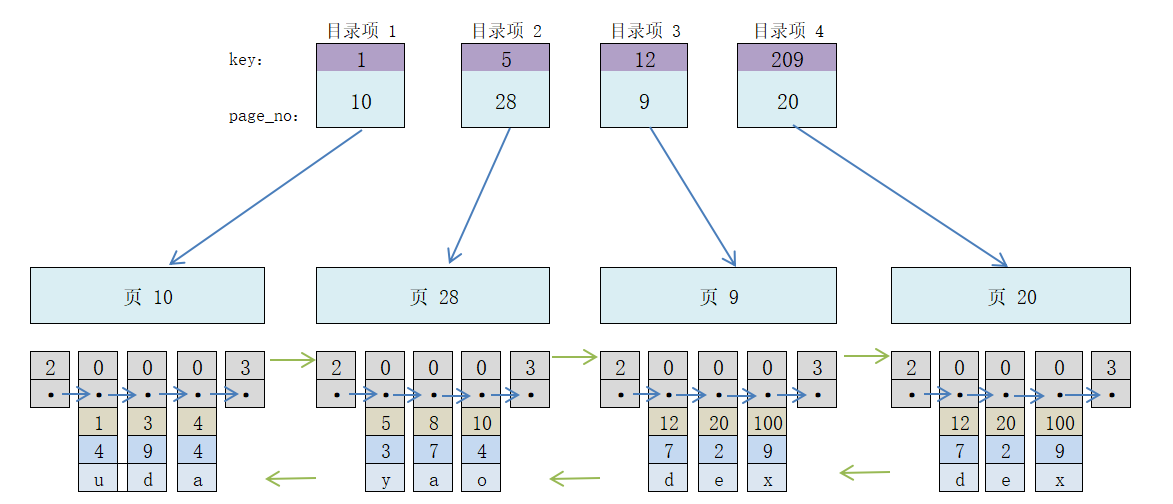
那么,现在我想查找主键值为 20 的记录,具体就分两步走:
- 先从目录项中根据二分法快速确定出主键值为 20 的记录所在目录项 3 中,且对应的页为 9。
- 知道是在页 9,重复之前的方式,找到最终目标记录。
到此,一个简易的方案完成。而完成的这个简易目录,它有个别名,叫做索引。
三、简易索引暴露出的问题
上述的简易索引是原书作者为了循序渐进的帮助读者理解而设置的内容,这并不是innodb的索引方案。
那么针对上述的建议索引,看下有哪些问题。
问题一:
InnoDB 使用页作为管理存储空间的基本单位,也就是最多只能保存16kb的连续存储。
当表中记录越来越多,此时就需要非常大的连续存储空间才可以把所有的目录项都装下,这对大数据量的表来说不现实。
问题二:
我们经常还要对记录执行增删改操作,会牵一发而动全身。
比如,上图中我如果把页 28 中的记录都删除,那么页 28 就没必要存在,进而目录项 2 也没必要存在。这时候就需要把目录项 2 后的目录项都向前移动一下。
就算不移动,把目录项 2 作为冗余放在目录项列表中,仍然会浪费很多的存储空间。
所以,InnoDB 的作者发现了一种灵活管理所有目录项的方式,详见下一篇。
本文参考书籍:
小孩子4919 《mysql是怎样运行的》
【Mysql】一个简易的索引方案的更多相关文章
- 实验楼 MySQL 基础课程 挑战:搭建一个简易的成绩管理系统的数据库
传送门:https://www.shiyanlou.com/courses/running 介绍 现需要构建一个简易的成绩管理系统的数据库,来记录几门课程的学生成绩.数据库中有三张表分别用于记录学生信 ...
- mysql大内存高性能优化方案
mysql优化是一个相对来说比较重要的事情了,特别像对mysql读写比较多的网站就显得非常重要了,下面我们来介绍mysql大内存高性能优化方案 8G内存下MySQL的优化 按照下面的设置试试看:key ...
- 防止服务器宕机时MySQL数据丢失的几种方案
这篇文章主要介绍了防止服务器宕机时MySQL数据丢失的几种方案,结合实践介绍了Replication和Monitor以及Failover这三个项目的应用,需要的朋友可以参考下. 对于多数应用来说,My ...
- Tinyshell: 一个简易的shell命令解释器
这是自己最近学习Linux系统编程之后写的一个练手的小程序,能很好地复习系统编程中的进程管理.信号.管道.文件等内容. 通过回顾写的过程中遇到的问题的形式记录程序的关键点,最后给出完整程序代码. 0. ...
- MySQL的B树索引与索引优化
MySQL的MyISAM.InnoDB引擎默认均使用B+树索引(查询时都显示为"BTREE"),本文讨论两个问题: 为什么MySQL等主流数据库选择B+树的索引结构? 如何基于索引 ...
- MySql(九)索引
一.索引的介绍 数据库中专门用于帮助用户快速查找数据的一种数据结构.类似于字典中的目录,查找字典内容时可以根据目录查找到数据的存放位置吗,然后直接获取. 二 .索引的作用 约束和加速查找 三.常见的几 ...
- express + mongodb 搭建一个简易网站 (四)
express + mongodb 搭建一个简易网站 (四) 目前网站整体页面都已经能全部展示了,但是,整个网站还有两个块需要做完才能算完整,一个连接数据库,目前网站上的数据都是抓取的本地假数据,所以 ...
- MySQL慢查询优化、索引优化、以及表等优化总结
MySQL优化概述 MySQL数据库常见的两个瓶颈是:CPU和I/O的瓶颈. CPU在饱和的时候一般发生在数据装入内存或从磁盘上读取数据时候. 磁盘I/O瓶颈发生在装入数据远大于内存容量的时候,如果应 ...
- mysql 百万级数据库优化方案
https://blog.csdn.net/Kaitiren/article/details/80307828 一.百万级数据库优化方案 1.对查询进行优化,要尽量避免全表扫描,首先应考虑在 wher ...
随机推荐
- Comparison of Laser SLAM and Visual SLAM
Comparison of Laser SLAM and Visual SLAM 目前,SLAM技术广泛应用于机器人.无人机.无人机.AR.VR等领域,依靠传感器可以实现机器的自主定位.测绘.路径规划 ...
- sync.waitgroup ----等待goroutine的执行完成
可以尝试改变wg.add里的值,改变wg.wait,或者wg.done的出现次数以及位置. 感受它的使用
- C++ folly库解读(三)Synchronized —— 比std::lock_guard/std::unique_lock更易用、功能更强大的同步机制
目录 传统同步方案的缺点 folly/Synchronized.h 简单使用 Synchronized的模板参数 withLock()/withRLock()/withWLock() -- 更易用的加 ...
- 关于Linux服务器部署
服务器信息: 此小节的内容: SecurityCRT:用来连接到Linux服务器命令操作. FTP(FTPRush):本地文件和Linux服务器文件交互的 工具服务器 借助客户端工具来链接到Linux ...
- C# 位图BitArray 小试牛刀
前面聊了布隆过滤器,回归认识一下位图BitMap,阅读前文的同学应该发现了布隆过滤器本身就是基于位图,是位图的一种改进. 位图 先看一个问题, 假如有1千万个整数,整数范围在1到1亿之间,如何快速确定 ...
- drf-Request与Response
一.Request 在Rest Framework 传入视图的request对象已经不再是Django默认的HTTPResponse对象了,而是Rest Framework提供的Request类的对象 ...
- 06 jumpserver登录操作
1.4.使用创建的 liuchang 用户登录jump server: 0.安全-MFA登陆验证说明: (1)简单的用户名密码就能登陆,太危险了,加一个MFA随机验证码这种黑科技限制一下. (2)Mu ...
- VSCode 使用 Code Runner 插件无法编译运行文件名带空格的文件
本文同时在我的博客发布:VSCode 使用 Code Runner 插件无法编译运行文件名带空格的文件 - Skykguj 's Blog (sky390.cn) 使用 Visual Studio C ...
- 暑假自学java第八天
1.接口的概念(关键字interface ) Java程序设计中的接口 ( interface)也是一种规范,用来组织应用程序中的类,并调节它们的相互关系.接口是由常量和抽象方法组成的特殊类,是对抽 ...
- 在CentOS7环境下部署weblogic集群
一)环境准备 服务器操作版本系统 CentOS7 weblogic版本包 weblogic1036_generic.jar(weblogic11g) JDK jdk-8u191-linux-x64.t ...