使用ganglia监控hadoop及hbase集群
一、Ganglia简介
Ganglia 是 UC Berkeley 发起的一个开源监视项目,设计用于测量数以千计的节点。每台计算机都运行一个收集和发送度量数据(如处理器速度、内存使用量等)的名为 gmond 的守护进程。它将从操作系统和指定主机中收集。接收所有度量数据的主机可以显示这些数据并且可以将这些数据的精简表单传递到层次结构中。正因为有这种层次结构模式,才使得 Ganglia 可以实现良好的扩展。gmond 带来的系统负载非常少,这使得它成为在集群中各台计算机上运行的一段代码,而不会影响用户性能
1.1 Ganglia组件
Ganglia 监控套件包括三个主要部分:gmond,gmetad,和网页接口,通常被称为ganglia-web。
Gmond :是一个守护进程,他运行在每一个需要监测的节点上,收集监测统计,发送和接受在同一个组播或单播通道上的统计信息 如果他是一个发送者(mute=no)他会收集基本指标,比如系统负载(load_one),CPU利用率。他同时也会发送用户通过添加C/Python模块来自定义的指标。 如果他是一个接收者(deaf=no)他会聚合所有从别的主机上发来的指标,并把它们都保存在内存缓冲区中。
Gmetad:也是一个守护进程,他定期检查gmonds,从那里拉取数据,并将他们的指标存储在RRD存储引擎中。他可以查询多个集群并聚合指标。他也被用于生成用户界面的web前端。
Ganglia-web :顾名思义,他应该安装在有gmetad运行的机器上,以便读取RRD文件。 集群是主机和度量数据的逻辑分组,比如数据库服务器,网页服务器,生产,测试,QA等,他们都是完全分开的,你需要为每个集群运行单独的gmond实例。
一般来说每个集群需要一个接收的gmond,每个网站需要一个gmetad。
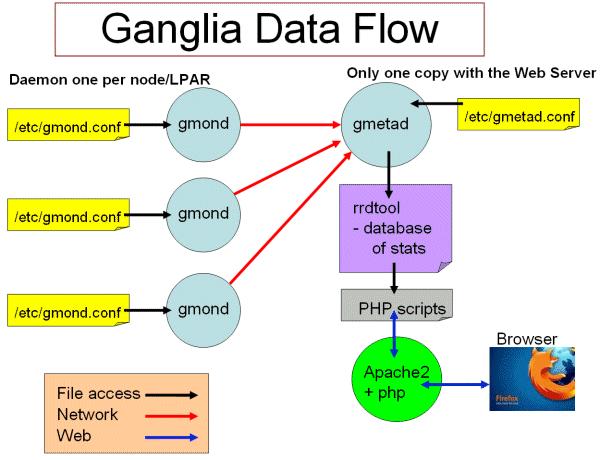
图1 ganglia工作流
Ganglia工作流如图1所示:
左边是运行在各个节点上的gmond进程,这个进程的配置只由节点上/etc/gmond.conf的文件决定。所以,在各个监视节点上都需要安装和配置该文件。
右上角是更加负责的中心机(通常是这个集群中的一台,也可以不是)。在这个台机器上运行这着gmetad进程,收集来自各个节点上的信息并存储在RRDtool上,该进程的配置只由/etc/gmetad.conf决定。
右下角显示了关于网页方面的一些信息。我们的浏览网站时调用php脚本,从RRDTool数据库中抓取信息,动态的生成各类图表。
1.2 Ganglia运行模式(单播与多播)
Ganglia的收集数据工作可以工作在单播(unicast)或多播(multicast)模式下,默认为多播模式。
单播:发送自己收集到的监控数据到特定的一台或几台机器上,可以跨网段。
多播:发送自己收集到的监控数据到同一网段内所有的机器上,同时收集同一网段内的所有机器发送过来的监控数据。因为是以广播包的形式发送,因此需要同一网段内。但同一网段内,又可以定义不同的发送通道。
二、安装ganglia
1、拓扑说明
3台主机,分别为:
- 10.171.29.191 master
- 10.171.94.155 slave1
- 10.251.0.197 slave3
其中master将gmeta及web,三台机都作gmon
以下步骤均使用root用户执行
2、master上安装gmeta及web
- yum install ganglia-web.x86_64
- yum install ganglia-gmetad.x86_64
3、在三台机上都安抚gmond
- yum install ganglia-gmond.x86_64
4、在三台机器上配置/etc/ganglia/gmond.conf,修改以下内容:
- udp_send_channel {
- #bind_hostname = yes # Highly recommended, soon to be default.
- # This option tells gmond to use a source address
- # that resolves to the machine's hostname. Without
- # this, the metrics may appear to come from any
- # interface and the DNS names associated with
- # those IPs will be used to create the RRDs.
- mcast_join = 10.171.29.191
- port = 8649
- ttl = 1
- }
- /* You can specify as many udp_recv_channels as you like as well. */
- udp_recv_channel {
- #mcast_join = 239.2.11.71
- port = 8649
- #bind = 239.2.11.71
- }
即将默认的多播地址改为master地址,将udp_recv_channel 的2个IP注释掉。
5、在master上修改/etc/ganglia/gmetad.conf
修改data_source,改成:
- data_source "my cluster” 10.171.29.191
6、ln -s /usr/share/ganglia /var/www/ganglia
若有问题,可以将/usr/share/ganglia的内容直接复制到/var/www/ganglia
7、修改/etc/httpd/conf.d/ganglia.conf,改成:
- #
- # Ganglia monitoring system php web frontend
- #
- Alias /ganglia /usr/share/ganglia
- <Location /ganglia>
- Order deny,allow
- Allow from all
- Allow from 127.0.0.1
- Allow from ::1
- # Allow from .example.com
- </Location>
即将 Deny from all 改为 Allow from all,否则在页面访问时有权限问题。
8、启动
- service gmetad start
- service gmond start
- /usr/sbin/apachectl start
9、从页面上访问
http://ip/ganglia
一些注意问题:
1、gmetad收集到的信息被放到/var/lib/ganglia/rrds/
2、可以通过以下命令检查是否有数据在传输
- tcpdump port 8649
三、配置hadoop与hbase
1、配置hadoop
hadoop-metrics2.properties
- # syntax: [prefix].[source|sink|jmx].[instance].[options]
- # See package.html for org.apache.hadoop.metrics2 for details
- *.sink.file.class=org.apache.hadoop.metrics2.sink.FileSink
- #namenode.sink.file.filename=namenode-metrics.out
- #datanode.sink.file.filename=datanode-metrics.out
- #jobtracker.sink.file.filename=jobtracker-metrics.out
- #tasktracker.sink.file.filename=tasktracker-metrics.out
- #maptask.sink.file.filename=maptask-metrics.out
- #reducetask.sink.file.filename=reducetask-metrics.out
- # Below are for sending metrics to Ganglia
- #
- # for Ganglia 3.0 support
- # *.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink30
- #
- # for Ganglia 3.1 support
- *.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
- *.sink.ganglia.period=10
- # default for supportsparse is false
- *.sink.ganglia.supportsparse=true
- *.sink.ganglia.slope=jvm.metrics.gcCount=zero,jvm.metrics.memHeapUsedM=both
- *.sink.ganglia.dmax=jvm.metrics.threadsBlocked=70,jvm.metrics.memHeapUsedM=40
- menode.sink.ganglia.servers=10.171.29.191:8649
- datanode.sink.ganglia.servers=10.171.29.191:8649
- jobtracker.sink.ganglia.servers=10.171.29.191:8649
- tasktracker.sink.ganglia.servers=10.171.29.191:8649
- maptask.sink.ganglia.servers=10.171.29.191:8649
- reducetask.sink.ganglia.servers=10.171.29.191:8649
2、配置hbase
hadoop-metrics.properties
- # See http://wiki.apache.org/hadoop/GangliaMetrics
- # Make sure you know whether you are using ganglia 3.0 or 3.1.
- # If 3.1, you will have to patch your hadoop instance with HADOOP-4675
- # And, yes, this file is named hadoop-metrics.properties rather than
- # hbase-metrics.properties because we're leveraging the hadoop metrics
- # package and hadoop-metrics.properties is an hardcoded-name, at least
- # for the moment.
- #
- # See also http://hadoop.apache.org/hbase/docs/current/metrics.html
- # GMETADHOST_IP is the hostname (or) IP address of the server on which the ganglia
- # meta daemon (gmetad) service is running
- # Configuration of the "hbase" context for NullContextWithUpdateThread
- # NullContextWithUpdateThread is a null context which has a thread calling
- # periodically when monitoring is started. This keeps the data sampled
- # correctly.
- hbase.class=org.apache.hadoop.metrics.spi.NullContextWithUpdateThread
- hbase.period=10
- # Configuration of the "hbase" context for file
- # hbase.class=org.apache.hadoop.hbase.metrics.file.TimeStampingFileContext
- # hbase.fileName=/tmp/metrics_hbase.log
- # HBase-specific configuration to reset long-running stats (e.g. compactions)
- # If this variable is left out, then the default is no expiration.
- hbase.extendedperiod = 3600
- # Configuration of the "hbase" context for ganglia
- # Pick one: Ganglia 3.0 (former) or Ganglia 3.1 (latter)
- # hbase.class=org.apache.hadoop.metrics.ganglia.GangliaContext
- hbase.class=org.apache.hadoop.metrics.ganglia.GangliaContext31
- hbase.period=10
- hbase.servers=10.171.29.191:8649
- # Configuration of the "jvm" context for null
- jvm.class=org.apache.hadoop.metrics.spi.NullContextWithUpdateThread
- jvm.period=10
- # Configuration of the "jvm" context for file
- # jvm.class=org.apache.hadoop.hbase.metrics.file.TimeStampingFileContext
- # jvm.fileName=/tmp/metrics_jvm.log
- # Configuration of the "jvm" context for ganglia
- # Pick one: Ganglia 3.0 (former) or Ganglia 3.1 (latter)
- # jvm.class=org.apache.hadoop.metrics.ganglia.GangliaContext
- jvm.class=org.apache.hadoop.metrics.ganglia.GangliaContext31
- jvm.period=10
- jvm.servers=10.171.29.191:8649
- # Configuration of the "rpc" context for null
- rpc.class=org.apache.hadoop.metrics.spi.NullContextWithUpdateThread
- rpc.period=10
- # Configuration of the "rpc" context for file
- # rpc.class=org.apache.hadoop.hbase.metrics.file.TimeStampingFileContext
- # rpc.fileName=/tmp/metrics_rpc.log
- # Configuration of the "rpc" context for ganglia
- # Pick one: Ganglia 3.0 (former) or Ganglia 3.1 (latter)
- # rpc.class=org.apache.hadoop.metrics.ganglia.GangliaContext
- rpc.class=org.apache.hadoop.metrics.ganglia.GangliaContext31
- rpc.period=10
- rpc.servers=10.171.29.191:8649
- # Configuration of the "rest" context for ganglia
- # Pick one: Ganglia 3.0 (former) or Ganglia 3.1 (latter)
- # rest.class=org.apache.hadoop.metrics.ganglia.GangliaContext
- rest.class=org.apache.hadoop.metrics.ganglia.GangliaContext31
- rest.period=10
- rest.servers=10.171.29.191:8649
重启hadoop与hbase。
使用ganglia监控hadoop及hbase集群的更多相关文章
- 第十二章 Ganglia监控Hadoop及Hbase集群性能(安装配置)
1 Ganglia简介 Ganglia 是 UC Berkeley 发起的一个开源监视项目,设计用于测量数以千计的节点.每台计算机都运行一个收集和发送度量数据(如处理器速度.内存使用量等)的名为 gm ...
- 使用ganglia监控hadoop及hbase集群 分类: B3_LINUX 2015-03-06 20:53 646人阅读 评论(0) 收藏
介绍性内容来自:http://www.uml.org.cn/sjjm/201305171.asp 一.Ganglia简介 Ganglia 是 UC Berkeley 发起的一个开源监视项目,设计用于测 ...
- 开启hadoop和Hbase集群的lzo压缩功能(转)
原文链接:开启hadoop和Hbase集群的lzo压缩功能 问题导读: 1.如何启动hadoop.hbase集群的压缩功能? 2.lzo的作用是什么? 3.hadoop配置文件需要做哪些修改? 首先我 ...
- 使用Ganglia监控hadoop、hbase
Ganglia是一个监控服务器,集群的开源软件,能够用曲线图表现最近一个小时,最近一天,最近一周,最近一月,最近一年的服务器或者集群的cpu负载,内存,网络,硬盘等指标. Ganglia的强大在于:g ...
- hadoop(八) - hbase集群环境搭建
1. 上传hbase安装包hbase-0.96.2-hadoop2-bin.tar.gz 2. 解压 tar -zxvf hbase-0.96.2-hadoop2-bin.tar.gz -C /clo ...
- docker应用-3(搭建hadoop以及hbase集群)
要用docker搭建集群,首先需要构造集群所需的docker镜像.构建镜像的一种方式是,利用一个已有的镜像比如简单的linux系统,运行一个容器,在容器中手动的安装集群所需要的软件并进行配置,然后co ...
- 设置Hadoop+Hbase集群pid文件存储位置
有时候,我们对运行几天或者几个月的hadoop或者hbase集群做停止操作,会发现,停止命令不管用了,为什么呢? 因为基于java开发的程序,想要停止程序,必须通过进程pid来确定,而hadoop和h ...
- 1.Hbase集群安装配置(一主三从)
1.HBase安装配置,使用独立zookeeper,shell测试 安装步骤:首先在Master(shizhan2)上安装:前提必须保证hadoop集群和zookeeper集群是可用的 1.上传:用 ...
- Ganglia监控Hadoop集群的安装部署[转]
Ganglia监控Hadoop集群的安装部署 一. 安装环境 Ubuntu server 12.04 安装gmetad的机器:192.168.52.105 安装gmond的机 器:192.168.52 ...
随机推荐
- 使用xUnit,EF,Effort和ABP进行单元测试(C#)
返回总目录<一步一步使用ABP框架搭建正式项目系列教程> 本篇目录 介绍 创建测试项目 准备测试基类 创建第一个测试 测试异常 在测试中使用仓储 测试异步方法 小结 介绍 在这篇博客中,我 ...
- Javascript 相关文章 —— 性能
在 IBM Bluemix 云平台上开发并部署您的下一个应用. 开始您的试用 概览 无论当前 JavaScript 代码是内嵌还是在外链文件中,页面的下载和渲染都必须停下来等待脚本执行完成.JavaS ...
- ceph架构剖析
unitedstack有云 :https://www.ustack.com/blog/ceph_infra/
- Owin:“System.Reflection.TargetInvocationException”类型的未经处理的异常在 mscorlib.dll 中发生
异常汇总:http://www.cnblogs.com/dunitian/p/4523006.html#signalR 这个异常我遇到两种情况,供园友参考: 第一种,权限不够,在项目运行的时候弹出== ...
- Log4net入门(SQL篇)
我们在Log4net入门(回滚日志篇)中详细讲述了如何将日志信息输出到日志文件中,在这一篇中,我们将讲述如何将日志文件写入SQL Server数据库,以方便我们分析统计日志信息. 首先,我们在SQL ...
- eclipse打开文件所在目录
设置 添加扩展工具,添加步骤如下: Run-->External Tools-->External Tools Configurations... new 一个 programlocati ...
- sql无限递归查询
--------------所有子集数据包括自己--------------------- CREATE PROCEDURE ALLSON @ID INT AS BEGIN WITH CTE AS ( ...
- SharePoint 2013 Create taxonomy field
创建taxonomy field之前我们首先来学习一下如果创建termSet,原因是我们所创建的taxonomy field需要关联到termSet. 简单介绍一下Taxonomy Term Stor ...
- Linux平台 Oracle 11gR2 RAC安装Part1:准备工作
一.实施前期准备工作 1.1 服务器安装操作系统 1.2 Oracle安装介质 1.3 共享存储规划 1.4 网络规范分配 二.安装前期准备工作 2.1 各节点系统时间校对 2.2 各节点关闭防火墙和 ...
- SQL Server Management Studio 无法修改表,超时时间已到 在操作完成之前超时时
在修改表时,保存的时候显示:无法修改表,超时时间已到 在操作完成之前超时时间已过或服务器未响应 这是执行时间设置过短的原因,可以修改一下设置便能把执行时间加长,以便有足够的时间执行完修改动作. 在 S ...