深度学习-深度强化学习(DRL)-Policy Gradient与PPO笔记
Policy Gradient
初始学习李宏毅讲的强化学习,听台湾的口音真是费了九牛二虎之力,后来看到有热心博客整理的很细致,于是转载来看,当作笔记留待复习用,原文链接在文末。看完笔记再去听一听李宏毅老师的视频,就可以听懂个大概了。当然了还有莫凡的强化学习更具实战性,听莫凡的课基本上可以带我们入门。
术语和基本思想
基本组成:
1.actor (即policy gradient要学习的对象, 是我们可以控制的部分)
2.环境 environment (给定的,无法控制)
3.回报函数 reward function (无法控制)
Policy of actor π:
如下图所示,Policy 可以理解为一个包含参数 θ的神经网络,该网络将观察到的变量作为模型的输入,基于概率输出对应的行动action
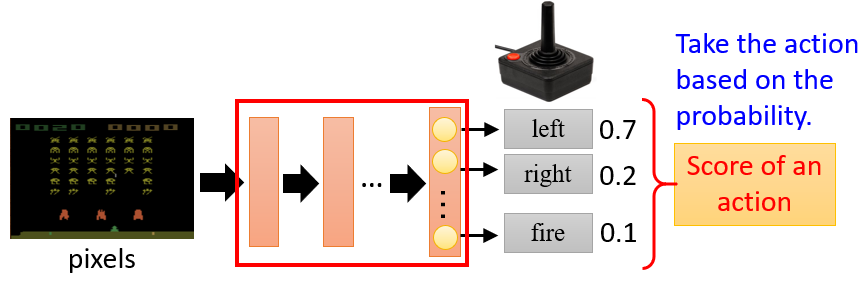
Episode:
游戏从开始到结束的一个完整的回合
actor的目标:
最大化总收益reward
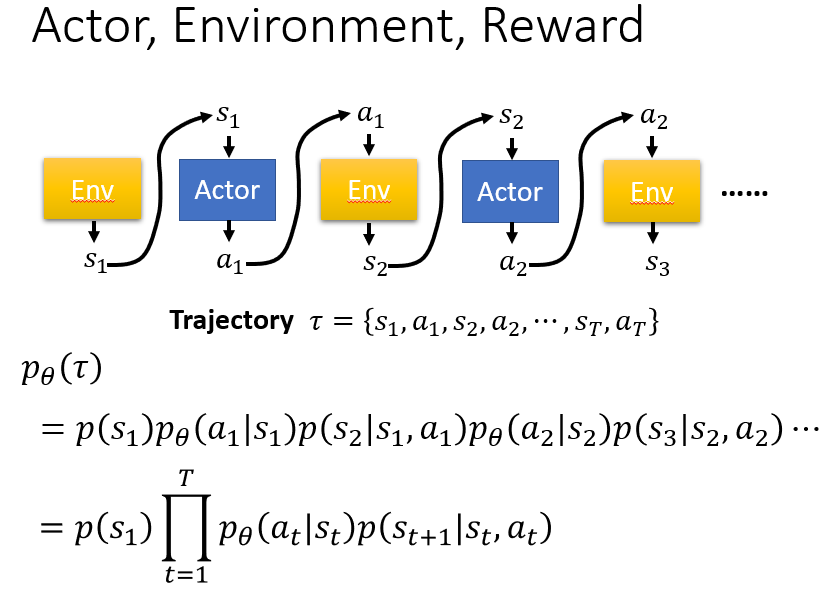
Trajectory τ :
行动action和状态state的序列
给定神经网络参数θ的情况下,出现行动状态序列τ的概率:
以下概率的乘积:初始状态出现的概率;给定当前状态,采取某一个行动的概率;以及采取该行动之后,基于该行动以及当前状态返回下一个状态的概率,用公式表示为:
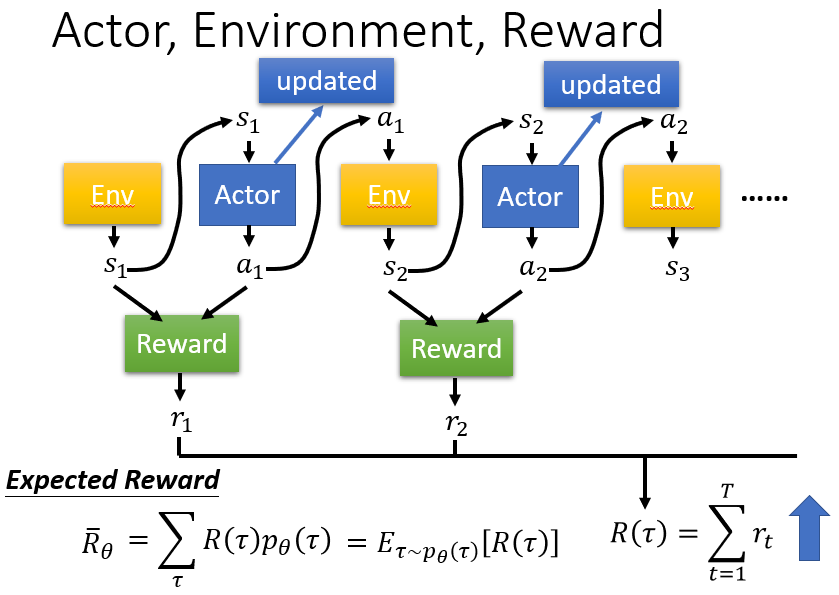
给定一个行动状态序列 τ , 我们可以得到它对应的收益reward,通过控制actor,我们可以得到不同的收益。由于actor采取的行动以及给定环境下出现某一个状态state是随机的,最终的目标是找到一个具有最大期望收益(即下述公式)的actor。
累积期望收益:采取某一个行动状态序列τ 的概率, 以及该行动状态序列对应的收益reward的乘积之和。
Policy Gradient
得出目标函数之后,就需要根据目标函数求解目标函数最大值以及最大值对应的policy的参数 θ。类比深度学习中的梯度下降求最小值的方法,由于我们这里需要求的是目标函数的最大值,因此需要采取的方法是梯度上升。也就是说,思想起点是一样的,即需要求出目标函数的梯度。
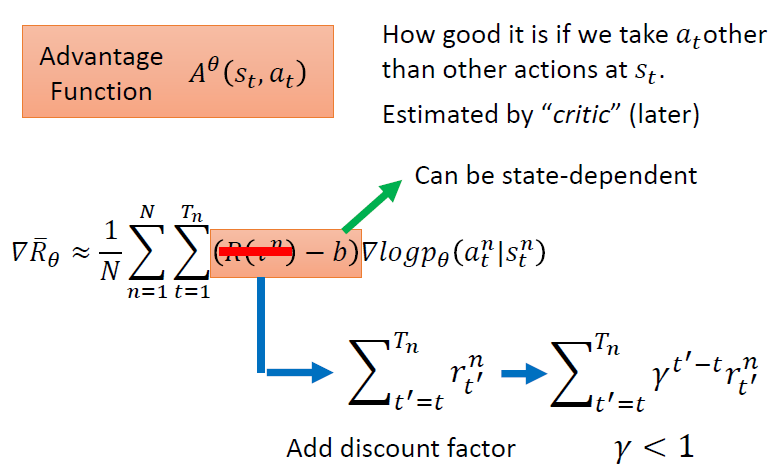
求解梯度的步骤如下,以前文所述目标函数为基础,对参数 θ 求导,其中,对概率加权的reward求和就是求reward的期望,因此有红框部分的改写,又因为训练的过程中会进行采样训练,采样个数为N,因此公式可以近似表示为N词采样得到的reward的平均。

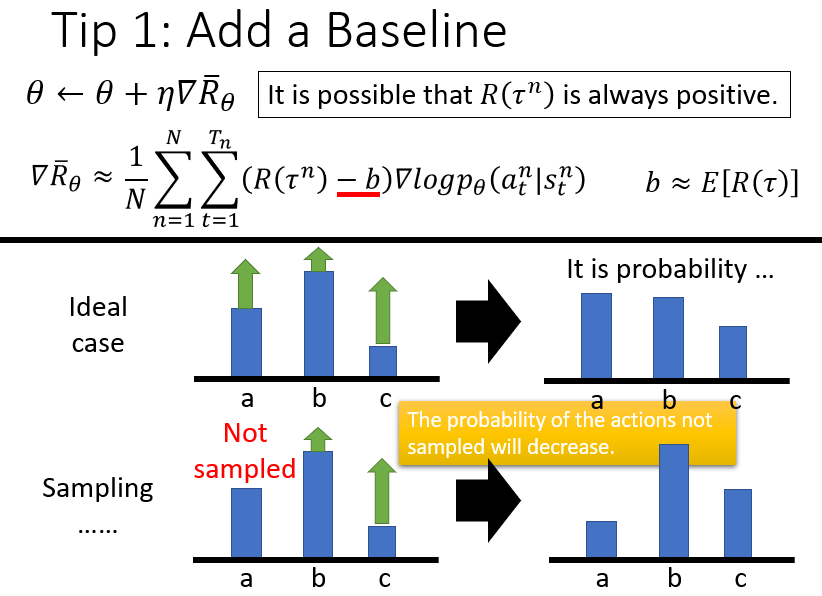
Tip 1: 添加基准线
由于训练过程中采样是随机的,可能会出现某个行动不被采样的情况,这会导致采取该行动的概率下降;另外,由于采取的行动概率和为一,可能存在归一化之后,好的action的概率相对下降,坏的action概率相对上升的情况,因此需要引入一个基准线baseline b.
具体的例子:当policy决定采取的三个action a,b,c均有正的reward时,比如3,4,5,在计算各个action的概率的时候,本来应该给action c分配较大的概率,但是归一化之后,a的概率反而可能上升,c的概率可能会下降,与对应reward应该被分配的概率分布不符。但是引入baseline之后,可能a的reward会变为负,这样的话,采取该行动的概率就会下降。
Tip 2: 进一步考虑各个时间点的累积收益计算方式
考虑到在时间t采取的行动action与t时期之前的收益reward无关,因此只需要将t时刻开始到结束的reward进行加总。并且,由于行动action对随后各时间点的reward的影响会随着时间的推移而减小,因此加入折扣因子 γ 。
这样就得到了一个考虑比较全面,比较完善的梯度计算方式。
从on-policy到off-policy (反复多次使用经验)
术语和基本思想
On-policy: 学习到的agent以及和环境进行互动的agent是同一个agent
Off-policy: 学习到的agent以及和环境进行互动的agent是不同的agent
为什么要引入 Off-policy:
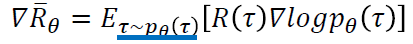
如果我们使用 πθ来收集数据,那么参数 θ 被更新后,我们需要重新对训练数据进行采样,这样会造成巨大的时间消耗。
目标:利用 πθ' 来进行采样,将采集的样本拿来训练 θ, θ'是固定的,采集的样本可以被重复使用。
原理:Important sampling:
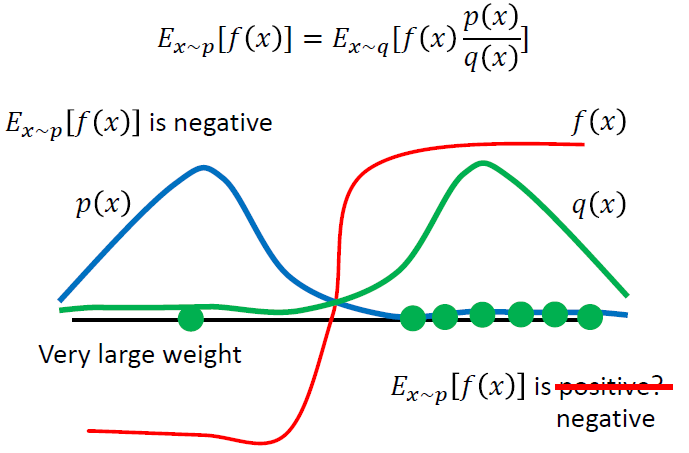
当我们只有通过另外一个分布得到的样本时,期望值可以做出以下更改,更换分布之后,需要使用重要性权重p(x)/q(x)来修正f(x),这样就实现了使用q分布来计算p分布期望值。
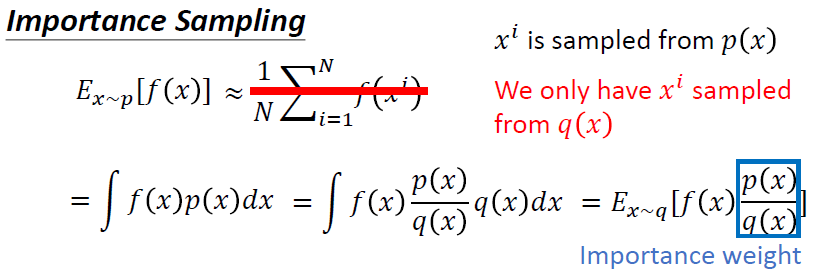
需要注意的是,两个分布p,q之间的差别不能太大,否则方差会出现较大的差别。
先基于原始的分布p计算函数的方差,然后计算引入不同分布q之后得到的函数方差,可以发现两者得出的方差表达式后面一项相同,主要差别在于前面那一项,如果分布p和q之间差别太大,会导致第一项的值较大或较小,于是造成两者较大的差别。
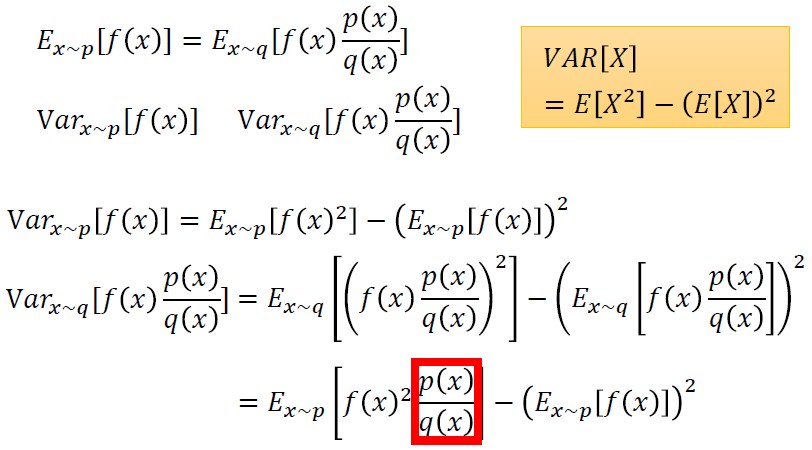
如果p,q 两个分布的差别过大,在训练的过程中就需要进行更多次数的采样。
比如下图中,实际分布p和辅助分布q差别较大,横轴左边表示收益为负,右边表示收益为正。蓝色的线表示真实分布p的分布,主要集中在左边,也就是说,真实情况下reward的期望值应该是负的。
但是由于辅助分布q,即绿色线,主要集中在右侧,因此在采样的时候采到右边的概率更大,可能会导致多轮采样之后,算出来的期望收益依旧为正,只有当采样到左侧的点,并且乘上较大的修正系数 p/q之后,算出的结果才会变成真实的符号,负号。尽管采样到右侧的点修正系数很小,最终结果可能依旧是正确的,但这样会导致在采样上耗费较大的时间,因此,p、q分布之间的差异依旧不宜过大。
从上述important sampling的思想出发,可以使用该思想来达到上文所述的目标,即 “利用 πθ' 来进行采样,将采集的样本拿来训练 θ, θ' 是固定的,采集的样本可以被重复使用” 表示为:
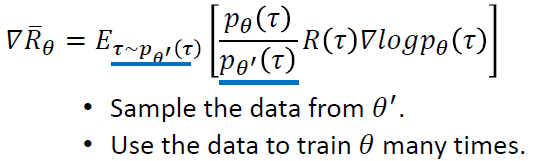
提醒 :
1.Advantage function (收益reward减去基准baseline) 也应该随着新的采样参数而变化(从基于θ'的Aθ 变为基于θ′ 的Aθ′ )
2.在不同的参数情况下,某一个状态state出现的概率几乎没有差别,因此可以将这一项近似地消掉
3.stop criteria取决于两个分布之间的差别大小

加入约束: (θ不能与 θ'差别过大)
Tip: 这是一项加在行为上的约束,而不是加在参数上的约束
PPO / TRPO:
PPO在原目标函数的基础上添加了KL divergence 部分,用来表示两个分布之前的差别,差别越大则该值越大。那么施加在目标函数上的惩罚也就越大,因此要尽量使得两个分布之间的差距小,才能保证较大的目标函数。
TRPO 与 PPO 之间的差别在于它使用了 KL divergence 作为约束。但是这使得TRPO相对而言更难计算,因此较少使用。

PPO 算法
1.初始化policy的参数θ0
2.在每一次迭代中,使用θk来和环境互动,收集状态和行动并计算对应的advantage function
3.不断更新参数,找到目标函数最优值对应的参数 θ 在训练的过程中采用适应性的KL惩罚因子:
当KL过大时,增大beta值来加大惩罚力度
当KL过小时,减小beta值来降低惩罚力度

PPO2:
Tips:
1. PPO2引入了Clip函数,意味着第二项,即蓝色的虚线必须在 1-ϵ 和 1+ϵ 之间
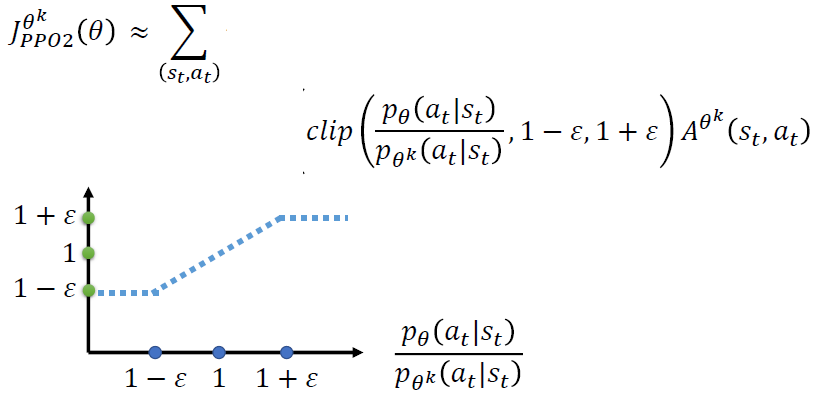
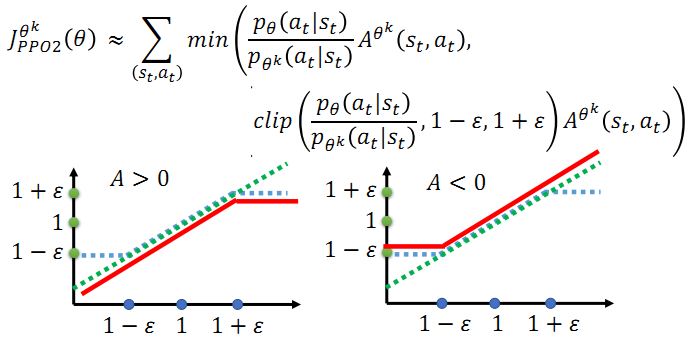
2. 红色的线表示取最小值之后整个函数值分布情况.
李宏毅老师的机器学习PPT,强化学习PPT在最后http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS18.html
转载博客https://blog.csdn.net/cindy_1102/article/details/87905272
深度学习-深度强化学习(DRL)-Policy Gradient与PPO笔记的更多相关文章
- 深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods)
深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods) 2018-07-17 16:50:12 Reference:https://www.you ...
- AI小白必读:深度学习、迁移学习、强化学习别再傻傻分不清
摘要:诸多关于人工智能的流行词汇萦绕在我们耳边,比如深度学习 (Deep Learning).强化学习 (Reinforcement Learning).迁移学习 (Transfer Learning ...
- 深度学习实战-强化学习-九宫格 当前奖励值 = max(及时奖励 + 下一个位置的奖励值 * 奖励衰减)
强化学习使用的是bellmen方程,即当前奖励值 = max(当前位置的及时奖励 + discout_factor * 下一个方向的奖励值) discount_factor表示奖励的衰减因子 使用 ...
- 深度学习之强化学习Q-Learning
1.知识点 """ 1.强化学习:学习系统没有像很多其他形式的机器学习方法一样被告知应该做什么行为, 必须在尝试之后才能发现哪些行为会导致奖励的最大化,当前的行为可能不仅 ...
- 深度学习实践-强化学习-bird游戏 1.np.stack(表示进行拼接操作) 2.cv2.resize(进行图像的压缩操作) 3.cv2.cvtColor(进行图片颜色的转换) 4.cv2.threshold(进行图片的二值化操作) 5.random.sample(样本的随机抽取)
1. np.stack((x_t, x_t, x_t, x_t), axis=2) 将图片进行串接的操作,使得图片的维度为[80, 80, 4] 参数说明: (x_t, x_t, x_t, x_t) ...
- 深度强化学习(DRL)专栏(一)
目录: 1. 引言 专栏知识结构 从AlphaGo看深度强化学习 2. 强化学习基础知识 强化学习问题 马尔科夫决策过程 最优价值函数和贝尔曼方程 3. 有模型的强化学习方法 价值迭代 策略迭代 4. ...
- 深度强化学习(DRL)专栏开篇
2015年,DeepMind团队在Nature杂志上发表了一篇文章名为"Human-level control through deep reinforcement learning&quo ...
- 深度强化学习——连续动作控制DDPG、NAF
一.存在的问题 DQN是一个面向离散控制的算法,即输出的动作是离散的.对应到Atari 游戏中,只需要几个离散的键盘或手柄按键进行控制. 然而在实际中,控制问题则是连续的,高维的,比如一个具有6个关节 ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
随机推荐
- java的多线程之入门
一.java多线程基本概念 调用run():在主线程调用子线程的run()方法会中断主线程等到子线程执行完毕之后再执行主线程. 调用start():在主线程中执行子线程的start()后会与主线程同步 ...
- 用于C# 的异步,持久的键值存储 Akavache 使用
Akavache是一个异步的,持久的(即写入磁盘)键值存储,用于在C#中编写桌面和移动应用程序,基于SQLite3.Akavache非常适合存储重要数据(即用户设置)以及过期的缓存本地数据. 开源 ...
- bzoj 1260涂色 题解
题面 区间dp, 我学的也不怎么好. myj说动态规划就是搜索的无限剪枝. 所以是搜了网上的代码, 看了看. 思路就是枚举区间,f数组就是存储从i到j需要的最少次数, 当然一开始他们的值要先设置一个很 ...
- linux实现pwd
版本1: 调用系统接口getcwd,实现路径打印. /*** ***文件名:1_mypwd.c ***描述:通过系统函数getcwd实现pwd命令 ***/ #include<stdio.h&g ...
- Centos7 更改yum源与更新系统
[1] 首先备份 /etc/yum.repos.d/CentOS-Base.repo mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/Cen ...
- Mongoose 预定义模式修饰符 Getters 与 Setters 自定义修饰符
mongoose 预定义模式修饰符 mongoose 提供的预定义模式修饰符,可以对我们增加的数据进行一些格式化,主要有:lowercase.uppercase .trim,这里不一一演示,对trim ...
- UDF——Fluent与Matlab数据耦合
本文编译工具:VC++ UDF Studio 该插件可以直接在Visual Studio中一键编译.加载.调试UDF源码,极大提高编写排错效率,且支持C++,MFC,Windows API和第三方库, ...
- OpenFOAM——孔板流量计
本算例来自<ANSYS FLUENT技术基础与工程应用:流动传热与环境污染控制领域> 一个入口,入口速度为0.0176839m/s,一个出口边界,其余为壁面边界 流体的物性参数: 密度:1 ...
- redis(三) 集群 codis
参考文档 http://blog.csdn.net/ztsinghua/article/details/48134377
- mysql将多条结果拼接成一条结果
1,实际数据 SELECT resource_id, resource_type FROM res_resource_mount 2,拼接之后数据 SELECT c.resource_id, GROU ...