[Attention Is All You Need]论文笔记
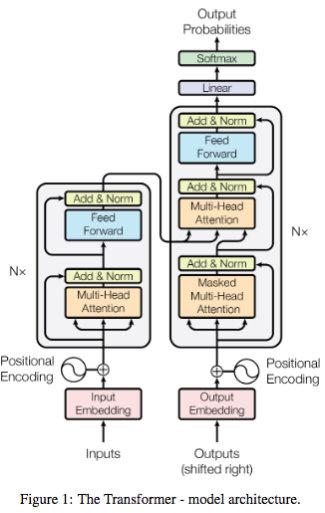
残差网络的优势
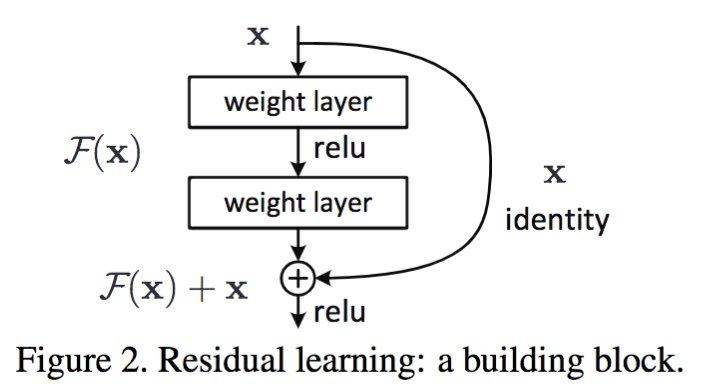
残差网络使用网络学习的是残差,能够解决网络极深度条件下性能退化问题。残差网络论文中提到残差网络不是解决梯度消失和梯度膨胀,残差网络用来解决网络层数加深,在训练集上性能变差的问题。 [为什么可以解决?] 残差网络是多个浅层网络的集成,从x到最后的输出y可以有多个路径,每个路径看作一种模型。[个人理解]
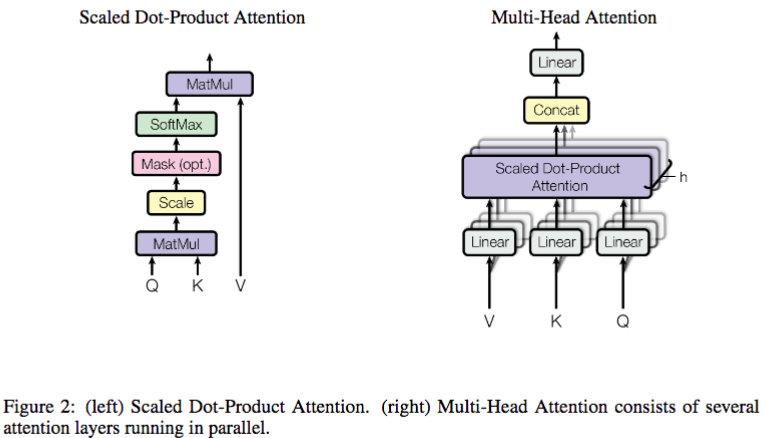
【为什么除以dk?】 假设两个 dk 维向量每个分量都是一个相互独立的服从标准正态分布的随机变量,那么他们的点乘的方差就是 dk,每一个分量除以 sqrt(d_k) 可以让点乘的方差变成 1。


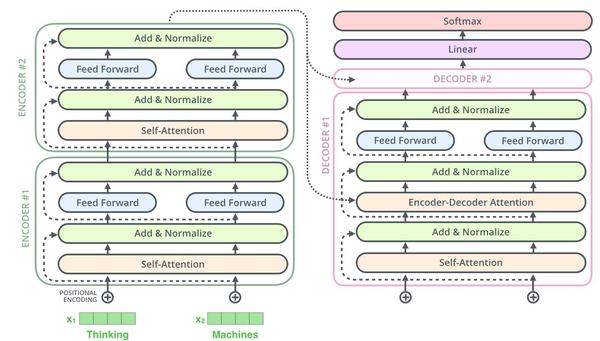

[Attention Is All You Need]论文笔记的更多相关文章
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(一)评价指标和NIC模型
看图说话(Image Caption)任务是结合CV和NLP两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字.这项任务要求模型可以识别图 ...
- Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记
Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记 arXiv 摘要:本文提出了一种 DRL 算法进行单目标跟踪 ...
- 论文笔记:语音情感识别(四)语音特征之声谱图,log梅尔谱,MFCC,deltas
一:原始信号 从音频文件中读取出来的原始语音信号通常称为raw waveform,是一个一维数组,长度是由音频长度和采样率决定,比如采样率Fs为16KHz,表示一秒钟内采样16000个点,这个时候如果 ...
- attention发展历史及其相应论文
这个论文讲述了attention机制的发展历史以及在发展过程的变体-注意力机制(Attention Mechanism)在自然语言处理中的应用 上面那个论文提到attention在CNN中应用,有一个 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
随机推荐
- Intel 8086 CPU
一.8086概述 Intel8086拥有四个16位的通用寄存器,也能够当作八个8位寄存器来存取,以及四个16位索引寄存器(包含了堆栈指标).资料寄存器通常由指令隐含地使用,针对暂存值需要复杂的寄存器配 ...
- C# 线程小结
进程与线程 什么是进程? 当一个程序开始运行时,它就是一个进程,进程包括运行中的程序和程序所使用到的内存和系统资源. 而一个进程又是由多个线程所组成的. 什么是线程? 线程是程序中的一个执行流,每个线 ...
- 过拟合和欠拟合(Over fitting & Under fitting)
欠拟合(Under Fitting) 欠拟合指的是模型没有很好地学习到训练集上的规律. 欠拟合的表现形式: 当模型处于欠拟合状态时,其在训练集和验证集上的误差都很大: 当模型处于欠拟合状态时,根本的办 ...
- GoCN每日新闻(2019-09-24)
1. Go 搭建的高效网页爬虫:https://creekorful.me/building-fast-modern-web-crawler/ 2. Go 时区处理:https://medium.co ...
- CAN信号转以太网究竟怎么回事?TCP转CAN又是什么?
首先说说can总线. can总线是目前工业控制领域应用最广的现场总线,它可以实现远距离信息的传输,是各种设备和各类功能部件之间传送信息的公用通道,它是由导线组成的传输线束,用于连接体统中的各个节点,传 ...
- 查看CPU占用工具
recording_5492_1.jfr jcmd 5942 JFR.start delay=1s duration=200s name=serverRecording filename=./reco ...
- docker技术入门(1)
1Docker技术介绍 DOCKER是一个基于LXC技术之上构建的container容器引擎,通过内核虚拟化技术(namespace及cgroups)来提供容器的资源隔离与安全保障,KVM是通过硬件实 ...
- .NET Core教程--给API加一个服务端缓存啦
以前给API接口写缓存基本都是这样写代码: // redis key var bookRedisKey = ConstRedisKey.RecommendationBooks.CopyOne(book ...
- Javascript正则RegExp对象replace方法替换url参数值
看别的博客有用eval执行正则表达式的写法, //替换指定传入参数的值,paramName为参数,replaceWith为新值 function replaceParamVal(paramName,r ...
- Android智能手机上的音频浅析【转】
本文转载自:https://blog.csdn.net/david_tym/article/details/80903385 手机可以说是现在人日常生活中最离不开的电子设备了.它自诞生以来,从模拟的发 ...