2、zookeeper原理
一、Zookeeper的角色
» 领导者(leader),负责进行投票的发起和决议,更新系统状态 » 学习者(learner),包括跟随者(follower)和观察者(observer),follower用于接受客户端请求并想客户端返回结果,在选主过程中参与投票 » Observer可以接受客户端连接,将写请求转发给leader,但observer不参加投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读取速度 » 客户端(client),请求发起方
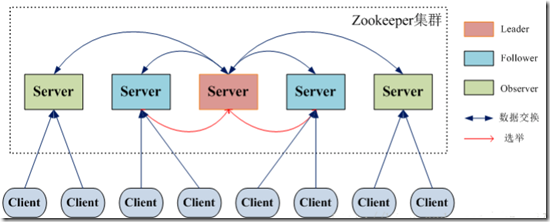
ObServer:
Observers:在不伤害写性能的情况下扩展Zookeeper 尽管通过Client直接连接到Zookeeper集群的性能已经非常好了,但是这种架构如果要承受超大规模的Client,就必须增加Zookeeper集群的Server数量,
随着Server的增加,Zookeeper集群的写性能必定下降,我们知道Zookeeper的Znode变更是要过半数投票通过,随着机器的增加,由于网络消耗等原因
必然导致投票成本增加,从而导致写性能的下降。 Observer是一种新型的Zookeeper节点,可以帮助解决上述问题,提供Zookeeper的可扩展性。Observer不参与投票,只是简单的接收投票结果,因此我们
增加再多的Observer,也不会影响集群的写性能。除了这个差别,其他的和Follower基本上完全一样。例如:Client都可以连接到他们,并且都可以发送
读写请求给他们,收到写请求都会上报到Leader。 Observer有另外一个优势,因为它不参与投票,所以他们不属于Zookeeper集群的关键部位,即使他们Failed,或者从集群中断开,也不会影响集群的可用性。
根据Observer的特点,我们可以使用Observer做跨数据中心部署。如果把Leader和Follower分散到多个数据中心的话,因为数据中心之间的网络的延迟,势必
会导致集群性能的大幅度下降。使用Observer的话,将Observer跨机房部署,而Leader和Follower部署在单独的数据中心,这样更新操作会在同一个数据中心
来处理,并将数据发送的其他数据中心(包含Observer的),然后Client就可以在其他数据中心查询数据了。但是使用了Observer并非就能完全消除数据中心
之间的延迟,因为Observer还得接收Leader的同步结果合Observer有更新请求也必须转发到Leader,所以在网络延迟很大的情况下还是会有影响的,它的优势
就为了本地读请求的快速响应。
• Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。
当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server
具有相同的系统状态。• 为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是
一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。 • 每个Server在工作过程中有三种状态: • LOOKING:当前Server不知道leader是谁,正在搜寻 • LEADING:当前Server即为选举出来的leader • FOLLOWING:leader已经选举出来,当前Server与之同步
二、Zookeeper的读写机制
» Zookeeper是一个由多个server组成的集群 » 一个leader,多个follower » 每个server保存一份数据副本 » 全局数据一致 » 分布式读写 » 更新请求转发,由leader实施
三、Zookeeper的保证
» 更新请求顺序进行,来自同一个client的更新请求按其发送顺序依次执行 » 数据更新原子性,一次数据更新要么成功,要么失败 » 全局唯一数据视图,client无论连接到哪个server,数据视图都是一致的 » 实时性,在一定事件范围内,client能读到最新数据
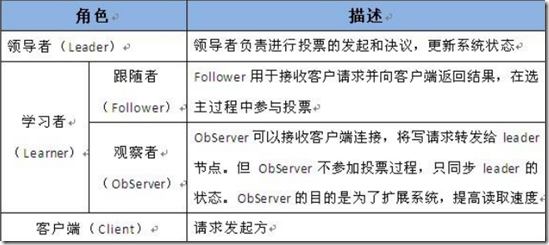
四、Zookeeper节点数据操作流程
Follower主要有四个功能:
• 1. 向Leader发送请求(PING消息、REQUEST消息、ACK消息、REVALIDATE消息); • 2 .接收Leader消息并进行处理; • 3 .接收Client的请求,如果为写请求,发送给Leader进行投票; • 4 .返回Client结果。 Follower的消息循环处理如下几种来自Leader的消息:
• 1 .PING消息: 心跳消息; • 2 .PROPOSAL消息:Leader发起的提案,要求Follower投票; • 3 .COMMIT消息:服务器端最新一次提案的信息; • 4 .UPTODATE消息:表明同步完成; • 5 .REVALIDATE消息:根据Leader的REVALIDATE结果,关闭待revalidate的session还是允许其接受消息; • 6 .SYNC消息:返回SYNC结果到客户端,这个消息最初由客户端发起,用来强制得到最新的更新。
五、Zookeeper leader选举
Leader选举模拟:
• A提案说,我要选自己,B你同意吗?C你同意吗?B说,我同意选A;C说,我同意选A。(注意,这里超过半数了,其实在现实世界选举已经成功了。
但是计算机世界是很严格,另外要理解算法,要继续模拟下去。) • 接着B提案说,我要选自己,A你同意吗;A说,我已经超半数同意当选,你的提案无效;C说,A已经超半数同意当选,B提案无效。 • 接着C提案说,我要选自己,A你同意吗;A说,我已经超半数同意当选,你的提案无效;B说,A已经超半数同意当选,C的提案无效。 • 选举已经产生了Leader,后面的都是follower,只能服从Leader的命令。而且这里还有个小细节,就是其实谁先启动谁当头。
zxid
• zxid • znode节点的状态信息中包含czxid, 那么什么是zxid呢? • ZooKeeper状态的每一次改变, 都对应着一个递增的Transaction id, 该id称为zxid. 由于zxid的递增性质, 如果zxid1小于zxid2, 那么zxid1肯定先于zxid2发生.
创建任意节点, 或者更新任意节点的数据, 或者删除任意节点, 都会导致Zookeeper状态发生改变, 从而导致zxid的值增加.
Zookeeper工作原理
» 一旦leader已经和多数的follower进行了状态同步后,他就可以开始广播消息了,即进入广播状态。这时候当一个server加入zookeeper服务中,
它会在恢复模式下启动,发现leader,并和leader进行状态同步。待到同步结束,它也参与消息广播。Zookeeper服务一直维持在Broadcast状态,
直到leader崩溃了或者leader失去了大部分的followers支持。 » 广播模式需要保证proposal被按顺序处理,因此zk采用了递增的事务id号(zxid)来保证。所有的提议(proposal)都在被提出的时候加上了zxid。
实现中zxid是一个64为的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch。低32位是个递增计数。 » 当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的server都恢复到一个正确的状态。
Leader选举:
» 每个Server启动以后都询问其它的Server它要投票给谁。 » 对于其他server的询问,server每次根据自己的状态都回复自己推荐的leader的id和上一次处理事务的zxid(系统启动时每个server都会推荐自己) » 收到所有Server回复以后,就计算出zxid最大的哪个Server,并将这个Server相关信息设置成下一次要投票的Server。 » 计算这过程中获得票数最多的的sever为获胜者,如果获胜者的票数超过半数,则改server被选为leader。否则,继续这个过程,直到leader被选举出来 » leader就会开始等待server连接 » Follower连接leader,将最大的zxid发送给leader » Leader根据follower的zxid确定同步点 » 完成同步后通知follower 已经成为uptodate状态 » Follower收到uptodate消息后,又可以重新接受client的请求进行服务了
数据一致性与paxos算法:
据说Paxos算法的难理解与算法的知名度一样令人敬仰,所以我们先看如何保持数据的一致性,这里有个原则就是: • 在一个分布式数据库系统中,如果各节点的初始状态一致,每个节点都执行相同的操作序列,那么他们最后能得到一个一致的状态。 • Paxos算法解决的什么问题呢,解决的就是保证每个节点执行相同的操作序列。好吧,这还不简单,master维护一个
全局写队列,所有写操作都必须 放入这个队列编号,那么无论我们写多少个节点,只要写操作是按编号来的,就能保证一
致性。没错,就是这样,可是如果master挂了呢。 • Paxos算法通过投票来对写操作进行全局编号,同一时刻,只有一个写操作被批准,同时并发的写操作要去争取选票,
只有获得过半数选票的写操作才会被 批准(所以永远只会有一个写操作得到批准),其他的写操作竞争失败只好再发起一
轮投票,就这样,在日复一日年复一年的投票中,所有写操作都被严格编号排 序。编号严格递增,当一个节点接受了一个
编号为100的写操作,之后又接受到编号为99的写操作(因为网络延迟等很多不可预见原因),它马上能意识到自己 数据
不一致了,自动停止对外服务并重启同步过程。任何一个节点挂掉都不会影响整个集群的数据一致性(总2n+1台,除非挂
掉大于n台)。 总结:
• Zookeeper 作为 Hadoop 项目中的一个子项目,是 Hadoop 集群管理的一个必不可少的模块,它主要用来控制集群
中的数据,如它管理 Hadoop 集群中的 NameNode,还有 Hbase 中 Master Election、Server 之间状态同步等。
Observer:
• Zookeeper需保证高可用和强一致性; • 为了支持更多的客户端,需要增加更多Server; • Server增多,投票阶段延迟增大,影响性能; • 权衡伸缩性和高吞吐率,引入Observer • Observer不参与投票; • Observers接受客户端的连接,并将写请求转发给leader节点; • 加入更多Observer节点,提高伸缩性,同时不影响吞吐率。
为什么zookeeper集群的数目,一般为奇数个?
Leader选举算法采用了Paxos协议; Paxos核心思想:当多数Server写成功,则任务数据写成功; 如果有3个Server,则两个写成功即可; 如果有4或5个Server,则三个写成功即可。 Server数目一般为奇数(3、5、7)
如果有3个Server,则最多允许1个Server挂掉;
如果有4个Server,则同样最多允许1个Server挂掉
由此,我们看出3台服务器和4台服务器的的容灾能力是一样的,所以为了节省服务器资源,一般我们采用奇数个数,作为服务器部署个数。 zookeeper有这样一个特性: 【集群中只要有超过过半的机器是正常工作的,那么整个集群对外就是可用的】 也就是说如果有2个zookeeper,那么只要有1个死了zookeeper就不能用了,因为1没有过半,所以2个zookeeper的死亡容忍度为0; 同理,要是有3个zookeeper,一个死了,还剩下2个正常的,过半了,所以3个zookeeper的容忍度为1; 同理你多列举几个:2->0;3->1;4->1;5->2;6->2会发现一个规律,2n和2n-1的容忍度是一样的, 都是n-1,所以为了更加高效,何必增加那一个不必要的zookeeper呢。
六、Zookeeper的数据模型
» 层次化的目录结构,命名符合常规文件系统规范
» 每个节点在zookeeper中叫做znode,并且其有一个唯一的路径标识
» 节点Znode可以包含数据和子节点,但是EPHEMERAL类型的节点不能有子节点
» Znode中的数据可以有多个版本,比如某一个路径下存有多个数据版本,那么查询这个路径下的数据就需要带上版本
» 客户端应用可以在节点上设置监视器
» 节点不支持部分读写,而是一次性完整读写
七、Zookeeper的节点
» Znode有两种类型,短暂的(ephemeral)和持久的(persistent)
» Znode的类型在创建时确定并且之后不能再修改
» 短暂znode的客户端会话结束时,zookeeper会将该短暂znode删除,短暂znode不可以有子节点
» 持久znode不依赖于客户端会话,只有当客户端明确要删除该持久znode时才会被删除
» Znode有四种形式的目录节点
» PERSISTENT、
» EPHEMERAL
» PERSISTENT_SEQUENTIAL、
» EPHEMERAL_SEQUENTIAL
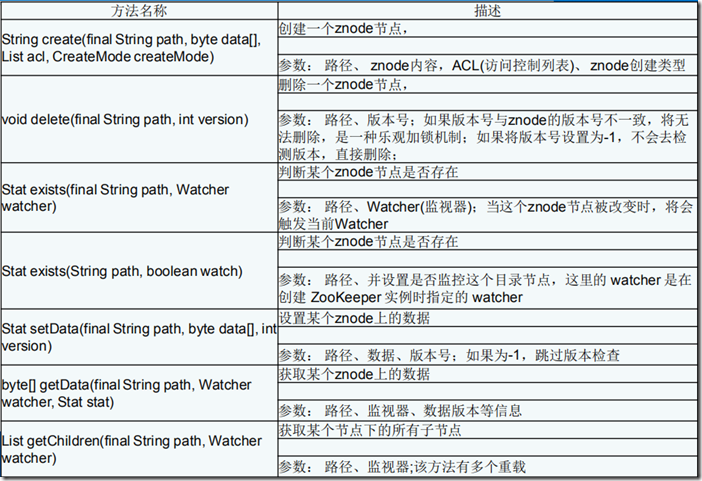
八、org.apache.zookeeper.ZooKeeper类 主要方法列表
九、观察(watcher)
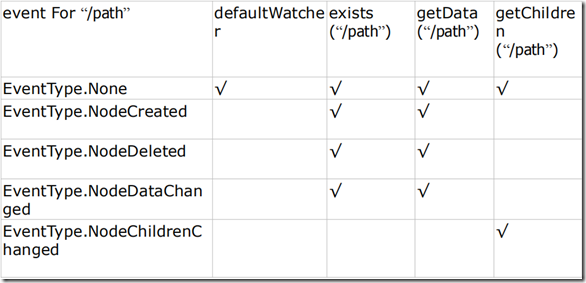
» Watcher 在 ZooKeeper 是一个核心功能,Watcher 可以监控目录节点的数据变化以及子目录的变化,一旦这些状态发生变化,服务器就会通知所有设置在这个目录节点上的 Watcher,
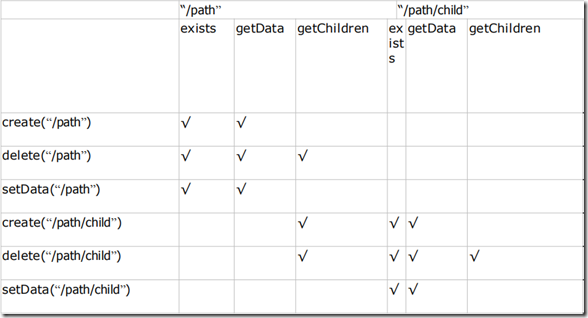
从而每个客户端都很快知道它所关注的目录节点的状态发生变化,而做出相应的反应; » 可以设置观察的操作:exists,getChildren,getData » 可以触发观察的操作:create,delete,setData
写操作与zookeeper内部事件的对应关系:
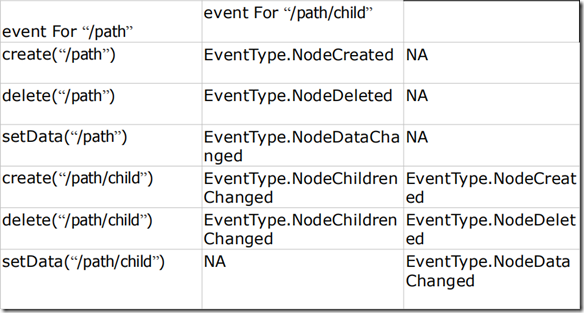
zookeeper内部事件与watcher的对应关系:
写操作与watcher的对应关系:
十、ACL
» 每个znode被创建时都会带有一个ACL列表,用于决定谁可以对它执行何种操作

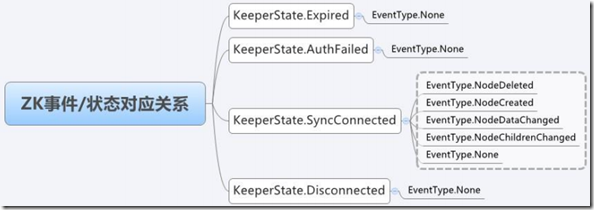
• KeeperState.SyncConnected 时事件类型为EventType.None发生在客户端收到ConnectResponse,与客户端协调好session time的时间后,
会触发一个KeeperState.SyncConnected 的None事件类型。
身份验证模式有三种:
» digest:用户名,密码
» host:通过客户端的主机名来识别客户端
» ip: 通过客户端的ip来识别客户端
» new ACL(Perms.READ,new Id("host","example.com"));
这个ACL对应的身份验证模式是host,符合该模式的身份是example.com,权限的组合是:READ
应用场景1-统一命名服务:
» 分布式应用中,通常需要有一套完整的命名规则,既能够产生唯一的名称又便于人识别和记住,通常情况下用树形的名称结构是一个理想的选择,
树形的名称结构是一个有层次的目录结构,既对人友好又不会重复。
» Name Service 是 Zookeeper 内置的功能,只要调用 Zookeeper 的 API 就能实现
应用场景2-配置管理:
» 配置的管理在分布式应用环境中很常见,例如同一个应用系统需要多台 PC Server 运行,但是它们运行的应用系统的某些配置项是相同的,
如果要修改这些相同的配置项,那么就必须同时修改每台运行这个应用系统的 PC Server,这样非常麻烦而且容易出错。 » 将配置信息保存在 Zookeeper 的某个目录节点中,然后将所有需要修改的应用机器监控配置信息的状态,一旦配置信息发生变化,每台应用机器
就会收到Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中。
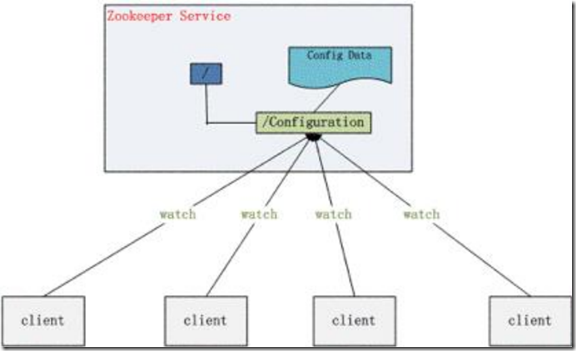
应用场景3-集群管理:
» Zookeeper 能够很容易的实现集群管理的功能,如有多台 Server 组成一个服务集群,那么必须要一个“总管”知道当前集群中每台机器的服务状态,一旦有机器
不能提供服务,集群中其它集群必须知道,从而做出调整重新分配服务策略。同样当增加集群的服务能力时,就会增加一台或多台 Server,同样也必须让“总管”知道。 » Zookeeper 不仅能够维护当前的集群中机器的服务状态,而且能够选出一个“总管”,让这个总管来管理集群,这就是 Zookeeper 的另一个功能 Leader Election。
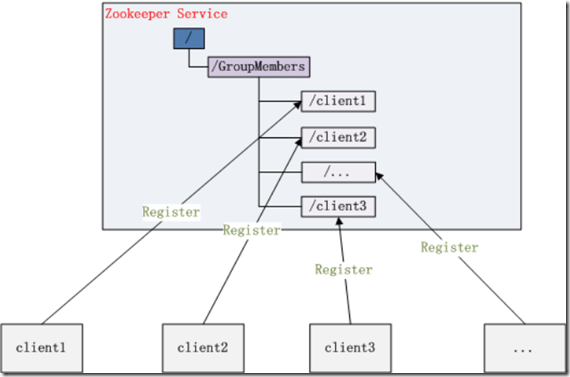
» 规定编号最小的为master,所以当我们对SERVERS节点做监控的时候,得到服务器列表,只要所有集群机器逻辑认为最小编号节点为master,那么master就被选出,
而这个master宕机的时候,相应的znode会消失,然后新的服务器列表就被推送到客户端,然后每个节点逻辑认为最小编号节点为master,这样就做到动态master选举。
总结:
» Zookeeper 作为 Hadoop 项目中的一个子项目,是Hadoop 集群管理的一个必不可少的模块,它主要用来控制集群中的数据,如它管理 Hadoop 集群中的NameNode,
还有 Hbase 中 Master Election、Server 之间状态同步等。 » Zoopkeeper 提供了一套很好的分布式集群管理的机制,就是它这种基于层次型的目录树的数据结构,并对树中的节点进行有效管理,从而可以设计出多种多样的
分布式的数据管理模型
2、zookeeper原理的更多相关文章
- Zookeeper(三) Zookeeper原理与应用
一.zookeeper原理解析 1.进群角色描述 2.Paxos 算法概述( ZAB 协议) 分布式一致性算法 3.Zookeeper 的选主(恢复模式) 以一个简单的例子来说明整个选举的过程. ...
- Zookeeper原理和实战开发经典视频教程 百度云网盘下载
Zookeeper原理和实战开发 经典视频教程 百度云网盘下载 资源下载地址:http://pan.baidu.com/s/1o7ZjPeM 密码:r5yf
- 8.8.ZooKeeper 原理和选举机制
1.ZooKeeper原理 Zookeeper虽然在配置文件中并没有指定master和slave但是,zookeeper工作时,是有一个节点为leader,其他则为follower,Leader是通 ...
- Apache ZooKeeper原理剖析及分布式理论名企高频面试v3.7.0
概述 **本人博客网站 **IT小神 www.itxiaoshen.com 定义 Apache ZooKeeper官网 https://zookeeper.apache.org/ 最新版本3.7.0 ...
- (转)Zookeeper原理和作用
本周末学习zookeeper,原理和安装配置 本文参考: http://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/ http:/ ...
- zookeeper原理解析-数据存储
Zookeeper内存结构 Zookeeper是怎么存储数据的,什么机制保证集群中数据是一致性,在网络异常,当机以及停电等异常情况下恢复数据的,我们知道数据库给我们提供了这些功能,其实zookeepe ...
- Zookeeper 原理
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等.Zookeeper是hadoop的一个子项目,其 ...
- zookeeper原理
Zookeeper与paxos算法:http://www.riaos.com/ria/11299 Paxos算法1:http://blog.csdn.net/chen77716/article/det ...
- [转]Zookeeper原理及应用场景
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等.Zookeeper是hadoop的一个子项目,其 ...
- zookeeper原理(转)
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等.Zookeeper是hadoop的一个子项目,其 ...
随机推荐
- MOOC C#笔记(一):数据类型
C#笔记 基础知识 一个C#程序主要包括以下部分: 命名空间声明(Namespace declaration) 一个 class Class 方法 Class 属性 一个 Main 方法 语句(Sta ...
- 阿里巴巴 Java 开发手册 (九) 异常日志
(一) 异常处理 1. [强制]Java 类库中定义的一类 RuntimeException 可以通过预先检查进行规避,而不应该 通过 catch 来处理,比如:IndexOutOfBoundsExc ...
- docker下安装mysql数据库
因为用了.net core 所以想学习下使用docker: 项目中刚好要用到mysql数据库,所用用docker来安装一次,我使用的是5.6版本: 1.拉取官方镜像 docker pull mysql ...
- 玩转dockerfile
镜像的缓存特性 Docker 会缓存已有镜像的镜像层,构建新镜像时,如果某镜像层已经存在,就直接使用,无需重新创建. 举例说明.在前面的 Dockerfile 中添加一点新内容,往镜像中复制一个文件: ...
- 2019 汇量科技java面试笔试题 (含面试题解析)
本人5年开发经验.18年年底开始跑路找工作,在互联网寒冬下成功拿到阿里巴巴.今日头条.汇量科技等公司offer,岗位是Java后端开发,因为发展原因最终选择去了汇量科技,入职一年时间了,也成为了面 ...
- Java web服务端参数校验Javax.validation (springboot)
一.基本使用 Javax.validation是spring集成自带的一个参数校验接口.可通过添加注解来设置校验条件. 下面以springboot项目为例进行说明.创建web项目后,不需要再添加其他的 ...
- Java跳出多重循环的方法
我们一般用break和cuntinue来控制单个循环,但是如果遇到有多个循环的情况呢,比如下面这个: for (int i=0; i<10; i++) { for (int j=0; j< ...
- (转载) @ConfigurationProperties 注解使用姿势,这一篇就够了
SpringBoot中的@ConfigurationProperties 传送门: http://www.hellojava.com/a/82613.html
- nodeJS从入门到进阶二(网络部分)
一.网络服务器 1.http状态码 1xx: 表示普通请求,没有特殊含义 2xx:请求成功 200:请求成功 3xx:表示重定向 301 永久重定向 302 临时重定向 303 使用缓存(服务器没有更 ...
- VLC架构及流程分析
0x00 前置信息 VLC是一个非常庞大的工程,我从它的架构及流程入手进行分析,涉及到一些很细的概念先搁置一边,日后详细分析. 0x01 源码结构(Android Java相关的暂未分析) # bui ...