如何开发一个异常检测系统:异常检测 vs 监督学习
异常检测算法先是将一些正常的样本做为无标签样本来学习模型p(x),即评估参数,然后用学习到的模型在交叉验证集上通过F1值来选择表现最好的ε的值,然后在测试集上进行算法的评估。这儿用到了带有标签的数据,那么为什么不直接用监督学习对y=1和y=0的数据进行学习呢?而是要用到异常检测算法(先对无标签数据进行建模(当成无标签数据,其实都是正常的样本))。
异常检测与监督学习有哪些区别?

异常检测系统中一般正例样本(即异常的样本)很少(一般0-20个或者50个,50也是很常见的),这些异常样本用于交叉验证集与测试集中;负例样本(即正常的样本)数量很大,这些正常的样本用于拟合p(x),用于拟合参数u和σ2.
监督学习中,正例样本与负例样本都一样多。
对于异常检测算法通常有多种不同种类的异常,如引起飞机引擎故障的原因有很多种,你的正例样本较少里面可能只包含了5种、10种原因,如果我们根据这些有问题的样本来建立了一个学习模型,来了一个新的有问题的样本,故障的原因不在里面,我们就很难预测出这个是否是异常的飞机引擎,因为我们从来没有见过。
如果我们有大量的正例样本,这样就可以使用监督学习构建学习算法(学习大量的正样本与负样本),这样来了一个正例样本我们就可以通过看是否与训练集中的相似来判断
关键的区别:在异常检测算法中,我们只有少量的正样本(异常情况),因此学习算法不可能从这些正样本中学到太多东西,故我们会使用大量的负样本(正常情况),从这些负样本中学习p(x),同时我们会使用那部分少量的正样本(异常情况)来评估我们的算法(用于交叉验证集与测试集).
在垃圾邮件问题中,虽然垃圾邮件的种类会非常多(如购物邮件,钓鱼邮件等),但是因为我们有很多这些垃圾邮件的样本,我们可以从这些邮件中学习到垃圾邮件识别算法,因此我们一般会使用监督学习来进行垃圾邮件的识别。
异常检测与监督学习的一些应用
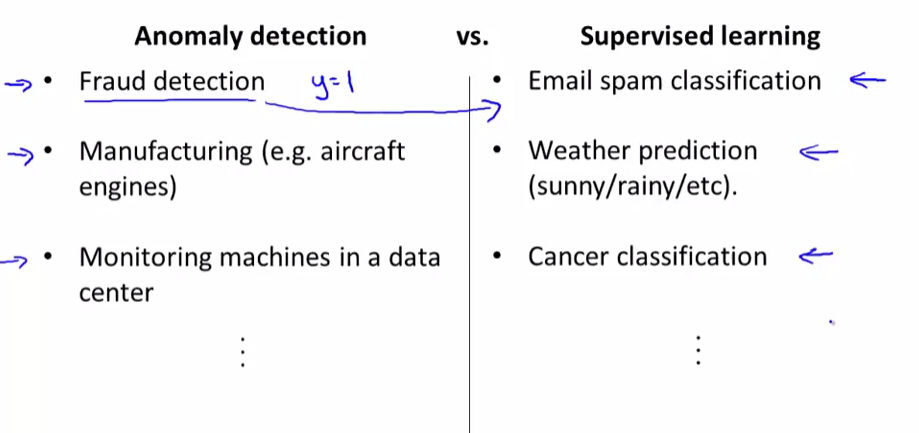
通常欺诈检测使用的是异常检测,但是如果你有大量的用户欺诈的数据,也可以使用监督学习。
在工业生产中,我们一般希望出现问题的产品很少,这时使用异常检测,如果出现问题的产品很多时,我们也可以转化为监督学习来进行学习。
总结
1>正样本(有问题的样本、异常样本)的数量很少时,使用异常检测系统
如何开发一个异常检测系统:异常检测 vs 监督学习的更多相关文章
- Django完整的开发一个博客系统
今天花了一些时间搭了一个博客系统,虽然并没有相关于界面的美化,但是发布是没问题的. 开发环境 操作系统:windows 7 64位 Django: 1.96 Python:2.7.11 IDE: Py ...
- 开发一个基于 Android系统车载智能APP
很久之前就想做一个车载相关的app.需要实现如下功能: (1)每0.2秒更新一次当前车辆的最新速度值. (2)可控制性记录行驶里程. (3)不连接网络情况下获取当前车辆位置.如(北京市X区X路X号) ...
- HBase概念学习(八)开发一个类twitter系统之表设计
这边文章先将可能的需求分析一下,设计出HBase表,下一步再開始编写client代码. TwiBase系统 1.背景 为了加深HBase基本概念的学习,參考HBase实战这本书实际动手做了这个样例. ...
- 【原创】访问Linux进程文件表导致系统异常复位的排查记录
前提知识: Linux内核.Linux 进程和文件数据结构.vmcore解析.汇编语言 问题背景: 这个问题出自项目的一个安全模块,主要功能是确定某进程是否有权限访问其正在访问的文件. 实现功能时,需 ...
- 如何开发一个异常检测系统:使用什么特征变量(features)来构建异常检测算法
如何构建与选择异常检测算法中的features 如果我的feature像图1所示的那样的正态分布图的话,我们可以很高兴地将它送入异常检测系统中去构建算法. 如果我的feature像图2那样不是正态分布 ...
- 吴恩达机器学习笔记54-开发与评价一个异常检测系统及其与监督学习的对比(Developing and Evaluating an Anomaly Detection System and the Comparison to Supervised Learning)
一.开发与评价一个异常检测系统 异常检测算法是一个非监督学习算法,意味着我们无法根据结果变量
- 基于PySpark的网络服务异常检测系统 (四) Mysql与SparkSQL对接同步数据 kmeans算法计算预测异常
基于Django Restframework和Spark的异常检测系统,数据库为MySQL.Redis, 消息队列为Celery,分析服务为Spark SQL和Spark Mllib,使用kmeans ...
- 基于PySpark的网络服务异常检测系统 阶段总结(二)
在上篇博文中介绍了网络服务异常检测的大概,本篇将详细介绍SVDD和Isolation Forest这两种算法 1. SVDD算法 SVDD的英文全称是Support Vector Data Descr ...
- 应用层级时空记忆模型(HTM)实现对实时异常流时序数据检测
应用层级时空记忆模型(HTM)实现对实时异常流时序数据检测 Real-Time Anomaly Detection for Streaming Analytics Subutai Ahmad SAHM ...
随机推荐
- jmeter 获取总的线程数
String threads="${__BeanShell(ctx.getThreadGroup().getNumThreads())}"; vars.put("thre ...
- 【题解】Luogu P5471 [NOI2019]弹跳
原题传送门 先考虑部分分做法: subtask1: 暴力\(O(nm)\)枚举,跑最短路 subtask2: 吧一行的点压到vector中并排序,二分查找每一个弹跳装置珂以到达的城市,跑最短路 sub ...
- [CF254C]Anagram(2019-11-15考试)
题目大意 给你两个长度相同的字符串\(A,B\),要求改变字符串\(A\)中最少的字符,使得字符串\(A\)在排序后和字符串\(B\)相同.输出改变后的字符串\(A\),若多解,输出字典序最小的.\( ...
- Windows下使用Nexus搭建Maven私服
A http://www.pianshen.com/article/249363068/ nexus3安装与配置 B https://www.cnblogs.com/hujunzheng/p/9 ...
- NetCore2.2开发环境搭建和2008R2部署环境搭建
开发环境: 开发工具:VS2017 系统:Win10 64位 Skd下载地址: https://dotnet.microsoft.com/download 3个都下载下载,安装dotnet-sdk-2 ...
- C#事件和委托(C#学习笔记03)
委托 1. C# 中的委托类似于 C 或 C++ 中指向函数的指针.委托表示引用某个方法的引用类型变量,运行时可以更改引用对象. 2. 特别地,委托可以用于处理事件或回调函数.并且,所有的委托类都是从 ...
- 解决v-html无法理解vue模版的问题-动态获取模版,动态插入app并使用当下app状态数据需求
很多情况下,我们需要使用动态的html作为某个dom元素的inner html,如果这个内容是标准的html的话,则v-html能够圆满满足需求,而如果内容包含了vue组件,则使用v-html就不能达 ...
- CodeForces 955D Scissors
昨晚CF比赛比较颓,今天有心情写题解就不错了QWQ 洛谷题目页面传送门 & CodeForces题目页面传送门 给定字符串\(a,b,|a|=n,|b|=m\),求是否可以在\(a\)中选\( ...
- vue 封装公用函数
Vue 函数封装 格式化浏览器时间 /** * 格式化时间 * @param params * @param blo 默认为true * @returns {string} * @constructo ...
- Object中defineProperty数据描述
Object.defineProperty是对对象中的属性进行数据描述的 使用语法: Object.defineProperty(obj,prop,descriptor) 使用示例: var data ...