hbase运行原理
HBase特点
1)海量存储
Hbase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。这与Hbase的极易扩展性息息相关。正式因为Hbase良好的扩展性,才为海量数据的存储提供了便利。
2)列式存储
这里的列式存储其实说的是列族存储,Hbase是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定。
3)极易扩展
Hbase的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS)。
通过横向添加RegionSever的机器,进行水平扩展,提升Hbase上层的处理能力,提升Hbsae服务更多Region的能力。
备注:RegionServer的作用是管理region、承接业务的访问,这个后面会详细的介绍通过横向添加Datanode的机器,进行存储层扩容,提升Hbase的数据存储能力和提升后端存储的读写能力。
4)高并发
由于目前大部分使用Hbase的架构,都是采用的廉价PC,因此单个IO的延迟其实并不小,一般在几十到上百ms之间。这里说的高并发,主要是在并发的情况下,Hbase的单个IO延迟下降并不多。能获得高并发、低延迟的服务。
5)稀疏
稀疏主要是针对Hbase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
HBase的数据模型
HBase的架构
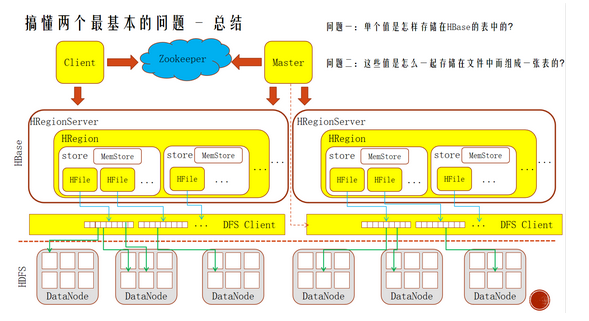
Hfile
HBase的读写缓存机制
hbase运行原理的更多相关文章
- Hbase:原理和设计
转载自:http://www.sysdb.cn/index.php/2016/01/10/hbase_principle/ ,感谢原作者. 简介 HBase —— Hadoop Database的简称 ...
- Hadoop 综合揭秘——HBase的原理与应用
前言 现今互联网科技发展日新月异,大数据.云计算.人工智能等技术已经成为前瞻性产品,海量数据和超高并发让传统的 Web2.0 网站有点力不从心,暴露了很多难以克服的问题.为此,Google.Amazo ...
- Hadoop(六)MapReduce的入门与运行原理
一 MapReduce入门 1.1 MapReduce定义 Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架: Mapreduce核心功能是将用 ...
- Hadoop运行原理总结(详细)
本编随笔是小编个人参照个人的笔记.官方文档以及网上的资料等后对HDFS的概念以及运行原理进行系统性地归纳,说起来真的惭愧呀,自学了很长一段时间也没有对Hadoop知识点进行归纳,有时候在实战中或者与别 ...
- 【HBase】二、HBase实现原理及系统架构
整个Hadoop生态中大量使用了master-slave的主从式架构,如同HDFS中的namenode和datanode,MapReduce中的JobTracker和TaskTracker,YAR ...
- Hbase概念原理扫盲
一.Hbase简介 1.什么是Hbase Hbase的原型是google的BigTable论文,收到了该论文思想的启发,目前作为hadoop的子项目来开发维护,用于支持结构化的数据存储. Hbase是 ...
- HBase 底层原理详解(深度好文,建议收藏)
HBase简介 HBase 是一个分布式的.面向列的开源数据库.建立在 HDFS 之上.Hbase的名字的来源是 Hadoop database,即 Hadoop 数据库.HBase 的计算和存储能力 ...
- iis6.0与asp.net的运行原理
这几天上网翻阅了不少前辈们的关于iis和asp.net运行原理的博客,学的有点零零散散,花了好长时间做了一个小结(虽然文字不多,但也花了不少时间呢),鄙人不才,难免有理解不道的地方,还望前辈们不吝赐教 ...
- ASP.NET Core 运行原理剖析2:Startup 和 Middleware(中间件)
ASP.NET Core 运行原理剖析2:Startup 和 Middleware(中间件) Startup Class 1.Startup Constructor(构造函数) 2.Configure ...
随机推荐
- java if 条件语句
import java.util.Scanner; public class Sample { public static void main(String[] args) { int num; Sc ...
- nginx ubantu 安装步骤
Ubuntu14.04默认安装的是Nginx 1.4.6 如果已经安装,请先卸载sudo apt-get remove nginx最新的稳定版Nginx 1.6.0在ubuntuupdates ppa ...
- 第31课 std::atomic原子变量
一. std::atomic_flag和std::atomic (一)std::atomic_flag 1. std::atomic_flag是一个bool类型的原子变量,它有两个状态set和clea ...
- git生成并添加SSH key
1.安装Git Bash https://git-scm.com/downloads 2.鼠标右键git bash here 3.执行以下命令: ① cd ~/.ssh/ [如果没有对应的文 ...
- html5手机端播放音效不卡的方法
html5手机端播放音效不卡的方法线下载http://wxserver.knowway.cn/solosea/js/audioEngine.js 这个是性能不错 然后直接播放音效就可以了 audioE ...
- 奥展项目笔记01--不同网站,点击工具--开发人员工具F12,显示的页面怎么不一样
开发人员工具F12,显示的页面不一样: 样式1: 样式2: 解决方案:兼容模式和极速模式的开发者工具不一样,改成极速模式就ok了.
- Centos7利用rsync实现文件同步
0x01 测试环境 CentOS 7.4 Rsync服务端:192.168.204.130 CentOS 7.4 Rsync客户端:192.168.204.168 0x02 rsync同步方式 第一种 ...
- c#ADO.NET 执行带参数及有返回数据
直接上代码,这个过程中有个数据SqlDataReader转为 DataTable的过程,当中为什么这样,是应为我直接绑定DataSource的时候没有数据,网人家说直接绑定但是没效果,我就转换了一下. ...
- PIE SDK矢量栅格化算法
1.算法功能简介 矢量栅格化,由矢量数据向栅格数据的转换一般比较方便.对于点.线目标,由其所在的栅格行.列数表示,对于面状目标,则需判定落人该面积内的像元.通常栅格(像元)尺寸均大于原来坐标表示的分辨 ...
- python 进程和线程-简介及进程
进程和线程的关系及应用 参考链接:https://www.liaoxuefeng.com/wiki/1016959663602400/1017627212385376 多任务: 什么叫“多任务”呢?简 ...