hbase运行原理
HBase特点
1)海量存储
Hbase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。这与Hbase的极易扩展性息息相关。正式因为Hbase良好的扩展性,才为海量数据的存储提供了便利。
2)列式存储
这里的列式存储其实说的是列族存储,Hbase是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定。
3)极易扩展
Hbase的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS)。
通过横向添加RegionSever的机器,进行水平扩展,提升Hbase上层的处理能力,提升Hbsae服务更多Region的能力。
备注:RegionServer的作用是管理region、承接业务的访问,这个后面会详细的介绍通过横向添加Datanode的机器,进行存储层扩容,提升Hbase的数据存储能力和提升后端存储的读写能力。
4)高并发
由于目前大部分使用Hbase的架构,都是采用的廉价PC,因此单个IO的延迟其实并不小,一般在几十到上百ms之间。这里说的高并发,主要是在并发的情况下,Hbase的单个IO延迟下降并不多。能获得高并发、低延迟的服务。
5)稀疏
稀疏主要是针对Hbase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
HBase的数据模型
HBase的架构
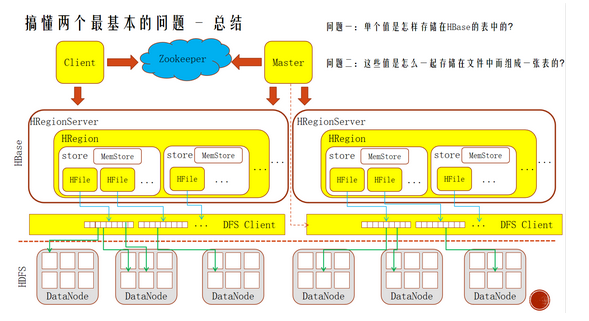
Hfile
HBase的读写缓存机制
hbase运行原理的更多相关文章
- Hbase:原理和设计
转载自:http://www.sysdb.cn/index.php/2016/01/10/hbase_principle/ ,感谢原作者. 简介 HBase —— Hadoop Database的简称 ...
- Hadoop 综合揭秘——HBase的原理与应用
前言 现今互联网科技发展日新月异,大数据.云计算.人工智能等技术已经成为前瞻性产品,海量数据和超高并发让传统的 Web2.0 网站有点力不从心,暴露了很多难以克服的问题.为此,Google.Amazo ...
- Hadoop(六)MapReduce的入门与运行原理
一 MapReduce入门 1.1 MapReduce定义 Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架: Mapreduce核心功能是将用 ...
- Hadoop运行原理总结(详细)
本编随笔是小编个人参照个人的笔记.官方文档以及网上的资料等后对HDFS的概念以及运行原理进行系统性地归纳,说起来真的惭愧呀,自学了很长一段时间也没有对Hadoop知识点进行归纳,有时候在实战中或者与别 ...
- 【HBase】二、HBase实现原理及系统架构
整个Hadoop生态中大量使用了master-slave的主从式架构,如同HDFS中的namenode和datanode,MapReduce中的JobTracker和TaskTracker,YAR ...
- Hbase概念原理扫盲
一.Hbase简介 1.什么是Hbase Hbase的原型是google的BigTable论文,收到了该论文思想的启发,目前作为hadoop的子项目来开发维护,用于支持结构化的数据存储. Hbase是 ...
- HBase 底层原理详解(深度好文,建议收藏)
HBase简介 HBase 是一个分布式的.面向列的开源数据库.建立在 HDFS 之上.Hbase的名字的来源是 Hadoop database,即 Hadoop 数据库.HBase 的计算和存储能力 ...
- iis6.0与asp.net的运行原理
这几天上网翻阅了不少前辈们的关于iis和asp.net运行原理的博客,学的有点零零散散,花了好长时间做了一个小结(虽然文字不多,但也花了不少时间呢),鄙人不才,难免有理解不道的地方,还望前辈们不吝赐教 ...
- ASP.NET Core 运行原理剖析2:Startup 和 Middleware(中间件)
ASP.NET Core 运行原理剖析2:Startup 和 Middleware(中间件) Startup Class 1.Startup Constructor(构造函数) 2.Configure ...
随机推荐
- monkey-api-encrypt 1.1.2版本发布啦
时隔10多天,monkey-api-encrypt发布了第二个版本,还是要感谢一些正在使用的朋友们,提出了一些问题. GitHub主页:https://github.com/yinjihuan/mon ...
- Navicat的安装和pymysql模块的使用
内容回顾 select distinct 字段1,字段2,... from 表名 where 分组之前的过滤条件 group by 分组条件 having 分组之后过滤条件 order by 排序字段 ...
- docker-composer 简单教程
原文地址:https://blog.51cto.com/9291927/2310444 Docker快速入门——Docker-Compose 一.Docker-Compose简介 1.Docker-C ...
- 如何在 VS2015 上开发 Qt 程序
所有Qt版本下载地址: http://download.qt.io/archive/qt/ 所有Qt Creator下载地址: http://download.qt.io/archive/qtcrea ...
- nginx 安装ab小工具方法
nginx 安装ab小工具方法测试工具安装(以centos系统为例)yum -y install httpd-tools 然后测试下ab -V
- vCenter6.7的简单安装与使用
1.VMware的vCenter已经有了很大的改进,安装过程极为简单方便. 2. 下载vCenter的安装包即可. 我这边下载的ISO为: VMware-VIM-all--.iso 网上有资源,通过百 ...
- Deep Learning专栏--FFM+Recurrent Entity Network的端到端方案
很久没有写总结了,这篇博客仅作为最近的一些尝试内容,记录一些心得.FFM的优势是可以处理高维稀疏样本的特征组合,已经在无数的CTR预估比赛和工业界中广泛应用,此外,其也可以与Deep Networks ...
- git 用 diff 来检查改动
用 diff 来检查改动 项目的开发是由无数个微小的改动组成的.了解项目开发过程的关键就是要搞清楚每一个改动.当然你可以使用 “git status” 命令或更简单的 “git log” 命令来打印出 ...
- MySQL数据库 : 高级查询
根据某个字段删除重复的数据, 只保留一条: 比如uuid字段有重复的, 需要只保留一条数据, 让uuid字段不能重复, 则首先 group by uuid 查出所有数据的id最小的那条数据,作为dt表 ...
- Redis(八) LRU Cache
Redis(八)-- LRU Cache 在计算机中缓存可谓无所不在,无论还是应用还是操作系统中,为了性能都需要做缓存.然缓存必然与缓存算法息息相关,LRU就是其中之一.笔者在最先接触LRU是大学学习 ...