pandas绘制矩阵散点图(scatter_matrix)的方法
以 sklearn的iris样本为数据集
import matplotlib.pyplot as plt
from scipy import sparse
import numpy as np
import matplotlib as mt
import pandas as pd
from IPython.display import display
from sklearn.datasets import load_iris
import sklearn as sk
from sklearn.model_selection import train_test_split iris=load_iris()
#print(iris)
X_train,X_test,y_train,y_test = train_test_split(iris['data'],iris['target'],random_state=0)
iris_dataframe = pd.DataFrame(X_train,columns=iris.feature_names)
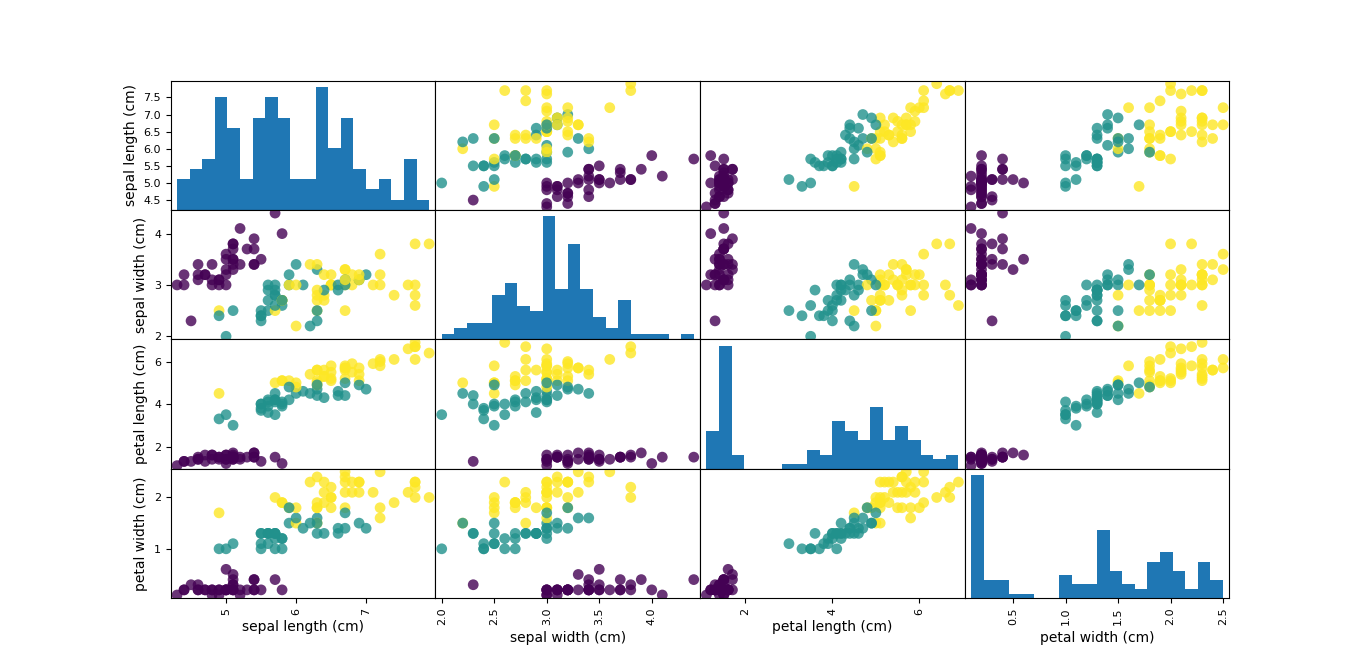
grr = pd.plotting.scatter_matrix(iris_dataframe,c=y_train,figsize=(15,15),marker='o',hist_kwds={'bins':20},s=60,alpha=.8)
plt.show()
pandas绘制矩阵散点图(scatter_matrix)的方法的更多相关文章
- Python 的 Pandas 对矩阵的行进行求和
Python 的 Pandas 对矩阵的行进行求和: 若使用 df.apply(sum) 方法的话,只能对矩阵的列进行求和,要对矩阵的行求和,可以先将矩阵转置,然后应用 df.apply(sum) 即 ...
- pandas重置索引的几种方法探究
pandas重置索引的几种方法探究 reset_index() reindex() set_index() 函数名字看起来非常有趣吧! 不仅如此. 需要探究. http://nbviewer.jupy ...
- 编程计算2×3阶矩阵A和3×2阶矩阵B之积C。 矩阵相乘的基本方法是: 矩阵A的第i行的所有元素同矩阵B第j列的元素对应相乘, 并把相乘的结果相加,最终得到的值就是矩阵C的第i行第j列的值。 要求: (1)从键盘分别输入矩阵A和B, 输出乘积矩阵C (2) **输入提示信息为: 输入矩阵A之前提示:"Input 2*3 matrix a:\n" 输入矩阵B之前提示
编程计算2×3阶矩阵A和3×2阶矩阵B之积C. 矩阵相乘的基本方法是: 矩阵A的第i行的所有元素同矩阵B第j列的元素对应相乘, 并把相乘的结果相加,最终得到的值就是矩阵C的第i行第j列的值. 要求: ...
- (数据科学学习手札131)pandas中的常用字符串处理方法总结
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在日常开展数据分析的过程中,我们经常需要对 ...
- Pandas查询数据的几种方法
Pandas查询数据 Pandas查询数据的几种方法 df.loc方法,根据行.列的标签值查询 df.iloc方法,根据行.列的数字位置查询 df.where方法 df.query方法 .loc既能查 ...
- Canvas里绘制矩阵文字
效果如下 实现方法: [ [0,0,1,1,1,0,0], [0,1,1,0,1,1,0], [1,1,0,0,0,1,1], [1,1,0,0,0,1,1], [1,1,0,0,0,1,1], [1 ...
- [Python]scatter_matrix报错 module 'pandas' has no attribute 'scatter_matrix'
运行pandas.scatter_matrix()散点图函数时报错, 原因是该函数在新版本用法发生了变化: pandas.plotting.scatter_matrix 完整用法:pd.plottin ...
- 用matplotlib和pandas绘制股票MACD指标图,并验证化交易策略
我的新书<基于股票大数据分析的Python入门实战>于近日上架,在这篇博文向大家介绍我的新书:<基于股票大数据分析的Python入门实战>里,介绍了这本书的内容.这里将摘录出部 ...
- 【笔记5】用pandas实现矩阵数据格式的推荐算法 (基于物品的协同)
''' 基于物品的协同推荐 矩阵数据 说明: 1.修正的余弦相似度是一种基于模型的协同过滤算法.我们前面提过,这种算法的优势之 一是扩展性好,对于大数据量而言,运算速度快.占用内存少. 2.用户的评价 ...
随机推荐
- 五.Protobuf3 枚举
Protobuf3 枚举 定义消息类型时,您可能希望它的一个字段有一个预定义的值列表.例如,假设您希望为每个SearchRequest添加一个corpus字段,其中语料库可以是UNIVERSAL.WE ...
- c++中形参为引用和非引用时调用构造函数
#include<iostream> using namespace std; class numbered { private:static int seq; public: numbe ...
- 修改Windows10 命令终端cmd的编码为UTF-8
1. 临时修改 进入cmd窗口后,直接执行 chcp 2. 永久修改 在运行中输入regedit,找到HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Command Pro ...
- laravel5.8 编译laravel mix
如果第一次无需执行(如果编译的时候出错再次执行才需要) 1:rm -rf node_modules 更改镜像为淘宝镜像 2:yarn config set registry https://regis ...
- sizeof的注意点
sizeof('a')的值为4.因为此处‘a’是独立存在的一个字符(没有赋值给其它变量),实际上就是一个整型数,占4个字节,即此处‘a’对应的ascii码的十进制为整数97.(貌似解释得有些牵强,但事 ...
- P4462 [CQOI2018]异或序列 莫队
题意:给定数列 \(a\) 和 \(k\) ,询问区间 \([l,r]\) 中有多少子区间满足异或和为 \(k\). 莫队.我们可以记录前缀异或值 \(a_i\),修改时,贡献为 \(c[a_i\bi ...
- asp.net文件夹上传下载组件
ASP.NET上传文件用FileUpLoad就可以,但是对文件夹的操作却不能用FileUpLoad来实现. 下面这个示例便是使用ASP.NET来实现上传文件夹并对文件夹进行压缩以及解压. ASP.NE ...
- jsp页面解析出错,或出现下载情况.
当没有下面代码时,会出现空白页的bug <dependency> <groupId>org.apache.tomcat.embed</groupId> <ar ...
- 洛谷P1288取数游戏2
题目 博弈论. 考虑先手和后手的关系.然后可以通过统计数值不是0的数的个数来得出答案. \(Code\) #include <bits/stdc++.h> using namespace ...
- js 的数组怎么push一个对象. Js数组的操作push,pop,shift,unshift JavaScrip
push()函数用于向当前数组的添加一个或多个元素,并返回新的数组长度.新的元素将会依次添加到数组的末尾. 该函数属于Array对象,所有主流浏览器均支持该函数. 语法 array.push( ite ...