elasticsearch的数据写入流程及优化
Elasticsearch 写入流程及优化
一、 集群分片设置:
ES一旦创建好索引后,就无法调整分片的设置,而在ES中,一个分片实际上对应一个lucene 索引,而lucene索引的读写会占用很多的系统资源,因此,分片数不能设置过大;所以,在创建索引时,合理配置分片数是非常重要的。一般来说,我们遵循一些原则:
1. 控制每个分片占用的硬盘容量不超过ES的最大JVM的堆空间设置(一般设置不超过32G,参加上文的JVM设置原则),因此,如果索引的总容量在500G左右,那分片大小在16个左右即可;当然,最好同时考虑原则2。
2. 考虑一下node数量,一般一个节点有时候就是一台物理机,如果分片数过多,大大超过了节点数,很可能会导致一个节点上存在多个分片,一旦该节点故障,即使保持了1个以上的副本,同样有可能会导致数据丢失,集群无法恢复。所以, 一般都设置分片数不超过节点数的3倍。
二、 Mapping建模:
1. 尽量避免使用nested或 parent/child,能不用就不用;nested query慢, parent/child query 更慢,比nested query慢上百倍;因此能在mapping设计阶段搞定的(大宽表设计或采用比较smart的数据结构),就不要用父子关系的mapping。
2. 如果一定要使用nested fields,保证nested fields字段不能过多,目前ES默认限制是50。参考:
index.mapping.nested_fields.limit :50
因为针对1个document, 每一个nested field, 都会生成一个独立的document, 这将使Doc数量剧增,影响查询效率,尤其是JOIN的效率。
3. 避免使用动态值作字段(key), 动态递增的mapping,会导致集群崩溃;同样,也需要控制字段的数量,业务中不使用的字段,就不要索引。控制索引的字段数量、mapping深度、索引字段的类型,对于ES的性能优化是重中之重。以下是ES关于字段数、mapping深度的一些默认设置:
index.mapping.nested_objects.limit :10000
index.mapping.total_fields.limit:1000
index.mapping.depth.limit: 20
三,Elasticsearch写入索引数据的过程 以及优化写入过程
完整elasticsearch的写入数据流程如下:
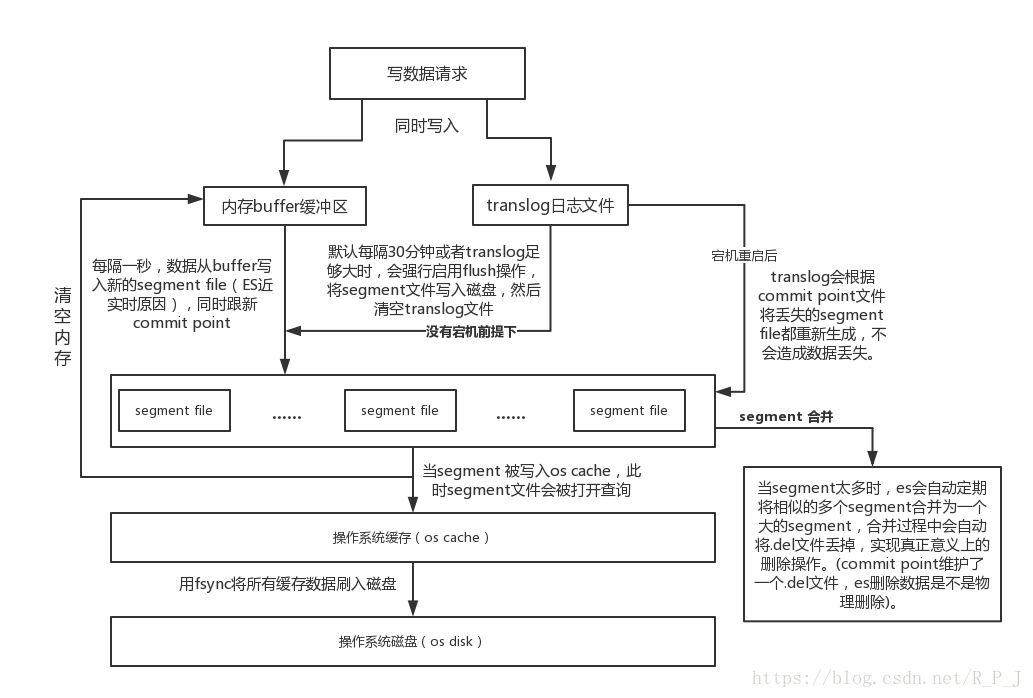
上图补充:将es中比较困惑的几个概念简单总结一下,这三种操作对理解es底层原理和优化很有帮助!
refresh
es接收数据请求时先存入内存中,默认每隔一秒会从内存buffer中将数据写入filesystem cache,这个过程叫做refresh;
fsync
translog会每隔5秒或者在一个变更请求完成之后执行一次fsync操作,将translog从缓存刷入磁盘,这个操作比较耗时,如果对数据一致性要求不是跟高时建议将索引改为异步,如果节点宕机时会有5秒数据丢失;
flush
es默认每隔30分钟会将filesystem cache中的数据刷入磁盘同时清空translog日志文件,这个过程叫做flush。
四, Lucene操作document的流程
Lucene将index数据分为segment(段)进行存储和管理.
Lucene中, 倒排索引一旦被创建就不可改变, 要添加或修改文档, 就需要重建整个倒排索引, 这就对一个index所能包含的数据量, 或index可以被更新的频率造成了很大的限制.
为了在保留不变性的前提下实现倒排索引的更新, Lucene引入了一个新思路: 使用更多的索引, 也就是通过增加新的补充索引来反映最新的修改, 而不是直接重写整个倒排索引.
1,添加document的流程
① 将数据写入buffer(内存缓冲区);
② 执行commit操作: buffer空间被占满, 其中的数据将作为新的 index segment 被commit到文件系统的cache(缓存)中;
③ cache中的index segment通过fsync强制flush到系统的磁盘上;
④ 写入磁盘的所有segment将被记录到commit point(提交点)中, 并写入磁盘;
④ 新的index segment被打开, 以备外部检索使用;
⑤ 清空当前buffer缓冲区, 等待接收新的文档.
indexing buffer优化说明如下:
(a)
fsync是一个Unix系统调用函数, 用来将内存缓冲区buffer中的数据存储到文件系统. 这里作了优化, 是指将文件缓存cache中的所有segment刷新到磁盘的操作.(b) 修改index_buffer_size 的设置,可以设置成百分数,也可设置成具体的大小,大小可根据集群的规模做不同的设置测试。indices.memory.index_buffer_size:10%(默认,可优化30%写入配置文件)
(c) 每个Shard都有一个提交点(commit point), 其中保存了当前Shard成功写入磁盘的所有segment.
2,优化写入流程 - 实现近实时搜索
(1) 现有流程的问题:
插入的新文档必须等待fsync操作将segment强制写入磁盘后, 才可以提供搜索.而 fsync操作的代价很大, 使得搜索不够实时.
(2) 改进写入流程:
① 将数据写入buffer(内存缓冲区);
② 不等buffer空间被占满, 而是每隔一定时间(默认1s), 其中的数据就作为新的index segment被commit到文件系统的cache(缓存)中;
③ index segment 一旦被写入cache(缓存), 就立即打开该segment供搜索使用;
④ 清空当前buffer缓冲区, 等待接收新的文档.
优化的地方: 过程②和过程③:
segment进入操作系统的缓存中就可以提供搜索, 这个写入和打开新segment的轻量过程被称为
refresh.
优化refresh的间隔:
Elasticsearch中, 每个Shard每秒都会自动refresh一次, 所以ES是近实时的, 数据插入到可以被搜索的间隔默认是1秒
(1) 手动refresh —— 测试时使用, 正式生产中请减少使用:
# 刷新所有索引:
POST _refresh
# 刷新某一个索引:
POST index/_refresh
(2) 手动设置refresh间隔 —— 若要优化索引速度, 而不注重实时性, 可以降低刷新频率:
# 在已有索引中设置, 间隔10秒:
PUT /_all/_settings
{
"index":{
"refresh_interval":"120s"
}
}
(3) 当你在生产环境中建立一个大的新索引时, 可以先关闭自动刷新, 要开始使用该索引时再改回来:
# 关闭自动刷新:
PUT /_all/_settings
{
"refresh_interval": -
}
(4)调小索引副本数,通过增大refresh间隔周期,同时不设置副本来提高写性能。
api执行方式:
PUT /_all/_settings
{"number_of_replicas":""}
命令接口执行方式:
curl -XPUT '192.168.115.98:9200/_all/_settings' -H 'Content-Type: application/json' -d '{"index":{"refresh_interval":"1200s","number_of_replicas":"0"}}'
开启x-pack用户密码后执行方式:
curl -XPUT '192.168.115.98:9200/_all/_settings' -uelastic:Ericss0n -H 'Content-Type: application/json' -d '{"index":{"refresh_interval":"120s","number_of_replicas":"0"}}'
3,优化写入流程 - 实现持久化变更
Elasticsearch通过事务日志(translog)来防止数据的丢失 —— durability持久化.
(1)文档持久化到磁盘的流程
① 索引数据在写入内存buffer(缓冲区)的同时, 也写入到translog日志文件中;
② 每隔refresh_interval的时间就执行一次refresh:
(a) 将buffer中的数据作为新的 index segment, 刷到文件系统的cache(缓存)中;
(b) index segment一旦被写入文件cache(缓存), 就立即打开该segment供搜索使用;
③ 清空当前内存buffer(缓冲区), 等待接收新的文档;
④ 重复①~③, translog文件中的数据不断增加;
⑤ 每隔一定时间(默认30分钟), 或者当translog文件达到一定大小时, 发生flush操作, 并执行一次全量提交:
(a) 将此时内存buffer(缓冲区)中的所有数据写入一个新的segment, 并commit到文件系统的cache中;
(b) 打开这个新的segment, 供搜索使用;
(c) 清空当前的内存buffer(缓冲区);
(d) 将translog文件中的所有segment通过
fsync强制刷到磁盘上;(e) 将此次写入磁盘的所有segment记录到commit point中, 并写入磁盘;
(f) 删除当前translog, 创建新的translog接收下一波创建请求.
4,基于translog和commit point的数据恢复
(1) 关于translog的配置:
flush操作 = 将translog中的记录刷到磁盘上 + 更新commit point信息 + 清空translog文件.
Elasticsearch默认: 每隔30分钟就flush一次;
或者: 当translog文件的大小达到上限(默认为512MB)时主动触发flush.
相关配置为:
# 发生多少次操作(累计多少条数据)后进行一次flush, 默认是unlimited:
index.translog.flush_threshold_ops # 当translog的大小达到此预设值时, 执行一次flush操作, 默认是512MB:
index.translog.flush_threshold_size # 每隔多长时间执行一次flush操作, 默认是30min:
index.translog.flush_threshold_period # 检查translog、并执行一次flush操作的间隔. 默认是5s: ES会在5-10s之间进行一次操作:
index.translog.sync_interval
(2) 数据的故障恢复:
① 增删改操作成功的标志: segment被成功刷新到Primary Shard和其对应的Replica Shard的磁盘上, 对应的操作才算成功.
② translog文件中存储了上一次flush(即上一个commit point)到当前时间的所有数据的变更记录. —— 即translog中存储的是还没有被刷到磁盘的所有最新变更记录.
③ ES发生故障, 或重启ES时, 将根据磁盘中的commit point去加载已经写入磁盘的segment, 并重做translog文件中的所有操作, 从而保证数据的一致性.
(3) 异步刷新translog:
为了保证不丢失数据, 就要保护translog文件的安全:
Elasticsearch 2.0之后, 每次写请求(如index、delete、update、bulk等)完成时, 都会触发
fsync将translog中的segment刷到磁盘, 然后才会返回200 OK的响应;或者: 默认每隔5s就将translog中的数据通过
fsync强制刷新到磁盘.
—— 提高数据安全性的同时, 降低了一点性能.
==> 频繁地执行fsync操作, 可能会产生阻塞导致部分操作耗时较久. 如果允许部分数据丢失, 可设置异步刷新translog来提高效率.优化如下:
PUT /_all/_settings
{
"index.translog.durability": "async",
"index.translog.flush_threshold_size":"1024mb",
"index.translog.sync_interval": "120s"
}
命令接口执行方式:
curl -XPUT '192.168.115.98:9200/_all/_settings' -H 'Content-Type: application/json' -d '{"index":{"translog.durability": "async","translog.flush_threshold_size":"1024mb","translog.sync_interval": "120s"}}'
5,优化写入流程 - 实现海量segment文件的归并
由上述近实时性搜索的描述, 可知ES默认每秒都会产生一个新的segment文件, 而每次搜索时都要遍历所有的segment, 这非常影响搜索性能.
为解决这一问题, ES会对这些零散的segment进行merge(归并)操作, 尽量让索引中只保有少量的、体积较大的segment文件.
这个过程由独立的merge线程负责, 不会影响新segment的产生.
同时, 在merge段文件(segment)的过程中, 被标记为deleted的document也会被彻底物理删除.
1,merge操作的流程
① 选择一些有相似大小的segment, merge成一个大的segment;
② 将新的segment刷新到磁盘上;
③ 更新commit文件: 写一个新的commit point, 包括了新的segment, 并删除旧的segment;
④ 打开新的segment, 完成搜索请求的转移;
⑤ 删除旧的小segment.
2,优化merge的配置项
segment的归并是一个非常消耗系统CPU和磁盘IO资源的任务, 所以ES对归并线程提供了限速机制, 确保这个任务不会过分影响到其他任务.
segment合并;索引节点粒度配置,segment默认最小值2M,不过有时候合并会拖累写入速率
PUT /_all/_settings
{
"index.merge.policy.floor_segment":"10mb"
}
(1) 归并线程的数目:
推荐设置为CPU核心数的一半, 如果磁盘性能较差, 可以适当降低配置, 避免发生磁盘IO堵塞,所以我们需要降低每个索引并发访问磁盘的线程数。这个设置允许 max_thread_count + 2 个线程同时进行磁盘操作,也就是设置为 1 允许三个线程。
PUT /_all/_settings
{
"index.merge.scheduler.max_thread_count" : "1"
}
(2) 其他策略:
# 优先归并小于此值的segment, 默认是2MB:
index.merge.policy.floor_segment # 一次最多归并多少个segment, 默认是10个:
index.merge.policy.max_merge_at_once #如果堆栈经常有很多merge,则可以调整配置,默认是10个,其应该大于等于index.merge.policy.max_merge_at_once。
index.merge.policy.segments_per_tier # 一次直接归并多少个segment, 默认是30个
index.merge.policy.max_merge_at_once_explicit # 大于此值的segment不参与归并, 默认是5GB. optimize操作不受影响,可以考虑适当降低此值
index.merge.policy.max_merged_segment
命令接口执行方式:
curl -XPUT '192.168.115.98:9200/_all/_settings' -H 'Content-Type: application/json' -d '{"index":{"merge.scheduler.max_thread_count":"1","merge.policy.floor_segment":"10mb","merge.policy.segments_per_tier":"20"}}'
五,Cache的设置及使用:
a) QueryCache: ES查询的时候,使用filter查询会使用query cache, 如果业务场景中的过滤查询比较多,建议将querycache设置大一些,以提高查询速度。
indices.queries.cache.size: 10%(默认),可设置成百分比,也可设置成具体值,如256mb。(可写入配置文件)
当然也可以禁用查询缓存(默认是开启), 通过index.queries.cache.enabled:false设置。
b) FieldDataCache: 在聚类或排序时,field data cache会使用频繁,因此,设置字段数据缓存的大小,在聚类或排序场景较多的情形下很有必要,可通过indices.fielddata.cache.size:30% 或具体值10GB来设置。但是如果场景或数据变更比较频繁,设置cache并不是好的做法,因为缓存加载的开销也是特别大的。
c) ShardRequestCache: 查询请求发起后,每个分片会将结果返回给协调节点(Coordinating Node), 由协调节点将结果整合。
如果有需求,可以设置开启; 通过设置index.requests.cache.enable: true来开启。
不过,shard request cache只缓存hits.total, aggregations, suggestions类型的数据,并不会缓存hits的内容。也可以通过设置indices.requests.cache.size: 1%(默认)来控制缓存空间大小。
六,查看所有的索引设置
GET /_all/_settings
注意:以上index索引优化,ES2.0后不能直接写入配置文件所以可以通过api调用或者用shell脚本添加crontab做任务定时优化索引
elasticsearch的数据写入流程及优化的更多相关文章
- HBase - 数据写入流程解析
本文由 网易云发布. 作者:范欣欣 本篇文章仅限内部分享,如需转载,请联系网易获取授权. 众所周知,HBase默认适用于写多读少的应用,正是依赖于它相当出色的写入性能:一个100台RS的集群可以轻松 ...
- Elasticsearch Lucene 数据写入原理 | ES 核心篇
前言 最近 TL 分享了下 <Elasticsearch基础整理>https://www.jianshu.com/p/e8226138485d ,蹭着这个机会.写个小文巩固下,本文主要讲 ...
- Elasticsearch(GEO)数据写入和空间检索
Elasticsearch简介 什么是 Elasticsearch? Elasticsearch 是一个开源的分布式 RESTful搜索和分析引擎,能够解决越来越多不同的应用场景. 本文内容 本文主要 ...
- ELK系列二:Elasticsearch的架构原理和配置优化
1.Elasticsearch的数据组织架构 1.1.Elasticsearch结构概念 集群(cluster):拥有相同cluster-name的elasticsearch结点的集合(每个结点其实就 ...
- HBase数据读写流程(1.3.1)
===数据写入流程=== 源码:https://github.com/apache/hbase/blob/master/hbase-server/src/main/java/org/apache/ha ...
- [转帖]时序数据库技术体系 – InfluxDB TSM存储引擎之数据写入
时序数据库技术体系 – InfluxDB TSM存储引擎之数据写入 http://hbasefly.com/2018/03/27/timeseries-database-6/ 2018年3月27日 ...
- ES 18 - (底层原理) Elasticsearch写入索引数据的过程 以及优化写入过程
目录 1 Lucene操作document的流程 1.1 添加document的流程 1.2 删除document的流程 2 优化写入流程 - 实现近实时搜索 2.1 流程的改进思路 2.2 设置re ...
- hbase大规模数据写入的优化历程
业务背景:由于需要将ngix日志过滤出来的1亿+条用户行为记录存入Hbase数据库,以此根据一定的条件来提供近实时查询,比如根据用户id及一定的时间段等条件来过滤符合要求的若干行为记录,满足这一场景的 ...
- 通过Hive将数据写入到ElasticSearch
我在<使用Hive读取ElasticSearch中的数据>文章中介绍了如何使用Hive读取ElasticSearch中的数据,本文将接着上文继续介绍如何使用Hive将数据写入到Elasti ...
随机推荐
- 【python】raise_for_status()抛出requests.HTTPError错误
1.首先看下面代码的运行情况 import requests res = requests.get("https://www.csdn.net/eee", headers=head ...
- test20190909 Gluttony
0+0+0+0+0+0=0.毒瘤出题人. BJOI2019 勘破神机 地灾军团的军师黑袍从潜伏在精灵高层的密探手中得知了神杖的情报,他对奥术宝石中蕴含的远古神秘力量十分感兴趣.他设计夺取了数块奥术宝石 ...
- 浅入不深出--vuex的简单使用
什么是vuex,官网的描述是:Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式.状态管理模式包含3个部分: 1.state,驱动应用的数据源: 2.view,以声明方式将state映射到 ...
- K-Nearest Neighbors Algorithm
K近邻算法. KNN算法非常简单,非常有效.KNN算法适合样本较少典型性较好的样本集. KNN的模型表示是整个训练数据集.也可以说是:KNN的特点是完全跟着数据走,没有数学模型可言. 对一个新的数据点 ...
- L1219
八皇后问题. 然而重点在于判断斜线attack问题和 剪枝问题, 不过判断斜线这些东西都挺有意思的. 是坐标的思想但是 有不一样, 因为这个棋盘.. 斜线判断是可以理解了. 但是我想知道的是这个的原理 ...
- 浅谈H5图片中object-fit的属性及含义/ 小程序image mode属性中scaleToFill,aspectFit,widthFix等类似
我们在H5中对于图片的属性包含如下: object-fit属性有哪些值呢? object-fit: fill; object-fit: contain; object-fit: cover; o ...
- Why We Changed YugaByte DB Licensing to 100% Open Source
转自:https://blog.yugabyte.com/why-we-changed-yugabyte-db-licensing-to-100-open-source/ 主要说明了YugaByte ...
- dinoql 使用graphql 语法查询javascript objects
dinoql 是一个不错的基于graphql 语法查询javascript objects 的工具包,包含以下特性 graphql 语法(很灵活) 安全的访问(当keys 不存在的时候,不会抛出运行时 ...
- JavaScript高级程序编程(二)
JavaScript 基本概念 1.区分大小写,变量名test与Test 是两个不同的变量,且函数命名不能使用关键字/保留字, 变量命名规范: 开头字符必须是字母,下划线,或者美元符号,ECMAScr ...
- 03-树2 List Leaves (25 分)
Given a tree, you are supposed to list all the leaves in the order of top down, and left to right. I ...