爬虫--Scrapy-参数等级和请求传参
日志等级
日志等级(种类):
ERROR:错误
WARNING:警告
INFO:一般信息
DEBUG:调试信息(默认)
指定输入某一中日志信息:
settings:LOG_LEVEL = ‘ERROR’
将日志信息存储到制定文件中,而并非显示在终端里:
settings:LOG_FILE = ‘log.txt’ 请求传参:爬取的数据值不在同一个页面中。
需求:将id97电影网站中电影详情数据进行爬取(名称,类型,导演,语言,片长)
如何让终端显示错误信息
在settings.py中配置
# 指定终端输入指定种类日志信息
LOG_LEVEL = 'ERROR'
# 存储到文件
LOG_FILE = 'log.txt'
请求传参
请求传参:爬取的数据值不在同一个页面中。
(id97电影网站) 在电影网站中电影详情数据进行爬取(名称,类型,导演,语言,片长)
创建moviePro工程
scrapy startproject moviePro
cd moviePro
scrapy genspider movie www.id97.com

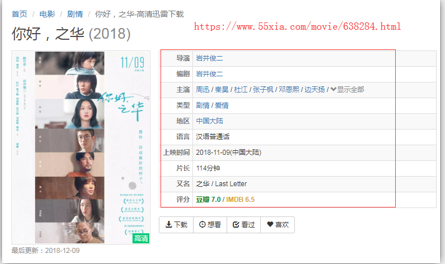
电影名称和类型在一页
电影的其他详情在另外一页
爬虫文件movie.py
import scrapy
from moviePro.items import MovieproItem class MovieSpider(scrapy.Spider):
name = 'movie'
#allowed_domains = ['www.id97.com']
start_urls = ['https://www.55xia.com/movie']
print(' start_urls') # 用于解析二级页面数据 def parseBySecondPage(self,response):
# 直接复制网页端的xpath
director = response.xpath('/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[1]/td[1]/span/text()').extract_first()
language = response.xpath('/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[6]/td[2]/text()').extract_first()
longTime = response.xpath('/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[8]/td[2]/text()').extract_first()
# 取出Request方法的meta参数传递过来的字典(response.meta)
item = response.meta['item']
item['director'] = director
item['language'] = language
item['longTime'] = longTime
# 将item提交给管道
print('将item提交给管道')
yield item def parse(self, response):
# 需求:将id97电影网站中电影详情数据进行爬取(名称,类型,导演,语言,片长)
div_list = response.xpath('/html/body/div[1]/div[1]/div[2]/div')
for div in div_list:
# extract_first()第一个
name = div.xpath(".//div[@class='meta']/h1/a/text()").extract_first()
kind = div.xpath('.//div[@class="otherinfo"]//text()').extract()
# 将kind列表转化成字符串
kind = " ".join(kind)
url = div.xpath('.//div[@class="meta"]/h1/a/@href').extract_first()
# href="//www.55xia.com/movie/638284.html
url = 'https:'+url
# 创建items对象
item = MovieproItem()
item['name'] = name
item['kind'] = kind
item['url'] = url
print('创建items对象') # 需要对url发起请求,获取页面数据,进行指定数据解析
# 问题:如何将剩下的电影详情数据存储到item对象(meta)
# 需要对url发起请求,获取页面数据,进行指定数据解析
# meta参数只可以赋值一个字典(将item对象先封装到字典)
yield scrapy.Request(url=url, callback=self.parseBySecondPage, meta={'item': item})
movie.py
items.py
import scrapy class MovieproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
kind = scrapy.Field()
director = scrapy.Field()
language = scrapy.Field()
longTime = scrapy.Field()
url = scrapy.Field()
管道pipelines.py
class MovieproPipeline(object):
fp = None def open_spider(self, spider):
self.fp = open('movie.txt', 'w', encoding='utf-8') def process_item(self, item, spider):
print('------process_item-------')
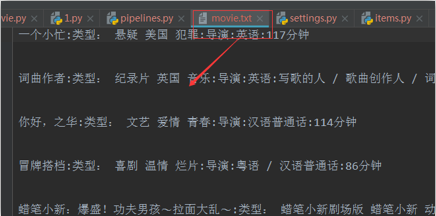
detail = item['name'] + ':' + item['kind'] + ':' + item['director'] + ':' + item['language'] + ':' + item[
'longTime'] + '\n\n\n'
self.fp.write(detail)
return item def close_spider(self, spider):
self.fp.close()
爬虫--Scrapy-参数等级和请求传参的更多相关文章
- Scrapy日志等级以及请求传参
日志等级 请求传参 提高scrapy的爬取效率 日志等级 - 日志信息: 使用命令:scrapy crawl 爬虫文件 运行程序时,在终端输出的就是日志信息: - 日志信息的种类: - ERROR ...
- scrapy框架的日志等级和请求传参, 优化效率
目录 scrapy框架的日志等级和请求传参, 优化效率 Scrapy的日志等级 请求传参 如何提高scripy的爬取效率 scrapy框架的日志等级和请求传参, 优化效率 Scrapy的日志等级 在使 ...
- 爬虫开发10.scrapy框架之日志等级和请求传参
今日概要 日志等级 请求传参 今日详情 一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息. - 日志 ...
- 13.scrapy框架的日志等级和请求传参
今日概要 日志等级 请求传参 如何提高scrapy的爬取效率 今日详情 一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是s ...
- scrapy框架的日志等级和请求传参
日志等级 请求传参 如何提高scrapy的爬取效率 一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息 ...
- scrapy框架之日志等级和请求传参-cookie-代理
一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息. - 日志信息的种类: ERROR : 一般错误 ...
- Scrapy的日志等级和请求传参
日志等级 日志信息: 使用命令:scrapy crawl 爬虫文件 运行程序时,在终端输出的就是日志信息: 日志信息的种类: ERROR:一般错误: WARNING:警告: INFO:一般的信息: ...
- scrapy框架post请求发送,五大核心组件,日志等级,请求传参
一.post请求发送 - 问题:爬虫文件的代码中,我们从来没有手动的对start_urls列表中存储的起始url进行过请求的发送,但是起始url的确是进行了请求的发送,那这是如何实现的呢? - 解答: ...
- Scrapy框架之日志等级和请求传参
一.Scrapy的日志等级 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息. 1.日志等级(信息种类) ERROR:错误 WARN ...
随机推荐
- 1126 Eulerian Path (25 分)
1126 Eulerian Path (25 分) In graph theory, an Eulerian path is a path in a graph which visits every ...
- Could not determine own NN ID in namespace 'mycluster'
执行hdfs namenode -bootstrapStandby的时候报错如下 19/03/24 18:00:48 ERROR namenode.NameNode: Failed to start ...
- HTTP RFC解析
HTTP协议(HyperText Transfer Protocol,超文本传输协议)HTTP是一个属于应用层的面向对象的协议,由于其简捷.快速的方式,适用于分布式超媒体信息系统.它于1990年提出, ...
- layui之初始化加分页重复请求问题解决
layui框架中的page困扰我很久,一个页面初始化后并且分页,导致初始化渲染请求一次,分页再请求了一次,一个接口就重复请求了2次,通过不停的分析和测试,最终解决了这个问题. 基于JQ的ajax二次封 ...
- adversarial example研究
Paper: Practical Black-Box Attacks against Machine Learning 一.介绍 概况:Ian Goodfellow大神研究如何在不知道model内部结 ...
- 批处理taskkill运行结束不掉程序以及停留问题
我原来就一句代码 TASKKILL /F /IM QQ.exe 保存为taskkill.bat,结果运行起来一直显示,但是没有结束掉进程,百度搜索才知道taskkill为系统关键字,不能命名为task ...
- c#语言---数据类型
整型 值类型 名称 CTS类型 说明 ...
- Java 1-Java 基础语法
一个Java程序可以认为是一系列对象的集合,而这些对象通过调用彼此的方法来协同工作.下面简要介绍下类.对象.方法和实例变量的概念. 对象:对象是类的一个实例,有状态和行为.例如,一条狗是一个对象,它的 ...
- 对KVM虚拟机进行cpu pinning配置的方法
这篇文章主要介绍了对KVM虚拟机进行cpu pinning配置的方法,通过文中的各种virsh命令可进行操作,需要的朋友可以参考下 首先需求了解基本的信息 1 宿主机CPU特性查看 使用virsh n ...
- Solr查询参数sort(排序)
摘要: Solr查询每一次返回的数据都有一定的顺序,特定顺序的结果对于业务来说可能非常重要. 不指定排序 一般我们不指定排序规则,这样的结果能满足大部分需求,默认是用文档的得分作为排序标准.相当于加上 ...