爬虫--Scrapy-参数等级和请求传参
日志等级
日志等级(种类):
ERROR:错误
WARNING:警告
INFO:一般信息
DEBUG:调试信息(默认)
指定输入某一中日志信息:
settings:LOG_LEVEL = ‘ERROR’
将日志信息存储到制定文件中,而并非显示在终端里:
settings:LOG_FILE = ‘log.txt’ 请求传参:爬取的数据值不在同一个页面中。
需求:将id97电影网站中电影详情数据进行爬取(名称,类型,导演,语言,片长)
如何让终端显示错误信息
在settings.py中配置
# 指定终端输入指定种类日志信息
LOG_LEVEL = 'ERROR'
# 存储到文件
LOG_FILE = 'log.txt'
请求传参
请求传参:爬取的数据值不在同一个页面中。
(id97电影网站) 在电影网站中电影详情数据进行爬取(名称,类型,导演,语言,片长)
创建moviePro工程
scrapy startproject moviePro
cd moviePro
scrapy genspider movie www.id97.com

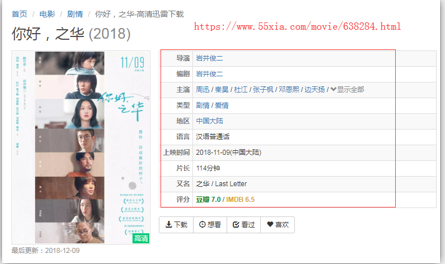
电影名称和类型在一页
电影的其他详情在另外一页
爬虫文件movie.py
import scrapy
from moviePro.items import MovieproItem class MovieSpider(scrapy.Spider):
name = 'movie'
#allowed_domains = ['www.id97.com']
start_urls = ['https://www.55xia.com/movie']
print(' start_urls') # 用于解析二级页面数据 def parseBySecondPage(self,response):
# 直接复制网页端的xpath
director = response.xpath('/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[1]/td[1]/span/text()').extract_first()
language = response.xpath('/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[6]/td[2]/text()').extract_first()
longTime = response.xpath('/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[8]/td[2]/text()').extract_first()
# 取出Request方法的meta参数传递过来的字典(response.meta)
item = response.meta['item']
item['director'] = director
item['language'] = language
item['longTime'] = longTime
# 将item提交给管道
print('将item提交给管道')
yield item def parse(self, response):
# 需求:将id97电影网站中电影详情数据进行爬取(名称,类型,导演,语言,片长)
div_list = response.xpath('/html/body/div[1]/div[1]/div[2]/div')
for div in div_list:
# extract_first()第一个
name = div.xpath(".//div[@class='meta']/h1/a/text()").extract_first()
kind = div.xpath('.//div[@class="otherinfo"]//text()').extract()
# 将kind列表转化成字符串
kind = " ".join(kind)
url = div.xpath('.//div[@class="meta"]/h1/a/@href').extract_first()
# href="//www.55xia.com/movie/638284.html
url = 'https:'+url
# 创建items对象
item = MovieproItem()
item['name'] = name
item['kind'] = kind
item['url'] = url
print('创建items对象') # 需要对url发起请求,获取页面数据,进行指定数据解析
# 问题:如何将剩下的电影详情数据存储到item对象(meta)
# 需要对url发起请求,获取页面数据,进行指定数据解析
# meta参数只可以赋值一个字典(将item对象先封装到字典)
yield scrapy.Request(url=url, callback=self.parseBySecondPage, meta={'item': item})
movie.py
items.py
import scrapy class MovieproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
kind = scrapy.Field()
director = scrapy.Field()
language = scrapy.Field()
longTime = scrapy.Field()
url = scrapy.Field()
管道pipelines.py
class MovieproPipeline(object):
fp = None def open_spider(self, spider):
self.fp = open('movie.txt', 'w', encoding='utf-8') def process_item(self, item, spider):
print('------process_item-------')
detail = item['name'] + ':' + item['kind'] + ':' + item['director'] + ':' + item['language'] + ':' + item[
'longTime'] + '\n\n\n'
self.fp.write(detail)
return item def close_spider(self, spider):
self.fp.close()
爬虫--Scrapy-参数等级和请求传参的更多相关文章
- Scrapy日志等级以及请求传参
日志等级 请求传参 提高scrapy的爬取效率 日志等级 - 日志信息: 使用命令:scrapy crawl 爬虫文件 运行程序时,在终端输出的就是日志信息: - 日志信息的种类: - ERROR ...
- scrapy框架的日志等级和请求传参, 优化效率
目录 scrapy框架的日志等级和请求传参, 优化效率 Scrapy的日志等级 请求传参 如何提高scripy的爬取效率 scrapy框架的日志等级和请求传参, 优化效率 Scrapy的日志等级 在使 ...
- 爬虫开发10.scrapy框架之日志等级和请求传参
今日概要 日志等级 请求传参 今日详情 一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息. - 日志 ...
- 13.scrapy框架的日志等级和请求传参
今日概要 日志等级 请求传参 如何提高scrapy的爬取效率 今日详情 一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是s ...
- scrapy框架的日志等级和请求传参
日志等级 请求传参 如何提高scrapy的爬取效率 一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息 ...
- scrapy框架之日志等级和请求传参-cookie-代理
一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息. - 日志信息的种类: ERROR : 一般错误 ...
- Scrapy的日志等级和请求传参
日志等级 日志信息: 使用命令:scrapy crawl 爬虫文件 运行程序时,在终端输出的就是日志信息: 日志信息的种类: ERROR:一般错误: WARNING:警告: INFO:一般的信息: ...
- scrapy框架post请求发送,五大核心组件,日志等级,请求传参
一.post请求发送 - 问题:爬虫文件的代码中,我们从来没有手动的对start_urls列表中存储的起始url进行过请求的发送,但是起始url的确是进行了请求的发送,那这是如何实现的呢? - 解答: ...
- Scrapy框架之日志等级和请求传参
一.Scrapy的日志等级 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息. 1.日志等级(信息种类) ERROR:错误 WARN ...
随机推荐
- 新建本地仓库,同步远程仓场景,出现git branch --set-upstream-to=origin/master master 解决方法
1.本地创建一个本地仓库 2.关联远程端:git remote add origin git@github.com:用户名/远程库名.git3.同步远程仓库到本地git pull这个时候会报错If y ...
- 问题 B: 【例9.3】求最长不下降序列(基础dp)
问题 B: [例9.3]求最长不下降序列 时间限制: 1 Sec 内存限制: 128 MB提交: 318 解决: 118[提交][状态][讨论版][命题人:quanxing] 题目描述 设有由n( ...
- Java-Runoob-高级教程-实例-时间处理:01. Java 实例 - 格式化时间(SimpleDateFormat)
ylbtech-Java-Runoob-高级教程-实例-时间处理:01. Java 实例 - 格式化时间(SimpleDateFormat) 1.返回顶部 1. Java 实例 - 格式化时间(Sim ...
- 查看设备uuid的命令-blkid
查看设备uuid的命令-blkid 在关联/etc/fstab的时候可以使用 [root@mapper ~]# blkid /dev/sda1: UUID="285510be-b19 ...
- HDOJ 2001 ASCII码排序
#include<set> #include<iostream> using namespace std; int main() { char a, b, c; while ( ...
- 进程优先和ACL
linux上进程有5种状态: 1. 运行(正在运行或在运行队列中等待) 2. 中断(休眠中, 受阻, 在等待某个条件的形成或接受到信号) 3. 不可中断(收到信号不唤醒和不可运行, 进程必须等待直到有 ...
- Mysql 之权限体系
1,MySQL权限体系 MySQL 的权限体系大致分为5个层级: 全局层级: 全局权限适用于一个给定服务器中的所有数据库.这些权限存储在mysql.user表中.GRANT ALL ON .和REVO ...
- SQLServer: 解决“错误15023:当前数据库中已存在用户或角色”
首先介绍一下sql server中“登录”与“用户”的区别,“登录”用于用户身份验证,而数据库“用户”帐户用于数据库访问和权限验证.登录通过安全识别符 (SID) 与用户关联.将数据库恢复到其他服务器 ...
- vue属性
1. 图片地址: data:{ url:"https://www.baidu.com/img/bd_logo1.png"}, <img v-bind:src="ur ...
- Google C++命令规范
最近发现自己在开发程序的过程中,经常会将好几种命名规范进行混用,这样使得程序的可读性下降,于是乎依然决定学习并使用Google的命令规范,并且坚持使用. copy from https://www.c ...