python随笔 join 字典,列表的清空 set集合 以及深浅拷贝(重点..难点)
一,字符串和列表的转换
1.str中的 join 方法: 把列表转换成字符串
# 将列表转换成字符串. 每个元素之间用_连接
s = '**'.join(['李启政',' 郑强' , '孙福来']) print(s) #s = ["李启政"**"郑强"**"孙福来"]
ss = "李启政**郑强**孙福来" ss.split("**") print(ss)
字符串转化成列表: split()
把列表转化成字符串: join()
s = "_",join('马化腾')
print(s)
# s = ('马_化_藤')
join (可迭代对象)
2.列表和字典在循环的过程中不能直接删除,与要把要删除的内容记录在新列表中,然后循环新列表,删除字典或者列表.
lst = ["紫云", "大云", "玉溪", "紫钻","a","b"]
lst.clear() new_lst = [] # 准备要删除的信息
for el in lst: # 有一个变量来记录当前循环的位置
new_lst.append(el) # 循环新列表, 删除老列表
for el in new_lst:
lst.remove(el)
#
# # 删除的时候, 发现. 剩余了一些内容. 原因是内部的索引在改变.
# # 需要把要删除的内容记录下来. 然后循环这个记录. 删除原来的列表
#
# print(lst)
# print(new_lst)
** 列表 清空及删除
例 : lst = ["张国荣", '张铁林', '张国立', "张曼玉", "汪峰"]
(1)删除姓张的
zhangs = []
for el in lst:
if el.startswith("张"):
zhangs.append(el)
for el in zhangs:
lst.remove(el)
print(lst)
(2)记录姓张的
zhangs = []
for el in lst:
if el.startswith("张"):
zhangs.append(el)
for el in zhangs:
lst.remove(el)
print(zhangs)
** 字典 清空及删除
例 : dic = {"提莫":"冯提莫", "发姐":"陈一发儿", "55开":"卢本伟"}
dic = {"提莫":"冯提莫", "发姐":"陈一发儿", "55开":"卢本伟"}
lst = []
for k in dic:
lst.append(k)
for el in lst:
dic.pop(el)
print(dic)
综上,列表和字典都不能在循环的时候进行删除,字典在循环的时候不能改变大小长度.
3.fromkeys()
(1)返回新字典,对原字典没有影响
(2)后面的value,是多个key共享的一个value.
例: dic = {"apple":"苹果", "banana":"香蕉"}
dic = {"apple":"苹果", "banana":"香蕉"}
# 返回新字典. 和原来的没关系
ret = dic.fromkeys("orange", "橘子") # 直接用字典去访问fromkeys不会对字典产生影响
ret = dict.fromkeys("abc",["哈哈","呵呵", "吼吼"]) # fromkeys直接使用类名进行访问
print(ret)
a = ["哈哈","呵呵", "吼吼"]
ret = dict.fromkeys("abc", a) # fromkeys直接使用类名进行访问
a.append("嘻嘻")
print(ret)
二.set集合
特点: 无序,不重复,元素必须可哈希(不可变).
作用: 去重复
本身是可变类型,有增删改查操作.
frozenset()冻结的集合, 不可改变,可哈希的.
set 去重复
例: s = {"周杰伦", "的老婆","叫昆凌", (1,2,3), "周杰伦"}
s = {"周杰伦", "的老婆","叫昆凌", (1,2,3), "周杰伦"}
s = set(s)
print(s) # s = {"周杰伦", "的老婆","叫昆凌", (1,2,3)}
set 把列表转换成集合. 进行去重复 ,再把集合转换回列表.
例: lst = [11,5,4,1,2,5,4,1,25,2,1,4,5,5]
lst = [11,5,4,1,2,5,4,1,25,2,1,4,5,5] s = set(lst) # 把列表转换成集合. 进行去重复 lst = list(s) # 把集合转换回列表. print(lst) #lst = [1,2,4,5,11,25]
集合本身是可变的数据类型, 不可哈希, 有增删改查操作,
例: s = {"刘嘉玲", '关之琳', "王祖贤"}
s = {"刘嘉玲", '关之琳', "王祖贤"}
s.update("麻花藤") # 迭代更新
print(s) #{'麻', '藤', '刘嘉玲', '关之琳', '花', '王祖贤'}
集合中的元素必须是可哈希的 .不重复的. 可以去重.
集合的增删改查
1,增: add : 重复的内容不会被添加到set集合中 和 update : 迭代更新
s = {"刘嘉玲", '关之琳', "王祖贤"}
s.add("郑裕玲")
print(s)
s.add("郑裕玲") # 重复的内容不会被添加到set集合中
print(s)
s = {"刘嘉玲", '关之琳', "王祖贤"}
s.update("麻花藤") # 迭代更新
print(s)
s.update(["张曼玉", "李若彤","李若彤"])
print(s)
2.删: pop() : 随机删除(随机弹出一个) remove() :直接删除元素 clear():清空set集合.需要注意的是set集合如果是空的. 打印出来是set() 因为要和 dict区分的.
s = {"刘嘉玲", '关之琳', "王祖贤","张曼玉", "李若彤"}
item = s.pop() # 随机弹出一个.
print(s)
print(item)
s.remove("关之琳") # 直接删除元素
# s.remove("马虎疼") # 不存在这个元素. 删除会报错
print(s)
s.clear() # 清空set集合.需要注意的是set集合如果是空的. 打印出来是set() 因为要和
dict区分的.
print(s) # set()
3.改:set集合中的数据没有索引. 也没有办法去定位一个元素. 所以没有办法进⾏直接修改. 我们可以采取先删除后添加的方式来完成修改操作
s = {"刘嘉玲", '关之琳', "王祖贤","张曼玉", "李若彤"}
# 把刘嘉玲改成赵本山
s.remove("刘嘉玲")
s.add("赵本山")
print(s)
4.查: set是一个可迭代对象. 所以可以进行for循环
for el in s: print(el)
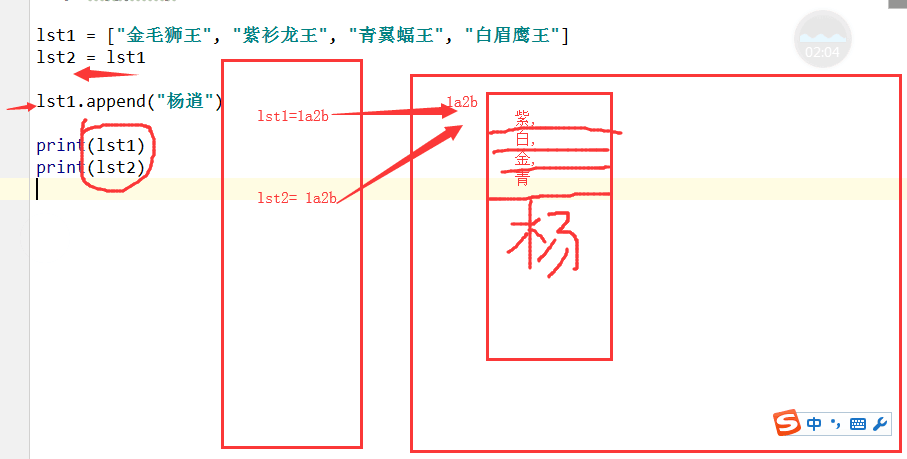
三.深浅拷贝(难点)
1. 赋值,没有创建新对象,共用一个对象
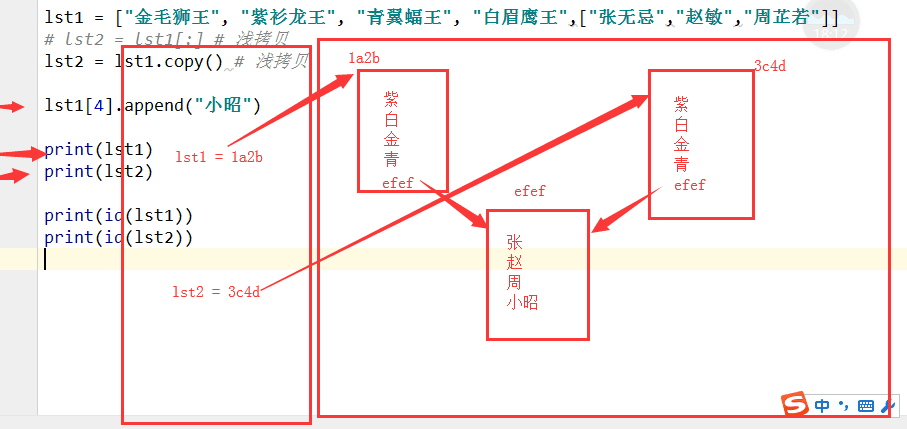
2.浅拷贝,拷贝第一层内容, [ : ]或 copy( )
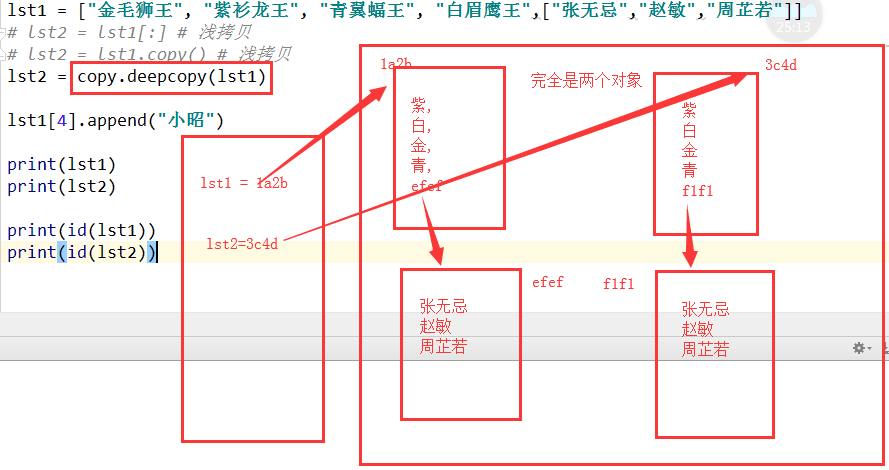
3.深拷贝,拷贝所有内容,包括内部的所有.
例: lst1 = ["金毛狮王", "紫衫龙王", "青翼蝠王", "白眉鹰王",["张无忌","赵敏","周芷若"]]
浅拷贝
lst1 = ["金毛狮王", "紫衫龙王", "青翼蝠王", "白眉鹰王",["张无忌","赵敏","周芷若"]]
lst2 = lst1[:] # 浅拷贝
lst2 = lst1.copy() # 浅拷贝 lst1[4].append("小昭") print(lst1)
print(lst2) print(id(lst1[4]))
print(id(lst2[4]))
#['金毛狮王', '紫衫龙王', '青翼蝠王', '白眉鹰王', ['张无忌', '赵敏', '周芷若', '小昭']]
['金毛狮王', '紫衫龙王', '青翼蝠王', '白眉鹰王', ['张无忌', '赵敏', '周芷若', '小昭']]
地址一样 40206664
40206664
深拷贝
lst1 = ["金毛狮王", "紫衫龙王", "青翼蝠王", "白眉鹰王",["张无忌","赵敏","周芷若"]]
lst1[4].append("小昭")
lst2 = copy.deepcopy(lst1) # 深拷贝
print(lst1) print(lst2) print(id(lst1[4])) print(id(lst2[4]))
#['金毛狮王', '紫衫龙王', '青翼蝠王', '白眉鹰王', ['张无忌', '赵敏', '周芷若', '小昭']]
['金毛狮王', '紫衫龙王', '青翼蝠王', '白眉鹰王', ['张无忌', '赵敏', '周芷若', '小昭']]
地址不同 42238280
42239688

python随笔 join 字典,列表的清空 set集合 以及深浅拷贝(重点..难点)的更多相关文章
- python 补充:join() , 基本数据类型的增删改查以及深浅拷贝
# join() join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串. li = ["李李嘉诚", "麻花藤", "黄海海峰&q ...
- Python 入门之代码块、小数据池 与 深浅拷贝
Python 入门之代码块.小数据池 与 深浅拷贝 1.代码块 (1)一个py文件,一个函数,一个模块,终端中的每一行都是代码块 (代码块是防止我们频繁的开空间降低效率设计的,当我们定一个变量需要开辟 ...
- python中 字符 字典 列表之间的转换
1 字典 转 字符 定义一个字典:dict = {'name': 'python', 'age': 7}字典转字符 可以使用str强制转换 如: str(dict) 此时dict的类型就是字符型了 2 ...
- python的推导式 —— 列表推导式、集合和字典推导式
python的推导式是用于快速处理数据的方法. 主要有:列表推导式.集合推导式和字典推导式 import time import numpy as np 列表推导式: 1. 速度快 t1 = time ...
- python之set集合、深浅拷贝
一.基本数据类型补充 1,关于int和str在之前的学习中已经介绍了80%以上了,现在再补充一个字符串的基本操作: li = ['李嘉诚','何炅','海峰','刘嘉玲'] s = "_&q ...
- str中的join方法,fromkeys(),set集合,深浅拷贝(重点)
一丶对之前的知识点进行补充 1.str中的join方法.把列表转换成字符串 # 将列表转换成字符串,每个元素之间用_拼接 s = "_".join(["天",& ...
- python之set集合及深浅拷贝
一.知识点补充 1.1字符串的基本操作 li =["李李嘉诚", "麻花藤", "⻩黄海海峰", "刘嘉玲"] s = ...
- 从入门到自闭之Python集合,深浅拷贝(大坑)
小数据池 int: -5~256 str: 字母,数字长度任意符合驻留机制 字符串进行乘法时总长度不能超过20 特殊符号进行乘法时只能乘以0 代码块: 一个py文件,一个函数,一个模块,终端中的每一行 ...
- python day 07-数据类型补充,集合,深浅拷贝
一.基础数据类型补充 1.列表转字符串 a='A'.join(['c','c','s']) print(a) 2.循环删除列表中的每⼀一个元素 lst=['asdf','dftgst','zsdrfs ...
随机推荐
- oracle 12c ins-30131 执行安装程序验证所需的初始设置失败
- ln: 创建符号链接 "/usr/bin/java": 文件已存在
执行下述命令创建软链接 #ln -s $JAVA_HOME/bin/java /usr/bin/java 出现下述错误提示: ln: 创建符号链接 "/usr/bin/java": ...
- shell中的逻辑判断while
w|head -1|awk -F'load average: ' '{print $2}'|cut -d. -f1 #!/bin/bash while true do load=`w|head -1| ...
- centos7.5单机yum安装kubernetes
1.系统配置 centos7.5 docker 1.13.1 centos7下安装docker 2.关闭防火墙,selinux,swapoff systemctl disable firewalld ...
- linux 文件目录类的指令 包含查找
pwd :显示当前目录的绝对路径 ls : 显示当前目录 -a 显示所有文件 包括隐藏文件 -l 以列表的方式进行显示 cd 切换目录 cd ~ :返回家目录 cd .. :返回上一级的目录 m ...
- Windows环境安装Django步骤
前提:已经安装Python 1.先从Django官网下载压缩包:https://www.djangoproject.com/download/ 2.解压Django,如我解压到 D:\Python\D ...
- 解决git中文乱码问题
三条命令fix乱码问题: git config --global gui.encoding utf-8 git config --global i18n.commitencoding utf-8 gi ...
- UNITY 优化之带Animator的Go.SetActive耗时问题,在手机上,这个问题似乎并不存在,因为优化了后手机上运行帧率并未明显提升
UNITY 优化之带Animator的Go.SetActive耗时问题,在手机上,这个问题似乎并不存在,因为优化了后手机上运行帧率并未明显提升 经确认,这个问题在手机上依然存在,不过占的比例非常小.因 ...
- Jmeter的安装与使用
安装Jmeter之前需要先配置Java环境 当配置完Jmeter运行的环境之后,就可以开始安装Jmeter了. 为什么既要告诉各位"在Linux系统内安装Jmeter",又要告诉各位"在Windo ...
- 正则表达式(TypeScript, JavaScript)
课题 使用正则表达式匹配字符串 使用正则表达式 "\d{3}-(\d{4})-\d{2}" 匹配字符串 "123-4567-89" 返回匹配结果:'" ...