Zookeeper集群搭建以及python操作zk
一、Zookeeper原理简介
ZooKeeper是一个开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。
Zookeeper设计目的
- 最终一致性:client不论连接到那个Server,展示给它的都是同一个视图。
- 可靠性:具有简单、健壮、良好的性能、如果消息m被到一台服务器接收,那么消息m将被所有服务器接收。
- 实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
- 等待无关(wait-free):慢的或者失效的client不得干预快速的client的请求,使得每个client都能有效的等待。
- 原子性:更新只能成功或者失败,没有中间状态。
- 顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
Zookeeper工作原理
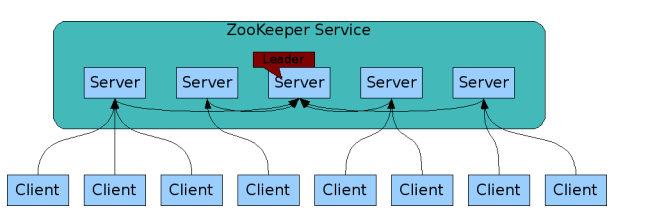
1、在zookeeper的集群中,各个节点共有下面3种角色和4种状态:
角色:leader,follower,observer
状态:leading,following,observing,looking
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议(ZooKeeper Atomic Broadcast protocol)。Zab协议有两种模式,它们分别是恢复模式(Recovery选主)和广播模式(Broadcast同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
每个Server在工作过程中有4种状态:
LOOKING:当前Server不知道leader是谁,正在搜寻。
LEADING:当前Server即为选举出来的leader。
FOLLOWING:leader已经选举出来,当前Server与之同步。
OBSERVING:observer的行为在大多数情况下与follower完全一致,但是他们不参加选举和投票,而仅仅接受(observing)选举和投票的结果。
Zookeeper集群节点
- Zookeeper节点部署越多,服务的可靠性越高,建议部署奇数个节点,因为zookeeper集群是以宕机个数过半才会让整个集群宕机的。
- 需要给每个zookeeper 1G左右的内存,如果可能的话,最好有独立的磁盘,因为独立磁盘可以确保zookeeper是高性能的。如果你的集群负载很重,不要把zookeeper和RegionServer运行在同一台机器上面,就像DataNodes和TaskTrackers一样。
实验环境
| 操作系统 | docker镜像 | docker ip | zookeeper版本 |
| ubuntu-16.04.5-server-amd64 | ubuntu:16.04 | 172.168.0.2 | 3.4.13 |
| ubuntu-16.04.5-server-amd64 | ubuntu:16.04 | 172.168.0.2 | 3.4.13 |
| ubuntu-16.04.5-server-amd64 | ubuntu:16.04 | 172.168.0.2 | 3.4.13 |
由于机器有限,本文在一台服务器上面,开启了3个docker容器。
使用网桥连接3个docker容器。这样,就可以模拟3台服务器了!
创建网桥
bridge有以下好处:
好的隔离性和互操作性:连到同一自定义的bridge的各个容器默认相互之间曝露所有端口,并且不对外部曝露
自动提供容器之间的DNS解析服务:连到同一自定义的bridge的各个容器不用做特殊DNS配置,可直接通过hostname访问
运行中容器联网配置:可对运行中的容器配置自定义或取消配置自定义bridge
bridge之间相互独立:用户可创建N多个bridge,且连接于不同的bridge之上的容器相互独立
创建自定义bridge,名字叫br1
docker network create --driver=bridge --subnet=172.168.0.0/ br1
语法解释:
--driver=bridge 表示使用桥接模式
--subnet 表示网络地址
为容器配置静态IP,可以使用以下命令
docker run -it --network my-net --ip 172.18.0.250 imageID bash
Zookeeper核心要点
1. Zookeeper节点必须是奇数
2. 修改zoo.cfg
末尾增加3行参数。表示有3个zk节点!
server.X=A:B:C
server.X=A:B:C
server.X=A:B:C
官方解释
The entries of the form server.X list the servers that make up the ZooKeeper service. When the server starts up, it knows which server it is by looking for the file myid in the data directory. That file has the contains the server number, in ASCII. Finally, note the two port numbers after each server name: "" and "". Peers use the former port to connect to other peers. Such a connection is necessary so that peers can communicate, for example, to agree upon the order of updates. More specifically, a ZooKeeper server uses this port to connect followers to the leader. When a new leader arises, a follower opens a TCP connection to the leader using this port. Because the default leader election also uses TCP, we currently require another port for leader election. This is the second port in the server entry.
蹩脚翻译
表单server.X的条目列出构成ZooKeeper服务的服务器。当服务器启动时,它通过查找数据目录中的文件myid来知道它是哪个服务器 。该文件包含服务器编号,以ASCII格式显示。 最后,请注意每个服务器名称后面的两个端口号:“”和“”。对等体使用前端口连接到其他对等体。这样的连接是必要的,使得对等体可以进行通信,例如,以商定更新的顺序。更具体地说,一个ZooKeeper服务器使用这个端口来连接追随者到领导者。当新的领导者出现时,追随者使用此端口打开与领导者的TCP连接。因为默认领导选举也使用TCP,所以我们目前需要另外一个端口进行领导选举。这是服务器条目中的第二个端口。
大概意思
server.X=A:B:C X-代表服务器编号 A-代表ip B和C-代表端口,这个端口用来系统之间通信
3. 创建ServerID标识
除了修改zoo.cfg配置文件外,zookeeper集群模式下还要配置一个myid文件,这个文件需要放在dataDir目录下。
这个文件里面有一个数据就是A的值(该A就是zoo.cfg文件中server.A=B:C:D中的A),在zoo.cfg文件中配置的dataDir路径中创建myid文件
二、Zookeeper安装
Zookeeper运行需要java环境,需要安装jdk,注:每台服务器上面都需要安装zookeeper、jdk。
基于docker安装
新建空目录
mkdir /opt/zookeeper_cluster
dockerfile
FROM ubuntu:16.04
# 修改更新源为阿里云
ADD sources.list /etc/apt/sources.list
ADD zookeeper-3.4..tar.gz /
ADD zoo.cfg /
# 安装jdk
RUN apt-get update && apt-get install -y openjdk--jdk --allow-unauthenticated && apt-get clean all && \
cd /zookeeper-3.4. && \
mkdir data log && \
mv /zoo.cfg conf EXPOSE
# 添加启动脚本
ADD run.sh .
RUN chmod run.sh
ENTRYPOINT [ "/run.sh"]
run.sh
#!/bin/bash
if [ -z "${SERVER_ID}" ];then
echo "SERVER_ID 变量缺失"
exit
fi
if [ -z "${ZOOKEEPER_CONNECT}" ];then
echo "ZOOKEEPER_CONNECT环境变量缺失"
echo "比如: 192.168.1.1,192.168.1.2,192.168.1.3"
exit
fi
# 配置集群
# 写入server.X对应的X
echo $SERVER_ID > /zookeeper-3.4./data/myid
# 写入文件zoo.cfg
id= # 初始值
hosts_array=(${ZOOKEEPER_CONNECT//,/ }) # 以逗号来切割,转换为数组
for ip in ${hosts_array[@]};do
((id++)) # id自增1
echo "server.$id=$ip:2888:3888" >> /zookeeper-3.4./conf/zoo.cfg
done
# 启动zookeeper
cd /zookeeper-3.4./
bin/zkServer.sh start
tail -f /zookeeper-3.4./conf/zoo.cfg
注意:此脚本需要2个变量,否则会直接退出。它会在zoo.cfg写入3行内容!
除了修改zoo.cfg配置文件外,zookeeper集群模式下还要配置一个myid文件,这个文件需要放在dataDir目录下
/zookeeper-3.4.13/data/myid 这个文件的数值,待会由docker启动时,传入进去。
sources.list
deb http://mirrors.aliyun.com/ubuntu/ xenial main
deb-src http://mirrors.aliyun.com/ubuntu/ xenial main deb http://mirrors.aliyun.com/ubuntu/ xenial-updates main
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates main deb http://mirrors.aliyun.com/ubuntu/ xenial universe
deb-src http://mirrors.aliyun.com/ubuntu/ xenial universe
deb http://mirrors.aliyun.com/ubuntu/ xenial-updates universe
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates universe deb http://mirrors.aliyun.com/ubuntu/ xenial-security main
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security main
deb http://mirrors.aliyun.com/ubuntu/ xenial-security universe
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security universe
zoo.cfg
tickTime=
initLimit=10
syncLimit=5
dataDir=/zookeeper-3.4./data
dataLogDir=/zookeeper-3.4./log
clientPort=
initLimit 这个配置项是用来配置zookeeper接受客户端(这里所说的客户端不是用户连接zookeeper服务器的客户端,而是zookeeper服务器集群中连接到leader的follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。
syncLimit 这个配置项标识leader与follower之间发送消息,请求和应答时间长度,最长不能超过多少个tickTime的时间长度,总的时间长度就是5*2000=10秒。
注意:上面的2行红色部分参数,一定要加。否则会导致启动zookeeper失败,因为启动时,它会尝试连接server.X=A:B:C。有多少个,都会连接。
如果连接失败数大于集群总数一半,会认为集群不可用。
那么配置这2个参数之后,就会有时间缓解一下。因为我不是闪电侠,我不能在一瞬间同时启动3个zookeeper。而且你还得确保,zookeeper检查其他节点时,其他节点运行是正常的!
因此,只要你在10秒内,启动3个zookeeper,就可以了!
此时,目录结构如下:
./
├── dockerfile
├── run.sh
├── sources.list
├── zoo.cfg
└── zookeeper-3.4..tar.gz
生成镜像
docker build -t zookeeper_cluster /opt/zookeeper_cluster
启动docker
在启动之前,请确保已经创建了网桥br1
启动第一个docker
docker run -it -e SERVER_ID=1 -e ZOOKEEPER_CONNECT=172.168.0.2,172.168.0.3,172.168.0.4 -p : --network br1 --ip=172.168.0.2 zookeeper_cluster
启动第二个docker
docker run -it -e SERVER_ID=2 -e ZOOKEEPER_CONNECT=172.168.0.2,172.168.0.3,172.168.0.4 -p : --network br1 --ip=172.168.0.3 zookeeper_cluster
启动第二个docker
docker run -it -e SERVER_ID=3 -e ZOOKEEPER_CONNECT=172.168.0.2,172.168.0.3,172.168.0.4 -p : --network br1 --ip=172.168.0.4 zookeeper_cluster
注意红色部分,是需要修改的,其他的参数都是一样的!
三、Zookeeper集群查看
查看每个节点状态
先来查看一下docker进程
root@jqb-node128:/opt/zookeeper_cluster# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
217e012c9566 3f3a8090dcb6 "/run.sh" hours ago Up hours 0.0.0.0:->/tcp gallant_golick
3b4861d2fef9 3f3a8090dcb6 "/run.sh" hours ago Up hours 0.0.0.0:->/tcp jovial_murdock
ed91c1f973d2 3f3a8090dcb6 "/run.sh" hours ago Up hours 0.0.0.0:->/tcp dazzling_hamilton
查看每个节点状态,使用命令 zkServer.sh status 查看
root@jqb-node128:~# docker exec -it 217e012c9566 /zookeeper-3.4.13/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /zookeeper-3.4./bin/../conf/zoo.cfg
Mode: follower
root@jqb-node128:~# docker exec -it 3b4861d2fef9 /zookeeper-3.4.13/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /zookeeper-3.4./bin/../conf/zoo.cfg
Mode: leader
root@jqb-node128:~# docker exec -it ed91c1f973d2 /zookeeper-3.4.13/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /zookeeper-3.4./bin/../conf/zoo.cfg
Mode: follower
可以发现,第二台,也就是id为3b4861d2fef9 的容器,就是leader模式。其它容器是follow模式
四、Zookeeper集群连接
Zookeeper集群搭建完毕之后,可以通过客户端脚本连接到zookeeper集群上面,对客户端来说,zookeeper集群是一个整体,连接到zookeeper集群实际上感觉在独享整个集群的服务。
指定第一台节点
docker exec -it 217e012c9566 /zookeeper-3.4./bin/zkCli.sh -server 172.168.0.2:
使用ls / 查看根节点,默认只有一个zookeeper节点。
WatchedEvent state:SyncConnected type:None path:null
[zk: 172.168.0.2:(CONNECTED) ] ls /
[zookeeper]
[zk: 172.168.0.2:(CONNECTED) ]
五、使用python操作zookeeper
kazoo 介绍
zookeeper的开发接口以前主要以java和c为主,随着python项目越来越多的使用zookeeper作为分布式集群实现,python的zookeeper接口也出现了很多,现在主流的纯python的zookeeper接口是kazoo。因此如何使用kazoo开发基于python的分布式程序是必须掌握的。
安装kazoo
pip3 install kazoo
基本操作
from kazoo.client import KazooClient
zk = KazooClient(hosts='192.168.91.128:2181') #如果是本地那就写127.0.0.
zk.start() #与zookeeper连接
zk.stop() #与zookeeper断开
创建节点
from kazoo.client import KazooClient
zk = KazooClient(hosts='192.168.91.128:2181') #如果是本地那就写127.0.0.
zk.start() #与zookeeper连接
#makepath=True是递归创建,如果不加上中间那一段,就是建立一个空的节点
zk.create('/abc/JQK/XYZ/0001',b'this is my house',makepath=True)
node = zk.get_children('/') # 查看根节点有多少个子节点
print(node)
zk.stop() #与zookeeper断开
执行输出:
['abc', 'zookeeper']
注意:空节点的值不能用set修改,否则执行报错!
删除节点
如果要删除这个/abc/JQK/XYZ/0001的子node,但是想要上一级XYZ这个node还是存在的,语句如下:
from kazoo.client import KazooClient
zk = KazooClient(hosts='192.168.91.128:2181') #如果是本地那就写127.0.0.
zk.start() #与zookeeper连接
#recursive=True是递归删除,就是无视下面的节点是否是空,都干掉,不加上的话,会提示子节点非空,删除失败
zk.delete('/abc/JQK/XYZ/0001',recursive=True)
node = zk.get_children('/') # 查看根节点有多少个子节点
print(node)
zk.stop() #与zookeeper断开
执行输出:
['abc', 'zookeeper']
更改节点
现在假如要在0001这个node里更改value,比如改成:"this is my horse!",
由于上面节点已经被删除掉了,需要先创建一次。
语句如下:
from kazoo.client import KazooClient
zk = KazooClient(hosts='192.168.91.128:2181') #如果是本地那就写127.0.0.
zk.start() #与zookeeper连接
zk.create('/abc/JQK/XYZ/0001',b'this is my house',makepath=True)
zk.set('/abc/JQK/XYZ/0001',b"this is my horse!")
node = zk.get('/abc/JQK/XYZ/0001') # 查看值
print(node)
zk.stop() #与zookeeper断开
执行输出:
(b'this is my horse!', ZnodeStat(czxid=, mzxid=, ctime=, mtime=, version=, cversion=, aversion=, ephemeralOwner=, dataLength=, numChildren=, pzxid=))
注意!set这种增加节点内容的方式是覆盖式增加,并不是在原有基础上增添。而且添加中文的话可能在ZooInspecter里出现的是乱码
查看节点
由于所有节点,都是在/ 节点上面的,直接查看根节点,就可以知道所有节点了
from kazoo.client import KazooClient
zk = KazooClient(hosts='192.168.91.128:2181') #如果是本地那就写127.0.0.
zk.start() #与zookeeper连接
node = zk.get_children('/')
print(node)
zk.stop() #与zookeeper断开
执行输出:
['abc', 'zookeeper']
一键清空zookeeper
有些时候,需要将zookeeper的数据全部清空,可以使用以下代码
from kazoo.client import KazooClient
zk = KazooClient(hosts='192.168.91.128:2181') #如果是本地那就写127.0.0.
zk.start() #与zookeeper连接
jiedian = zk.get_children('/') # 查看根节点有多少个子节点
print(jiedian)
for i in jiedian:
if i != 'zookeeper': # 判断不等于zookeeper
print(i)
# 删除节点
zk.delete('/%s'%i,recursive=True)
zk.stop() #与zookeeper断开
注意:默认的zookeeper节点,是不允许删除的,所以需要做一个判断。
本文参考链接:
https://www.cnblogs.com/linuxprobe/p/5851699.html
http://www.cnblogs.com/LUA123/p/7222216.html
http://blog.51cto.com/chenx1242/2053627
Zookeeper集群搭建以及python操作zk的更多相关文章
- zookeeper与Kafka集群搭建及python代码测试
Kafka初识 1.Kafka使用背景 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到这样的一些问题: 我们想分析下用户行为(pageviews),以便我们设计出更好的广告位 我想对用户 ...
- 分布式协调服务Zookeeper集群搭建
分布式协调服务Zookeeper集群搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.安装jdk环境 1>.操作环境 [root@node101.yinzhengjie ...
- kafka学习(二)-zookeeper集群搭建
zookeeper概念 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名 服务等.Zookeeper是h ...
- zookeeper集群搭建及Leader选举算法源码解析
第一章.zookeeper概述 一.zookeeper 简介 zookeeper 是一个开源的分布式应用程序协调服务器,是 Hadoop 的重要组件. zooKeeper 是一个分布式的,开放源码的分 ...
- 原创:centos7.1下 ZooKeeper 集群安装配置+Python实战范例
centos7.1下 ZooKeeper 集群安装配置+Python实战范例 下载:http://apache.fayea.com/zookeeper/zookeeper-3.4.9/zookeepe ...
- Zookeeper(二) zookeeper集群搭建 与使用
一.zookeeper集群搭建 鉴于 zookeeper 本身的特点,服务器集群的节点数推荐设置为奇数台.我这里我规划为三台, 为别为 hadoop01,hadoop02,hadoop03 1. ...
- ZooKeeper集群搭建过程
ZooKeeper集群搭建过程 提纲 1.ZooKeeper简介 2.ZooKeeper的下载和安装 3.部署3个节点的ZK伪分布式集群 3.1.解压ZooKeeper安装包 3.2.为每个节点建立d ...
- 【图文详解】Zookeeper集群搭建(CentOs6.3)
Zookeeper简介: Zookeeper是一个分布式协调服务,就是为用户的分布式应用程序提供协调服务的. A.zookeeper是为别的分布式程序服务的 B.Zookeeper本身就是一个分布式程 ...
- zookeeper集群搭建及常用场景实现
本文完整源码地址 基于zookeeper的常用用法.分布式锁.分布式队列及leader选举实现 https://github.com/killianxu/zookeeper_example zooke ...
随机推荐
- PostgreSQL之oracle_fdw安装与使用
目的介绍 现在项目开发遇到一个问题,就是需要从PostgreSQL中访问Oracle数据库 身为渣渣猿一脸懵逼.于是乎请教了公司的数据库方面的大牛韩工.告诉我用oracle_fdw 可以实现,但是在实 ...
- Java Servlet开发的轻量级MVC框架最佳实践
在Servlet开发的工程实践中,为了减少过多的业务Servlet编写,会采用构建公共Servlet的方式,通过反射来搭建轻量级的MVC框架,从而加快应用开发. 关于Servlet开发的基础知识,请看 ...
- boost.asio学习-----reslover 域名解析
将域名解析为ip地址并输出: #include "stdafx.h" #include "boost/asio.hpp" #include <boost/ ...
- Triangle Counting UVA - 11401(递推)
大白书讲的很好.. #include <iostream> #include <cstring> using namespace std; typedef long long ...
- 【agc001e】BBQ HARD(动态规划)
[agc001e]BBQ HARD(动态规划) 题面 atcoder 洛谷 题解 这些agc都是写的整场的题解,现在还是把其中一些题目单独拿出来发 这题可以说非常妙了. 我们可以把这个值看做在网格图上 ...
- stm32 外设使用的配置步骤
@2018-5-10 使用外设的配置步骤 #1 打开时钟 > 打开外设时钟 > 打开相关GPIO时钟 > 打开DMA时钟 (若需要) #2 关联外设与GPIO > 复位关联 ...
- bzoj4458 GTY的OJ (优先队列+倍增)
把超级钢琴放到了树上. 这次不用主席树了..本来以为会好写一点没想到细节更多(其实是树上细节多) 为了方便,对每个点把他的那个L,R区间转化成两个深度a,b,表示从[a,b)选一个最小的前缀和(到根的 ...
- [SDOI2009]Bill的挑战——全网唯一 一篇容斥题解
全网唯一一篇容斥题解 Description Solution 看到这个题,大部分人想的是状压dp 但是我是个蒟蒻没想到,就用容斥切掉了. 并且复杂度比一般状压低, (其实这个容斥的算法,提出来源于y ...
- laravel 命令行测试 Uncaught ReflectionException: Class config does not exist
require __DIR__ . '/vendor/autoload.php'; $app = require_once __DIR__ . '/bootstrap/app.php'; config ...
- ajax实现输入用户名异步提示是否可用
<script type="text/javascript"> //页面加载完毕后执行 $(document).ready(function(){ //用户名输入框绑定 ...