Python基础学习Day6 is id == 区别,代码块,小数据池 ---->>编码
一、代码块
Python程序是由代码块构造的。块是一个python程序的文本,他是作为一个单元执行的。
代码块:一个模块,一个函数,一个类,一个文件等都是一个代码块。
而作为交互方式输入的每个命令都是一个代码块。
什么叫交互方式?就是咱们在cmd中进入Python解释器里面,每一行代码都是一个代码块,例如:

而对于一个文件中的两个函数,也分别是两个不同的代码块:

二、is id == 的区别
在Python中,id是什么?id是内存地址,比如你利用id()内置函数去查询一个数据的内存地址:
name = '太白'
print(id(name)) # 1585831283968
name = 'alex'
print(id(name)) #2141531780016
那么 is 是什么? == 又是什么?
== 是比较的两边的数值是否相等,而 is 是比较的两边的内存地址是否相等。 如果内存地址相等,那么这两边其实是指向同一个内存地址。

可以说如果内存地址相同,那么值肯定相同,但是如果值相同,内存地址不一定相同
三、小数据池
小数据池,也称为小整数缓存机制,或者称为驻留机制等等,博主认为,只要你在网上查到的这些名字其实说的都是一个意思,叫什么因人而异。
那么到底什么是小数据池?他有什么作用呢?
大前提:小数据池,只针对,整数,字符串,bool值。
官方对于整数,字符串的小数据池是这么说的:
Python自动将-5~256的整数进行了缓存,当你将这些整数赋值给变量时,并不会重新创建对象,而是使用已经创建好的缓存对象。
python会将一定规则的字符串在字符串驻留池中,创建一份,当你将这些字符串赋值给变量时,并不会重新创建对象, 而是使用在字符串驻留池中创建好的对象。
其实,无论是缓存还是字符串驻留池,都是python做的一个优化,就是将~5-256的整数,和一定规则的字符串,放在一个‘池’(容器,或者字典)中,无论程序中那些变量指向这些范围内的整数或者字符串,那么他直接在这个‘池’中引用,言外之意,就是内存中之创建一个。
优点:能够提高一些字符串,整数处理人物在时间和空间上的性能;需要值相同的字符串,整数的时候,直接从‘池’里拿来用,避免频繁的创建和销毁,提升效率,节约内存。
缺点:在‘池’中创建或插入字符串,整数时,会花费更多的时间。
int:那么大家都知道对于整数来说,小数据池的范围是-5~256 ,如果多个变量都是指向同一个(在这个范围内的)数字,他们在内存中指向的都是一个内存地址。

那么对于字符串的规定呢?
str:字符串要从下面这几个大方向讨论:
1,字符串的长度为0或者1,默认都采用了驻留机制(小数据池)。


2,字符串的长度>1,且只含有大小写字母,数字,下划线时,才会默认驻留。

3,用乘法得到的字符串,分两种情况。
3.1 乘数为1时:
仅含大小写字母,数字,下划线,默认驻留。

含其他字符,长度<=1,默认驻留。

含其他字符,长度>1,默认驻留。

3.2 乘数>=2时:
仅含大小写字母,数字,下划线,总长度<=20,默认驻留。

4,指定驻留。
from sys import intern
a = intern('hello!@'*20)
b = intern('hello!@'*20)
print(a is b)
#指定驻留是你可以指定任意的字符串加入到小数据池中,让其只在内存中创建一个对象,多个变量都是指向这一个字符串。
满足以上字符串的规则时,就符合小数据池的概念。
bool值就是True,False,无论你创建多少个变量指向True,False,那么他在内存中只存在一个。
四、代码块与小数据池的关系
同样一段代码,为什么在交互方式中执行,和通过python代码的文件执行结果不同呢?
# pycharm 通过运行文件的方式执行下列代码:
i1 = 1000
i2 = 1000
print(i1 is i2) # 结果为True
通过交互方式中执行下面代码:
>>> i1 = 1000
>>> i2 = 1000
>>> print(i1 is i2)
False
结果为什么不同呢?难道是解释器出问题,还是pycharm软件出问题了??? NONONO,Too Young Too Simple!
这是因为代码块内的缓存机制,和代码块与代码块之间的缓存机制不同!
Python在执行同一个代码块的初始化对象的命令时,会检查是否其值是否已经存在,如果存在,会将其重用。换句话说:执行同一个代码块时,遇到初始化对象的命令时,他会将初始化的这个变量与值存储在一个字典中,在遇到新的变量时,会先在字典中查询记录,如果有同样的记录那么它会重复使用这个字典中的之前的这个值。所以在你给出的例子中,文件执行时(同一个代码块)会把i1、i2两个变量指向同一个对象。
如果是不同的代码块,他就会看这个两个变量是否是满足小数据池的数据,如果是满足小数据池的数据则会指向同一个地址。所以:i1、i2赋值语句分别被当作两个代码块执行,但是他们不满足小数据池的数据所以会得到两个不同的对象,因而is判断返回False。
更多验证:

# 虽然在同一个文件中,但是是不同的代码块,不满足小数据池(驻存机制),则指向两个不同的地址。
def func():
i1 = 1000
print(id(i1)) # 2288555806672 def func2():
i1 = 1000
print(id(i1)) # 2288557317392 func()
func2()
最后,在深入一点,对于同一个代码块的变量复用的问题,只能针对于数字,字符串,bool值,而对于其他数据类型是不成立的。
# 同一个代码块下,数字,字符串,bool值的复用成立。
a1 = 1000
a2 = 1000
print(id(a1),id(a2)) # 2419837390800 2419837390800 s1 = 'alexsb@'
s2 = 'alexsb@' print(id(s1),id(s2)) # 2278732245624 2278732245624 f1 = True
f2 = True
print(id(f1),id(f2)) # 1672093872 1672093872 # 同一个代码块下,元祖,列表,字典的复用不成立。
tu1 = (1,2,3)
tu2 = (1,2,3)
print(id(tu1),id(tu2)) # 2278732278088 2278732279312 l1 = [1, 2, 3]
l2 = [1, 2, 3]
print(id(l1),id(l2)) # 2278733685000 2278733685192 dic1 = {'name':'taibai'}
dic2 = {'name':'taibai'}
print(id(dic1),id(dic2)) # 2278728382728 2278728382856
五、编码
ascii: 字母,数字,特殊字符。
A: 0000 0010
B: 0000 0010
unicode: 万国码,包含世界上所有的文字。
创建之初:
A :0000 0010 0000 0010
中:0001 0010 0000 0010
升级:
A :0000 0010 0000 0010 0000 0010 0000 0010 32 位
中:0001 0010 0000 0010 0000 0010 0000 0010
缺点:浪费资源。
对unicode 升级:utf-8
A :0000 0010 8位
欧:0000 0010 0000 0010 16位
中:0000 0010 0000 0010 0000 0010 24位
gb2312: 国标:字母,数字,特殊字符,中文。
A :0000 0010 8位
中:0000 0010 0000 0010 16位
1, 编码之间能不能互相识别。 不能互相识别。
2, 网络传输,或者硬盘存储的010101,必须是以非uniocde编码方式的01010101.
大环境python3x:
str:内存(内部)编码方式为Unicode。
bytes:python的基础数据类型之一,他和str相当于双胞胎,str拥有的所有方法,bytes类型都适用。
其他数据类型:int、tuple、list、dict、set
区别:
英文字母
str:
表现形式:s1 = 'alex'
内部编码方式:unicode
bytes:
表现形式:b1 = b'alex'
内部编码方式:非unicode
中文:
str:
表现形式:s1 = '太白'
内部编码方式:unicode
bytes:
表现形式:b1 = b'\xe5\xa4\xaa\xe7\x99\xbd'
内部编码方式:非unicode
如何使用:
你想将一部分内容(字符串)写入文件,或者通过网络socket传输,这样这部分内容(字符串)必须转化成bytes才可以进行。
平时你代码中,使用字符串。
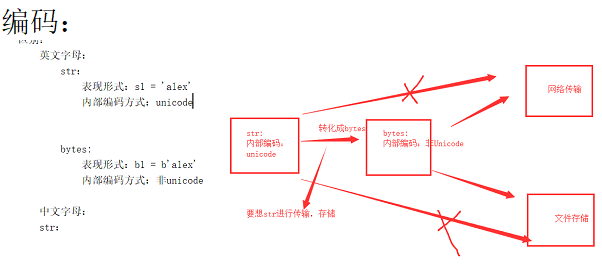
str --- > bytes encode 编码
# str --- > bytes encode 编码
s1 = 'alex'
s2 = '太白'
b1 = s1.encode('utf-8')
print(b1)
b2 = s2.encode('gbk')
print(b2)
bytes ---> str decode 解码
b1 = b'\xcc\xab\xb0\xd7' # gbk 的bytes
s2 = b1.decode('gbk')
print(s2)
Python基础学习Day6 is id == 区别,代码块,小数据池 ---->>编码的更多相关文章
- python基础学习day6
代码块.缓存机制.深浅拷贝.集合 id.is.== id: 可类比为身份号,具有唯一性,若id 相同则为同一个数据. #获取数据的内存地址(随机的地址:内存临时加载,存储数据,当程序运行结束后,内存地 ...
- python 全栈开发,Day6(is,小数据池,编码转换)
一.is a = 100 b = 100 print(a == b) print(a is b) 执行输出: TrueTrue 查看内存地址,使用id函数 print(id(a)) print(id( ...
- is和==的区别,小数据池,编码
1 is 和 == 的区别 1> id( )表示我们可以通过它来查到在内存中的地址 s = "alex" lst = [1,2, 4] lst = [1, 2, ...
- python之路(内存,小数据池,编码等)
代码块: python真正的代码块:一个模块,一个函数,一个类,一个文件等都是一个代码块. 但是,在python终端交互模式下,每一条代码都是一个代码块 python在同一个代码块中的变量,初始化对象 ...
- python --- 06 小数据池 编码
一.小数据池, id() 进行缓存 1.小数据池针对的是: int, str, bool 2.在py文件中几乎所有的字符串都会缓存. 在cmd命令窗口中几乎都不会缓存 不同的解释器有不同 ...
- python之路---06 小数据池 编码
二十二.小数据池, id() 进行缓存 1.小数据池针对的是: int, str, bool 2.在py文件中几乎所有的字符串都会缓存. 在cmd命令窗口中几乎都不会缓存 不同的解释器有 ...
- is 与 == 的区别;小数据池; 编码与解码
1, is 与 == 的区别 == 比较的是两边的值 is 比较的是两边的地址 id () 2,小数据池(在终端中) 数字小数据池的范围 -5 ~ 256 字符串中如果有特殊字符他们的内存地址 ...
- 百万年薪python之路 -- 小数据池和代码块
1.小数据池和代码块 # 小数据池 -- 缓存机制(驻留机制) # == 判断两边内容是否相等 # a = 10 # b = 10 # print(a == b) # is 是 # a = 10 # ...
- python -- 小数据池 is和 == 再谈编码
1.小数据池 python程序是由代码块构成的,一个代码块的文本作为python程序的执行单元. 代码块:一个模块,一个函数,一个类,甚至一个command命令都是一个代码块,一个文件也是一个代码块, ...
随机推荐
- 锚点定位,jquery定位到页面指定位置
jquery锚点定位 $('body,html').animate({scrollTop: $('#ter1').offset().top}, 500);#ter1是你要定位的id对象,500是0.5 ...
- solr 请求参数过长报错,Solr配置maxBooleanClauses属性不生效原因分析
博客分类: 上次已经写过一篇关于solr中,查询条件过多的异常的文章,这次在总结扩展一下: 有时候我们的查询条件会非常多,由于solr的booleanquery默认设置的条件数为1024,所以超过 ...
- linux安装chrome浏览器
按照下面的方式安装 wget -P /home/linfu/桌面 https://dl.google.com/linux/direct/google-chrome-stable_current_amd ...
- WPF 异步刷新页面,创建定时器
#region 异步,刷新页面 /// <summary> /// 页面加载事件 /// </summary> /// <param name="sender& ...
- JAVA给图片添加水印
package com.test; import org.junit.Test; import javax.imageio.ImageIO; import java.awt.*; import jav ...
- py库: Tesseract-OCR(图像文字识别)
http://blog.csdn.net/u012566751/article/details/54094692 Tesseract-OCR入门使用1 http://blog.csdn.net/u01 ...
- C#面向对象基础2
一.属性 作用:保护字段,对字段的赋值取值进行限定 意思是在初始化对象的时候防止出现不是事实的违规操作 如将性别赋值为‘中’ 本质:两个方法 get方法和set方法. p ...
- python中的popitem
popitem()随机删除字典中的任意键值对,并返回到元组中 1 a = { 2 "name":"dlrb", 3 "age":25, 4 ...
- jdk src 学习 Threadlocal
示例: import java.io.Serializable; public class TestThreadLocal implements Serializable { /** * */ pri ...
- 登录之md5加密
语句: password = hex_md5(password); 引入js文件: md5.js: /* * A JavaScript implementation of the RSA Data S ...