论文阅读 | Clustrophile 2: Guided Visual Clustering Analysis
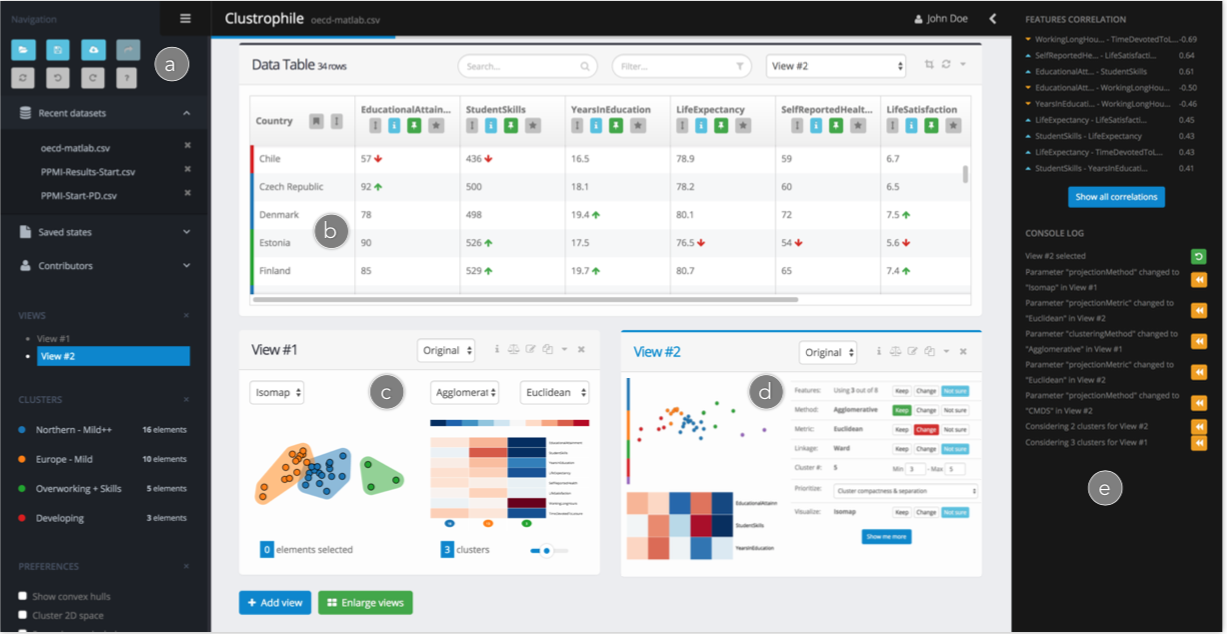
左侧边栏可以导入数据,或者打开以及前保存的结果。右侧显示了所有的日志,可以轻松回到之前的状态,视图的主区域上半部分是数据,下半部分是聚类视图。
INTRODUCTION
数据聚类对于处理无标签数据,高维数据是非常有效的工具。聚类算法中如何确定最好的聚类方法和参数比较困难,需要可视化系统的帮助。Clustrophile 2,这是一种用于引导聚类分析的新型交互式工具,引导用户进行基于聚类的探索性分析,调整用户反馈以改进聚类效果,并帮助快速推理群集之间的差异。为此,Clustrophile 2提供了一个新颖的功能,clustering tour,帮助用户选择聚类参数,并评估与当前分析目标和用户期望的差距。我们通过12位数据科学家的user study评估这个系统。结果表明,Clustrophile 2提高了专家和非专家的探索性聚类分析的速度和有效性。
DESIGN CRITERIA
Clustrophile 2总结了9个设计标准:
Show variation within clusters(快速显示聚类效果),Allow quick iteration over parameters (实时更新参数),Represent clustering instances compactly(多视图显示),Facilitate interpretable naming(数据簇重命名和分离),Support analysis of large datasets(大型数据支持),Support reasoning about clusters and clustering instances(支持对于聚类结果的推断和评估),Promote multiscale exploration(多尺度探索聚类),Keep a stateful representation of the current analysis(保存当前探索状态),Guide users in clustering analysis(指导用户聚类分析)。
论文中作者这样描述本文的贡献:
在Clustrophile系统的基础上,增加丰富的聚类算法,参数,评估指标以及可视化工具。
开发出引导用户进行聚类分析的一体化程序,Clustering Tour。
定义了更合理的聚类质量衡量指标,考虑了用户反馈,可解释性等方面
USER INTERFACE AND INTERACTIONS
可视化系统的主视图包括,聚类视图,调参推荐界面,聚类之旅(clusting tour) 三个部分
Visualization Views
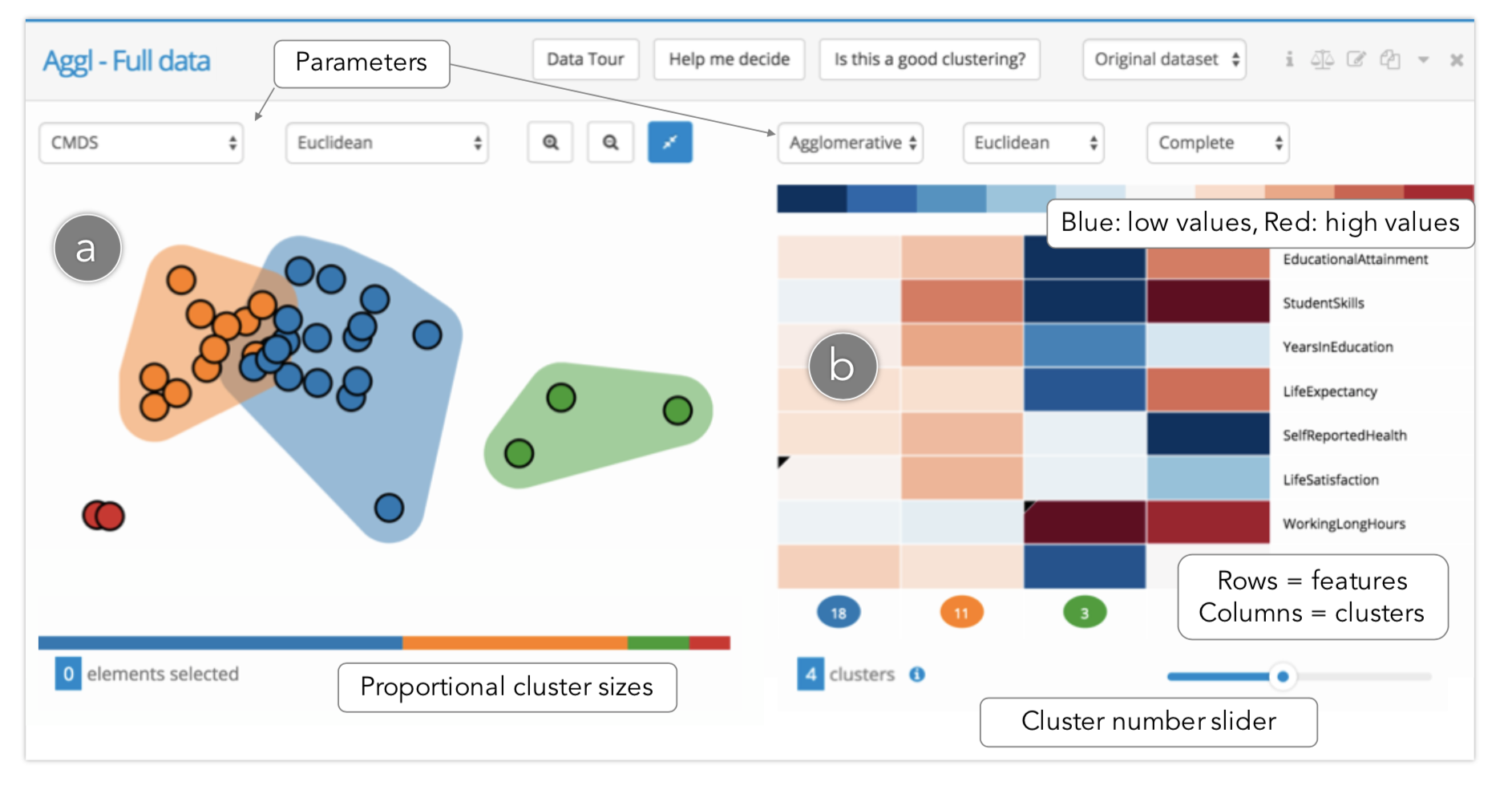
在聚类视图中,散点图显示了数据降维后投影在2D平面上的数据聚类结果,其中距离编码数据点之间的相似性,而右侧的热力图中每列代表一个聚类,而行代表了不同的特征,颜色深浅代表了数据的相对大小。
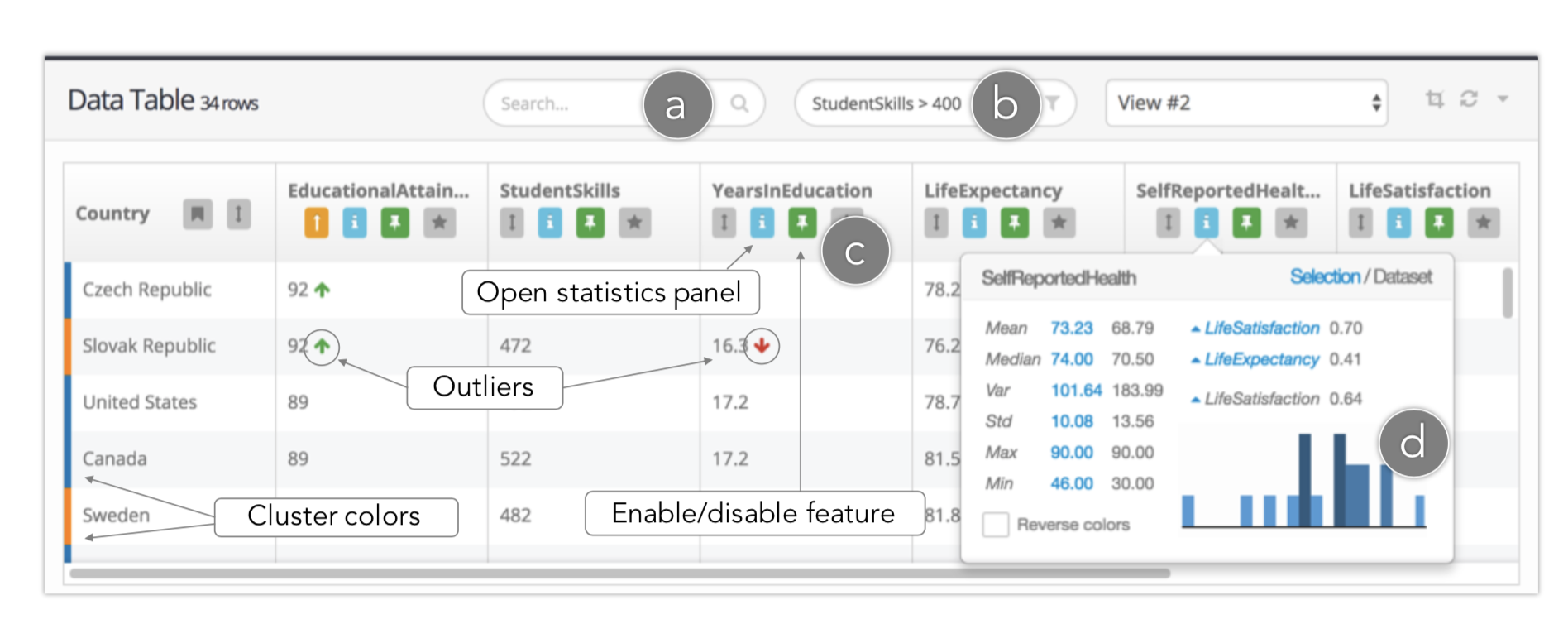
除此之外,我们还可以通过观察数据表的界面对于数据进行观察和筛选
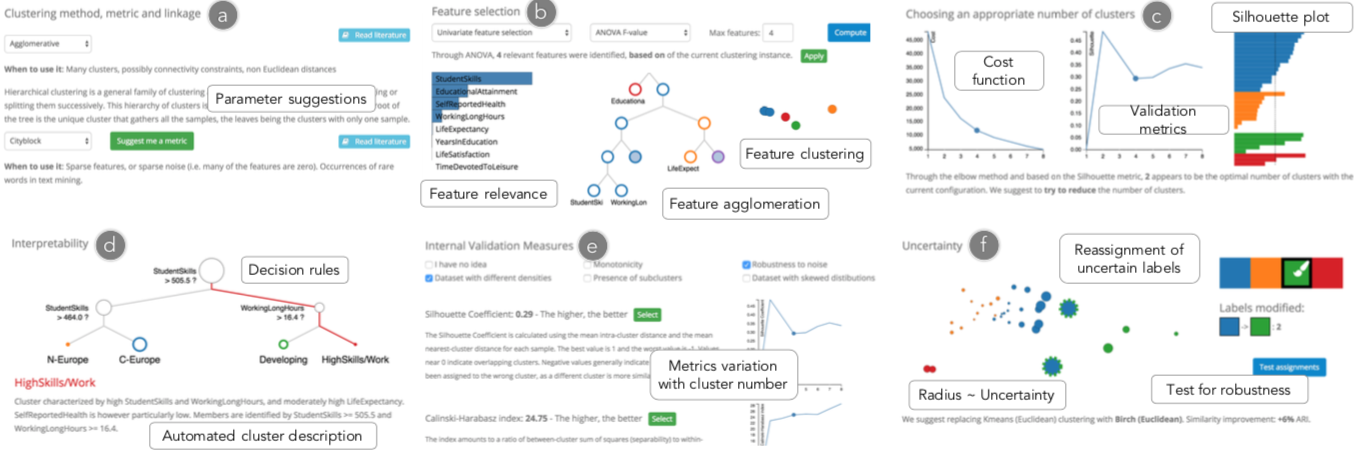
Choosing Parameters and Guiding Users Towards a Better Clustering
Clustrophile 2在调参与算法推荐的功能详尽,并提供了完备的聚类效果衡量标准:
Clustrophile2支持自动调参,删除具有低方差的特征,支持自定义采样。
根据数据特征推荐合适的聚类算法,根据分层聚类的树形图推荐合适的集群数量。
- 将不同的投影方式进行比较,推荐能将聚类紧凑性和分离性尽量满足的投影(降维)算法。
- 从偏斜分布程度,子簇密度,算法对噪声的鲁棒性,cost function的单调性等方面定量的衡量聚类结果
- 通过将聚类结果放入决策树进行训练,这样可以推断不同集群中的数据点的主要特征
支持分析聚类分布中的异常点,删除它们后重新聚类
Clustering Tour
通过迭代地改变所有聚类参数,用户可以动态地探索可能的聚类解决方案的空间,直到找到满意的解决方案或数据集。但是,即使在参数选择的指导下,可能的参数组合和聚类解决方案的空间太大,无法完全手动探索。某些参数选择在很大程度上影响聚类结果,而其他参数对结果的影响最小。考虑到这一概念,我们引入了聚类游览功能,以帮助用户快速探索可能的聚类结果空间。下面的界面包含(a)先前探索的解决方案列表,(b,c)散点图和热图可视化当前的方案,(e)用户提供反馈的一组按钮,喜欢还是拒绝,(d)用户可以约束参数更新方式的模态选择。
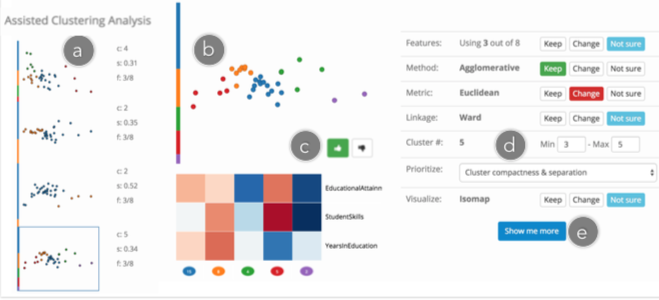
整个类似模拟退火的过程。系统首先会按照每种聚类的相似性,找出差距较大的几种聚类结果。用户依次浏览这些解决方案,如果喜欢这个方案,系统会在这个方案基础上进行轻微的参数改动,相当于进入了一个叶子节点。如果不满意就会退回到父亲。直到探索时间和方案数等达到一个阖值为止。

USER STUDY
实验对象,12位数据科学从业者
实验目标::1)了解数据科学家如何根据数据领域的先验知识进行交互 2)如何在开放式分析任务中找到了令人满意的解决方案
- 实验数据:患有帕金森病的受试者数据集,该数据集具有8652行和37个特征
- 实验任务:识别代表帕金森病的不同类型。我们要求参与者确定他们满意的一个聚类实例,为每个聚类分配名称和描述,最后口头解释他们获得这个结果的重要性。
我们将候选人分为三类:黑客,脚本编写者和应用程序用户。每种4人,并且每个人中有2个人了解医学知识。
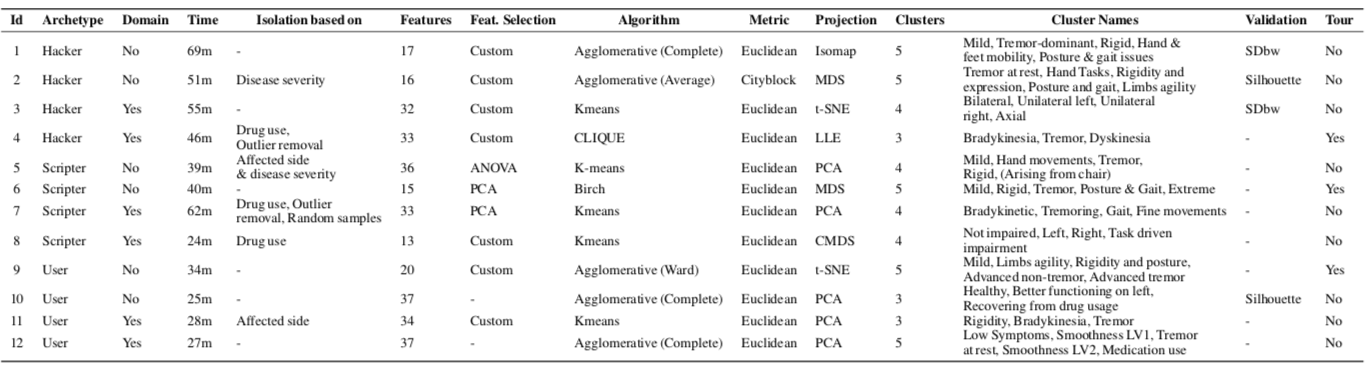

从实验结果,我们证明Clustrophile 2证明不同类型的数据分析师。十二个用户中的三个(其中两个属于应用程序用户原型)倾向于使用ClusterCour来进行分析。最后,分析继续对聚类参数和所选特征进行迭代和循环修改,直到参与者意识到他们只能找到聚类基于受影响的一方或疾病严重程度的结果。这些聚类很容易从热图可视化中解释,热图可视化显然可以提供非常有效的信息。
CONCLUSION
调参和算法选择是非常重要的
Clustering Tour 提高了用户自主性和创造力
用户对结果的反馈加快了探索过程
管理,缓存数据和过程方便了用户的探索
此外还有一些可以改进的点
增加可解释性的聚类研究
增加更多预计算与推荐功能
增加对于任意聚类算法接口的支持,增加代码接口,让用户可以在框架进行拓展
论文阅读 | Clustrophile 2: Guided Visual Clustering Analysis的更多相关文章
- 论文阅读:Review of Visual Saliency Detection with Comprehensive Information
这篇文章目前发表在arxiv,日期:20180309. 这是一篇针对多种综合性信息的视觉显著性检测的综述文章. 注:有些名词直接贴原文,是因为不翻译更容易理解.也不会逐字逐句都翻译,重要的肯定不会错过 ...
- 【论文阅读】Deep Adversarial Subspace Clustering
导读: 本文为CVPR2018论文<Deep Adversarial Subspace Clustering>的阅读总结.目的是做聚类,方法是DASC=DSC(Deep Subspace ...
- 【CV论文阅读】Unsupervised deep embedding for clustering analysis
Unsupervised deep embedding for clustering analysis 偶然发现这篇发在ICML2016的论文,它主要的关注点在于unsupervised deep e ...
- [论文阅读笔记] GEMSEC,Graph Embedding with Self Clustering
[论文阅读笔记] GEMSEC: Graph Embedding with Self Clustering 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 已经有一些工作在使用学习 ...
- 论文阅读 | Region Proposal by Guided Anchoring
论文阅读 | Region Proposal by Guided Anchoring 相关链接 论文地址:https://arxiv.org/abs/1901.03278 概述 众所周知,anchor ...
- 【医学图像】3D Deep Leaky Noisy-or Network 论文阅读(转)
文章来源:https://blog.csdn.net/u013058162/article/details/80470426 3D Deep Leaky Noisy-or Network 论文阅读 原 ...
- 论文阅读:Face Recognition: From Traditional to Deep Learning Methods 《人脸识别综述:从传统方法到深度学习》
论文阅读:Face Recognition: From Traditional to Deep Learning Methods <人脸识别综述:从传统方法到深度学习> 一.引 ...
- Nature/Science 论文阅读笔记
Nature/Science 论文阅读笔记 Unsupervised word embeddings capture latent knowledge from materials science l ...
- BERT 论文阅读笔记
BERT 论文阅读 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 由 @快刀切草莓君 ...
随机推荐
- NFS网络共享介绍与使用
什么是NFS(网络文件系统)? NFS(Network File System)即网络文件系统,是FreeBSD支持的文件系统中的一种,它允许网络中的计算机之间通过TCP/IP网络共享资源.它的主要功 ...
- div中嵌套div水平居中,垂直居中
方法一: div(父):display:table; div(子):display:table_cell;margin:0 auto;vertical-align:middle; 方法二: div(父 ...
- JAVA随机数之多种方法从给定范围内随机N个不重复数
一.JAVA中生成随机数的方式 1.在j2se中使用Math.random()令系统随机选取一个0~1之间的double类型小数,将其乘以一个数,比如25,就能得到一个0~25范围内的随机数,这个在j ...
- 谁对EXTJS熟悉,有关关闭panel的问题?
谁对EXTJS熟悉,有关关闭panel的问题?比如:我在A.js 中写了一个 var win = new Ext.Window( { b.js }); win.show(); 打开了一 ...
- c# winform 自动升级
winform自动升级程序示例源码下载 客户端思路: 1.新建一个配置文件Update.ini,用来存放软件的客户端版本: [update] version=2011-09-09 15:26 2.新 ...
- String----是一个对象
* 字符串可以看成是字符组成的数组,但是js中没有字符类型 * 字符是一个一个的,在别的语言中字符用一对单引号括起来 * 在js中字符串可以使用单引号也可以使用双引号 * 因为字符串可以看成是数组,所 ...
- Drool实战系列(二)之eclipse安装drools插件
这里演示是drools7.5.0,大家可以根据自己需要安装不同的drools版本 drools安装地址: http://download.jboss.org/drools/release/ 一. 二. ...
- torchvision
torchvision是一个包,它服务于pytorch深度学习框架,用来生成图片,视频数据集,模型类和预训练的模型torchvision由以下四个部分组成:1. torchvision.dataset ...
- win10家庭版安装DockerToolbox-18.03.0-ce
下载DockerToolbox-18.03.0-ce.exe https://mirrors.aliyun.com/docker-toolbox/windows/docker-toolbox/ 点击安 ...
- (四) DRF认证, 权限, 节流
一.Token 认证的来龙去脉 摘要 Token 是在服务端产生的.如果前端使用用户名/密码向服务端请求认证,服务端认证成功,那么在服务端会返回 Token 给前端.前端可以在每次请求的时候带上 To ...