使用pandas库实现csv行和列的获取
1、读取csv
import pandas as pd
df = pd.read_csv('路径/py.csv')
2、取行号
index_num = df.index
举个例子:
import pandas as pd
df = pd.read_csv('./IP2LOCATION.csv',encoding= 'utf-8')
index_num = df.index
print(index_num)

3、取出行
import pandas as pd
df = pd.read_csv('./IP2LOCATION.csv',encoding= 'utf-8',header=None)
# print(type(df))
df.columns = ['a','b','c','d','e','f']
# 获取行数
# index_num = df.index
# print(index_num)
# 取出某一行
# row_data_1 = df.iloc[0]
# row_data_2 = df.iloc[[0]]
# 取出连续的行
# row_data_3 = df.iloc[0:2]
# row_data_4 = df[0:2]
# 取出不连续的行
# row_data_5 = df.iloc[[0,2]]
# print(row_data_5)
只取一行
可以使用df.iloc[行号],得到的是series
也可以使用df.iloc[[行号]],得到的是dataframe
row_data_1 = df.iloc[0] # pandas series
row_data_2 = df.iloc[[0]] # dataframe
loc是显式的索引,默认第一行的行号为1,行号从1计数
iloc是隐式的索引,默认第一行的行号为0,行号从0计数
row_data_1
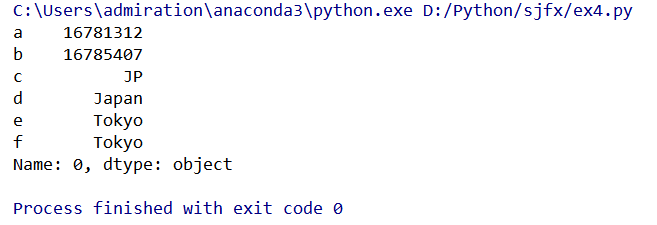
row_data_2

取连续的几行
可以用df.iloc[行号:行号],也可以用df[行号:行号],得到的都是dataframe
row_data_3 = df.iloc[0:2]
row_data_3 = df[0:2]
row_data_3

row_data_4

取出不连续的几行
使用df.iloc[[行号,行号]],特别注意是两个方括号,中间是逗号,得到的是dataframe
row_data_5 = df.iloc[[0,2]]
row_data_5

4、取出列
import pandas as pd
df = pd.read_csv('./IP2LOCATION.csv',encoding= 'utf-8',header=None)
# print(type(df))
df.columns = ['a','b','c','d','e','f']
# 只取一列
# col_data_1 = df['a'] # 单独一列是个series
# col_data_2 = df.loc[:,'a'] # 同上,但比较复杂,一般不用
# col_data_3 = df.iloc[:,0] # 同上,可以在不知道列名的时候用
#
# col_data_4 = df[['a']] # 单独一列是个df
# col_data_5 = df.loc[:,['a']] # 同上,但比较复杂,一般不用
# col_data_6 = df.iloc[:,[0]] # 同上,可以在不知道列名的时候用
# print(col_data_4)
# 获取指定的几列
# cols_data_1 = df[['a','b']] # DataFrame, 指定某几列,直接用列名
# cols_data_2 = df.loc[:,['a','b']] # 同上,但比较复杂,一般不用
# cols_data_3 = df.iloc[:,[0,2]] # 同上,可以在不知道列名的时候用
# print(cols_data_1)
# 获取指定的连续列
# cols_data_4 = df.loc[:,'a':'d'] # 指定连续列,用列名
# cols_data_5 = df.iloc[:,0:4] # 指定连续列,用数字
# print(cols_data_4)
只取一列
col_data_1 = df['a']# 单独一列是个seriescol_data_2 = df.loc[:,'a']# 同上,但比较复杂,一般不用col_data_3 = df.iloc[:,0] # 同上,可以在不知道列名的时候用
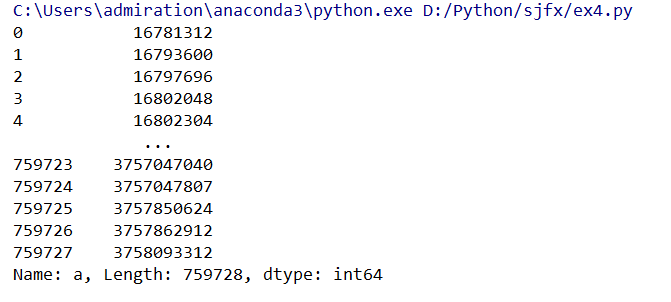
以上三种均为只取一列的操作,并且是等效的,获取的都是series类型
下面三种也是等效的,但是获取的是dataframe类型
col_data_4 = df[['a']] # 单独一列是个df
col_data_5 = df.loc[:,['a']] # 同上,但比较复杂,一般不用
col_data_6 = df.iloc[:,[0]] # 同上,可以在不知道列名的时候用
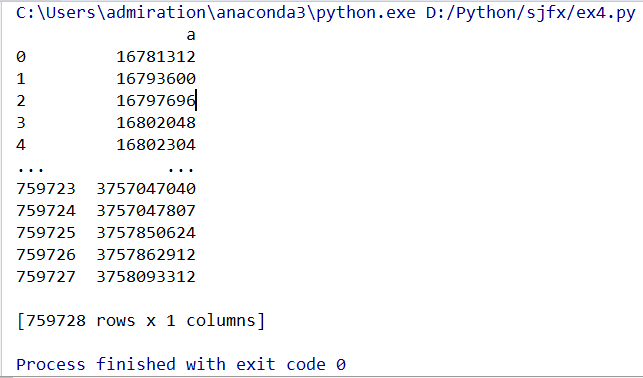
取指定的某几列
cols_data_1 = df[['a','b']] # DataFrame, 指定某几列,直接用列名
cols_data_2 = df.loc[:,['a','b']] # 同上,但比较复杂,一般不用
cols_data_3 = df.iloc[:,[0,2]] # 同上,可以在不知道列名的时候用

获取指定的连续几列
cols_data_4 = df.loc[:,'a':'d'] # 指定连续列,用列名
cols_data_5 = df.iloc[:,0:4] # 指定连续列,用数字
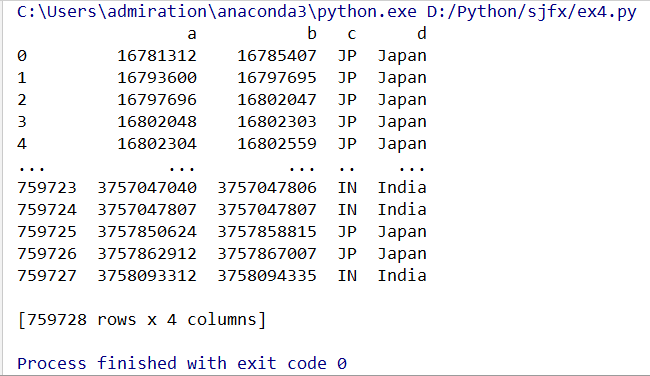
5、取指定行和列
import pandas as pd
df = pd.read_csv('./IP2LOCATION.csv',encoding= 'utf-8',header=None)
# print(type(df))
df.columns = ['a','b','c','d','e','f']
# 获取指定行列
# 第一种,列索引用数字表示
# data_1 = df.iloc[[1,3],[0]]
# data_2 = df.iloc[[1,3],0]
# data_3 = df.iloc[[1,3],1:3]
# data_4 = df.iloc[[1,3],[1,3]]
# print(data_4)
# 第二种,列索引直接引用列名
# data_5 = df.loc[1,['a','d']]
# data_6 = df.loc[[1],['a','d']]
# data_7 = df.loc[[1,3],'a':'d']
# data_8 = df.loc[[1,3],['a','d']]
# print(data_8)
列索引用数字表示
第一种情况是列索引用数字表示, df.iloc[行索引表达,列索引表达],规则跟上面行索引一模一样。
data_1 = df.iloc[[1,3],[0]]

data_2 = df.iloc[[1,3],0] # series
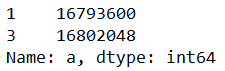
data_3 = df.iloc[[1,3],1:3]

data_4 = df.iloc[[1,3],[1,3]]
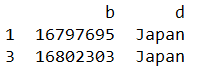
列索引直接引列名
第二种情况是列索引直接引列名(行索引不存在这个问题,因为pandas没有所谓'行名'),就要用df.loc[行索引,列名索引。
data_5 = df.loc[1,['a','d']] # series

data_6 = df.loc[[1],['a','d']]
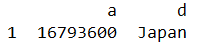
data_7 = df.loc[[1,3],'a':'d']

data_8 = df.loc[[1,3],['a','d']]

使用pandas库实现csv行和列的获取的更多相关文章
- POI教程之第二讲:创建一个时间格式的单元格,处理不同内容格式的单元格,遍历工作簿的行和列并获取单元格内容,文本提取
第二讲 1.创建一个时间格式的单元格 Workbook wb=new HSSFWorkbook(); // 定义一个新的工作簿 Sheet sheet=wb.createSheet("第一个 ...
- python的pandas库读取csv
首先建立test.csv原始数据,内容如下 时间,地点 一月,北京 二月,上海 三月,广东 四月,深圳 五月,河南 六月,郑州 七月,新密 八月,大连 九月,盘锦 十月,沈阳 十一月,武汉 十二月,南 ...
- 用pandas库对csv文件中的文本数据进行分析处理
#数据分析 import pandas import csv old_path = r'd:\2000W\200W-400W.csv' f = open(old_path,'r',encoding=' ...
- Python之文件读写(csv文件,CSV库,Pandas库)
前言 一.Python文件读取 二.读取CSV文件 一.Python文件读取 1. open函数是内置函数之with操作 - 关于路径设置的问题斜杠设置成D:\\文件夹\\文件或是D:/文件夹/文件 ...
- Python之使用Pandas库实现MySQL数据库的读写
本次分享将介绍如何在Python中使用Pandas库实现MySQL数据库的读写.首先我们需要了解点ORM方面的知识. ORM技术 对象关系映射技术,即ORM(Object-Relational ...
- python做数据分析pandas库介绍之DataFrame基本操作
怎样删除list中空字符? 最简单的方法:new_list = [ x for x in li if x != '' ] 这一部分主要学习pandas中基于前面两种数据结构的基本操作. 设有DataF ...
- Pandas库常用函数和操作
1. DataFrame 处理缺失值 dropna() df2.dropna(axis=0, how='any', subset=[u'ToC'], inplace=True) 把在ToC列有缺失值 ...
- python pandas库——pivot使用心得
python pandas库——pivot使用心得 2017年12月14日 17:07:06 阅读数:364 最近在做基于python的数据分析工作,引用第三方数据分析库——pandas(versio ...
- 建议42:使用pandas处理大型CSV文件
# -*- coding:utf-8 -*- ''' CSV 常用API 1)reader(csvfile[, dialect='excel'][, fmtparam]),主要用于CSV 文件的读取, ...
随机推荐
- 总结:js世界中的特殊符号
常用符号:+ ++ - -- || / /' && 等 这些基本上每天都能用到,但是 js 世界中有些特殊符号是不常用的,我也是偶然在阅读大神代码的时候发现的,一番查找之后得出了以下结 ...
- Playbook中标签的使用(五)
一个playbook文件中,执行时如果想执行某一个任务,那么可以给每个任务集进行打标签,这样在执行的时候可以通过-t选择指定标签执行, 还可以通过--skip-tags选择除了某个标签外全部执行等 [ ...
- mybatis 批量保存,并且唯一约束
1.主键返回在insert配置中添加两个属性 useGeneratedKeys="true" keyProperty="id" 2.唯一约束冲突可以使用 ON ...
- 自动化部署jenkins
jenkins下载网站 https://mirrors.tuna.tsinghua.edu.cn/jenkins/redhat/ 一.配置环境 [root@localhost ~]# hostname ...
- iOS逆向之一 工具的安装和使用
iOS逆向之一-工具的安装和使用 最近在学习iOS安全方面的技术,有些东西就记录下来了,所有有了这篇文章.顺便也上传了DEMO,可以再这里找到这些DEMO的源码:dhar/iOSReProject 越 ...
- telnet 636端口不通
今天发生了一件奇怪的事情,LDAP的636端口突然就不通了报错如下 [www@DC ~]$ telnet 10.219.90.173 636Trying10.219.90.173...Connecte ...
- 使用ScriptX控件进行Web横向打印
一个需求需要采用横向打印,目前采用IE自身的打印功能(WebBrowser.ExecWB控件)很难进行横向设置,默认需要调用document.all.WebBrowser.ExecWB(8,1);打开 ...
- U-Mail邮件系统详解邮件收发延迟原因及解决方案
邮件是现代社会办公最常见.最频繁的通联工具,但使用邮件系统时,用户普遍最关心两个安全,一个是安全性,邮件会不会被窃密?自己的邮箱账号会不会被盗取被攻占呢?保存的数据会不会丢失呢?关于这个问题,国内知名 ...
- Markdown中希腊字母与代码对应表
字母 代码 α\alphaα $\alpha$ β\betaβ $\beta$ γ\gammaγ $\gamma$ Γ\GammaΓ $\Gamma$ δ\deltaδ $\delta$ Δ\Delt ...
- Python的内存管理和垃圾回收
内存管理 与Python对象创建相关的结构体 #define _PyObject_HEAD_EXTRA \ struct _object *_ob_next; \ struct _object *_o ...