LinkedList为什么增删快、查询慢
- ArrayList:长于随机访问元素,中间插入和移除元素比较慢,在插入时,必须创建空间并将它的所有引用向前移动,这会随着ArrayList的尺寸增加而产生高昂的代价,底层由数组支持。
- LinkedList:通过代价较低的在List中间进行插入和删除操作,只需要链接新的元素,而不必修改列表中剩余的元素,无论列表尺寸如何变化,其代价大致相同,提供了优化的顺序访问,随机访问相对较慢,特性较ArrayList更大,而且还添加了可以使其作为栈、队列或双端队列的方法,底层由双向链表实现。

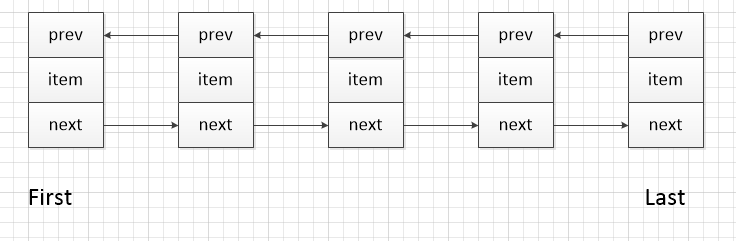
//关于Node构造函数
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev; Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
//transient 保证以下几个属性不被序列化
/**
* The number of times this list has been <i>structurally modified</i>.
* 该字段表示list结构上被修改的次数。结构上的修改指的是那些改变了list的长度
* 大小或者使得遍历过程中产生不正确的结果的其它方式。
*
*/
protected transient int modCount = 0; transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
public boolean add(E e) {
linkLast(e);
return true;
}
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
- 获得最后一个节点last作为当前节点l
- 用当前节点l、添加参数e、null创建一个新的Node对象
- 将新创建的Node对象链接到最后节点,也就是last
- 如果当前的LinkedList为空,那么添加的node就是first,也是last
- 当前LinkedList的size+1,表示结构改变次数的对象modCount+1
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
LinkedList的删除中,会根据传递进来的参数进行null判断,因为在LinkedList的元素移除中,null和非null的处理不一样,对于nul使用==去判断是否匹配,对于非null使用.equals(Object o)去判断,至于==和equals的区别,读者自行百度。
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
- 如果前一个节点prev为null,即第一个节点元素,则链表first = x下一个节点;
- 如果前一个节点prev不为null,即不是第一个节点元素,则将当前节点的next赋值给prev.next,x.prev置为null,也就是当前节点x的prev和next和当前链表中的其他元素不存在任何联系;
- 如果下一个节点next为null,即为最后一个元素,则链表last = x前一个节点;
- 如果下一个节点next不为null,即不为最后一个元素,则将当前节点的prev赋值给next.prev,同样当前节点x的prev和next和当前链表中的其他元素不存在任何联系;
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
- 根据传入的index去判断是否为LinkedList中的元素,判断逻辑为index是否在0和size之间,如果在则调用node(index)方法,否则抛出IndexOutOfBoundsException;
- 调用node(index)方法,将size右移1位,即size/2,判断传入的size在LinkedList的前半部分还是后半部分
- 如果在前半部分,即index < size/2,则从fisrt节点开始遍历匹配
- 如果在后半部分,即index > size/2,则从last节点开始遍历匹配
LinkedList为什么增删快、查询慢的更多相关文章
- 集合之LinkedList源码分析
转载请注明出处:http://www.cnblogs.com/qm-article/p/8903893.html 一.介绍 在介绍该源码之前,先来了解一下链表,接触过数据结构的都知道,有种结构叫链表, ...
- 数据结构-List接口-LinkedList类-Set接口-HashSet类-Collection总结
一.数据结构:4种--<需补充> 1.堆栈结构: 特点:LIFO(后进先出);栈的入口/出口都在顶端位置;压栈就是存元素/弹栈就是取元素; 代表类:Stack; 其 ...
- ArrayList和LinkedList的共同点和区别
ArrayList和LinkedList的相同点和不同点 共同点:都是单列集合中List接口的实现类.存取有序,有索引,可重复 不同点: 1.底层实现不同: ArrayList底层实现是数组,Link ...
- List-ApI及详解
1.API : add(Object o) remove(Object o) clear() indexOf(Object o) get(int i) size() iterator() isEmpt ...
- javaList容器中容易忽略的知识点
在集合类框架中,List是使用比较多的一种 List |---Arraylist 内部维护的是一个数组,查找快增删慢 |---LinkedList 底层是链表,增删快查询慢. |---Vctor线程安 ...
- java_List集合及其实现类
第一章:List集合_List接口介绍 1).特点 1).有序的: 2).可以存储重复元素: 3).可以通过索引访问: List<String> list = new Arra ...
- java基础-day17
第06天 集合 今日内容介绍 u 集合&迭代器 u 增强for & 泛型 u 常见数据结构 u List子体系 第1章 集合&迭代器 1.1 集合体系结构 1.1 ...
- BAT面试必备——Java 集合类
本文首发于我的个人博客:尾尾部落 1. Iterator接口 Iterator接口,这是一个用于遍历集合中元素的接口,主要包含hashNext(),next(),remove()三种方法.它的一个子接 ...
- 集合之四:List接口
查阅API,看List的介绍.有序的 collection(也称为序列).此接口的用户可以对列表中每个元素的插入位置进行精确地控制.用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的 ...
随机推荐
- log4j MDC NDC详解
NDC ( Nested Diagnostic Context )和 MDC ( Mapped Diagnostic Context )是 log4j 种非常有用的两个类,它们用于存储应用程序的上下文 ...
- Simple Math Problems
整理下<算法笔记>,方便查看. 一.最大公约数&最小公倍数 欧几里得定理:设a,b均为正整数,那么gcd(a,b)=gcd(b,a%b). 若,定理就先交换a和b. 注意:0和任意 ...
- 《C程序设计语言》 练习1-21
问题描述 编写程序entab,将空格串替换为最少数量的制表符和空格,但要保持单词之间的间隔不变.假设制表符终止位的位置与练习1 - 20的detab程序的情况相同.当使用一个制表符或者一个空格都可以到 ...
- [bzoj1924]P2403 [SDOI2010]所驼门王的宝藏
tarjan+DAG 上的 dp 难点在于建图和连边,其实也不难,就是细节挺恶心 我和正解对拍拍出来 3 个错误... 传送门:luogu bzoj 题目描述 有座宫殿呈矩阵状,由 \(R\times ...
- Jmeter 插件图表分析
1.jp@gc - Actiive Threads Over Time:不同时间的活动用户数量展示(图表) 当前的时间间隔是1毫秒,在 setting 中可以设置时间间隔以及其他的参数,右击可以导出 ...
- Git 上传本地项目到远程仓库 (工具篇)
前言:前面一开始写了一篇通过命令来操作本地项目上传远程仓库的文章,后来发现此方式没有那么灵活.故跟开发同事请教了下,知道了通过工具来操作更方便.所以写了这篇文章来分享&记录. 前提条件:本地安 ...
- checked 完整版全选,单选,反选
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <link rel= ...
- flink系列-10、flink保证数据的一致性
本文摘自书籍<Flink基础教程> 一.一致性的三种级别 当在分布式系统中引入状态时,自然也引入了一致性问题.一致性实际上是“正确性级别”的另一种说法,即在成功处理故障并恢复之后得到的结果 ...
- (2).mybatis单元测试(junit测试)
一.Junit使用步骤:1.创建测试目录,(src.测试目录是test)2.在测试目录test中创建与src中相同的包名3.为需要测试的类创建测试类,例如:UsersMapper,测试类是UsersM ...
- java读源码 之 map源码分析(HashMap)二
在上篇文章中,我已经向大家介绍了HashMap的一些基础结构,相信看过文章的同学们,应该对其有一个大致了了解了,这篇文章我们继续探究它的一些内部机制,包括构造函数,字段等等~ 字段分析: // 默 ...