【tensorflow2.0】处理时间序列数据
国内的新冠肺炎疫情从发现至今已经持续3个多月了,这场起源于吃野味的灾难给大家的生活造成了诸多方面的影响。
有的同学是收入上的,有的同学是感情上的,有的同学是心理上的,还有的同学是体重上的。
那么国内的新冠肺炎疫情何时结束呢?什么时候我们才可以重获自由呢?
本篇文章将利用TensorFlow2.0建立时间序列RNN模型,对国内的新冠肺炎疫情结束时间进行预测。
一,准备数据
本文的数据集取自tushare,获取该数据集的方法参考了以下文章。
https://zhuanlan.zhihu.com/p/109556102
首先看下数据是什么样子的:
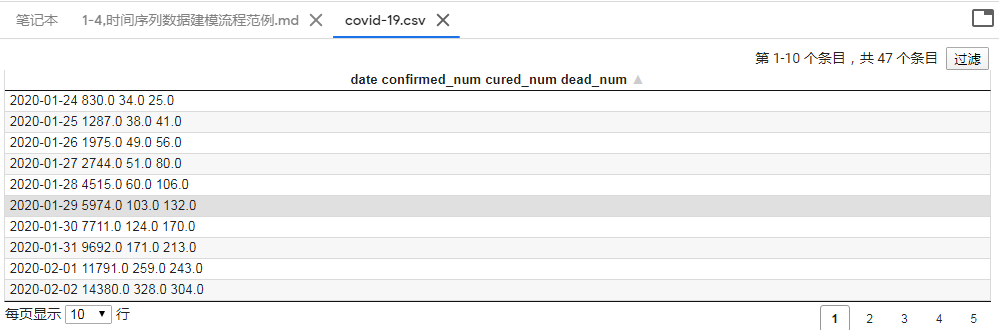
有时间、确诊人数、治愈人数、死亡人数这些列。
然后是创建数据集:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras import models,layers,losses,metrics,callbacks %matplotlib inline
%config InlineBackend.figure_format = 'svg' df = pd.read_csv("./data/covid-19.csv",sep = "\t")
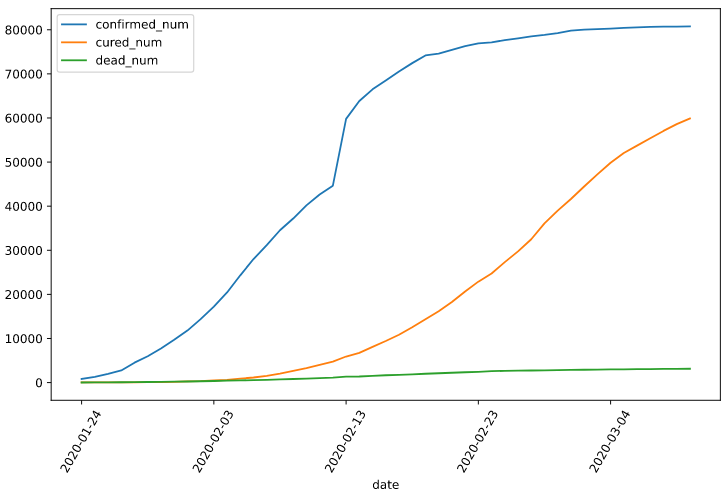
df.plot(x = "date",y = ["confirmed_num","cured_num","dead_num"],figsize=(10,6))
plt.xticks(rotation=60) dfdata = df.set_index("date")
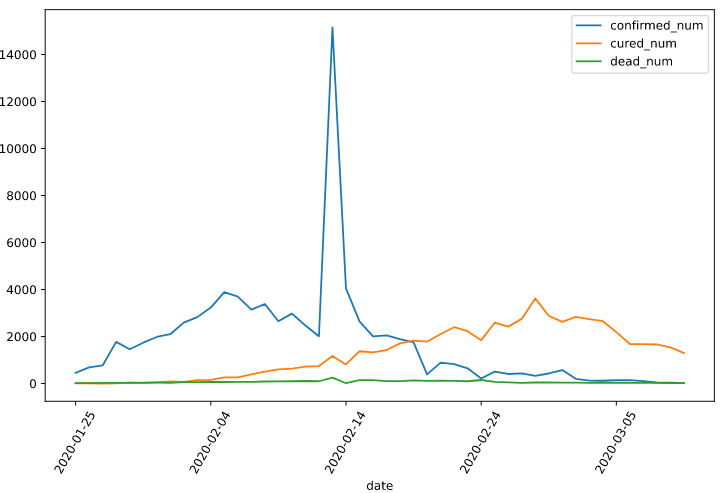
dfdiff = dfdata.diff(periods=1).dropna()
dfdiff = dfdiff.reset_index("date") dfdiff.plot(x = "date",y = ["confirmed_num","cured_num","dead_num"],figsize=(10,6))
plt.xticks(rotation=60)
dfdiff = dfdiff.drop("date",axis = 1).astype("float32") # 用某日前8天窗口数据作为输入预测该日数据
WINDOW_SIZE = 8 def batch_dataset(dataset):
dataset_batched = dataset.batch(WINDOW_SIZE,drop_remainder=True)
return dataset_batched ds_data = tf.data.Dataset.from_tensor_slices(tf.constant(dfdiff.values,dtype = tf.float32)) \
.window(WINDOW_SIZE,shift=1).flat_map(batch_dataset) ds_label = tf.data.Dataset.from_tensor_slices(
tf.constant(dfdiff.values[WINDOW_SIZE:],dtype = tf.float32)) # 数据较小,可以将全部训练数据放入到一个batch中,提升性能
ds_train = tf.data.Dataset.zip((ds_data,ds_label)).batch(38).cache()
二,定义模型
使用Keras接口有以下3种方式构建模型:使用Sequential按层顺序构建模型,使用函数式API构建任意结构模型,继承Model基类构建自定义模型。
此处选择使用函数式API构建任意结构模型。
# 考虑到新增确诊,新增治愈,新增死亡人数数据不可能小于0,设计如下结构
class Block(layers.Layer):
def __init__(self, **kwargs):
super(Block, self).__init__(**kwargs) def call(self, x_input,x):
x_out = tf.maximum((1+x)*x_input[:,-1,:],0.0)
return x_out def get_config(self):
config = super(Block, self).get_config()
return config tf.keras.backend.clear_session()
x_input = layers.Input(shape = (None,3),dtype = tf.float32)
x = layers.LSTM(3,return_sequences = True,input_shape=(None,3))(x_input)
x = layers.LSTM(3,return_sequences = True,input_shape=(None,3))(x)
x = layers.LSTM(3,return_sequences = True,input_shape=(None,3))(x)
x = layers.LSTM(3,input_shape=(None,3))(x)
x = layers.Dense(3)(x) # 考虑到新增确诊,新增治愈,新增死亡人数数据不可能小于0,设计如下结构
# x = tf.maximum((1+x)*x_input[:,-1,:],0.0)
x = Block()(x_input,x)
model = models.Model(inputs = [x_input],outputs = [x])
model.summary()

三,训练模型
训练模型通常有3种方法,内置fit方法,内置train_on_batch方法,以及自定义训练循环。此处我们选择最常用也最简单的内置fit方法。
注:循环神经网络调试较为困难,需要设置多个不同的学习率多次尝试,以取得较好的效果。
# 自定义损失函数,考虑平方差和预测目标的比值
class MSPE(losses.Loss):
def call(self,y_true,y_pred):
err_percent = (y_true - y_pred)**2/(tf.maximum(y_true**2,1e-7))
mean_err_percent = tf.reduce_mean(err_percent)
return mean_err_percent def get_config(self):
config = super(MSPE, self).get_config()
return config import datetime optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
model.compile(optimizer=optimizer,loss=MSPE(name = "MSPE")) logdir = "./data/keras_model/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S") tb_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
# 如果loss在100个epoch后没有提升,学习率减半。
lr_callback = tf.keras.callbacks.ReduceLROnPlateau(monitor="loss",factor = 0.5, patience = 100)
# 当loss在200个epoch后没有提升,则提前终止训练。
stop_callback = tf.keras.callbacks.EarlyStopping(monitor = "loss", patience= 200)
callbacks_list = [tb_callback,lr_callback,stop_callback] history = model.fit(ds_train,epochs=500,callbacks = callbacks_list)
部分结果:
......
Epoch 491/500
1/1 [==============================] - 0s 11ms/step - loss: 0.2643 - lr: 0.0050
Epoch 492/500
1/1 [==============================] - 0s 12ms/step - loss: 0.2625 - lr: 0.0050
Epoch 493/500
1/1 [==============================] - 0s 12ms/step - loss: 0.2628 - lr: 0.0050
Epoch 494/500
1/1 [==============================] - 0s 11ms/step - loss: 0.2633 - lr: 0.0050
Epoch 495/500
1/1 [==============================] - 0s 12ms/step - loss: 0.2619 - lr: 0.0050
Epoch 496/500
1/1 [==============================] - 0s 11ms/step - loss: 0.2627 - lr: 0.0050
Epoch 497/500
1/1 [==============================] - 0s 11ms/step - loss: 0.2622 - lr: 0.0050
Epoch 498/500
1/1 [==============================] - 0s 12ms/step - loss: 0.2618 - lr: 0.0050
Epoch 499/500
1/1 [==============================] - 0s 12ms/step - loss: 0.2624 - lr: 0.0050
Epoch 500/500
1/1 [==============================] - 0s 12ms/step - loss: 0.2616 - lr: 0.0050
四,评估模型
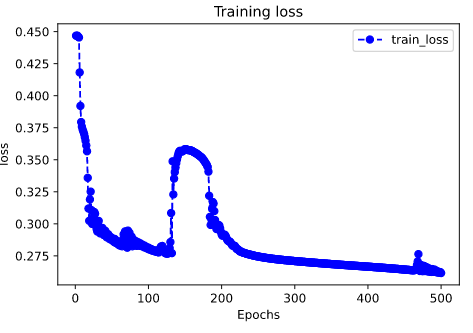
评估模型一般要设置验证集或者测试集,由于此例数据较少,我们仅仅可视化损失函数在训练集上的迭代情况。
%matplotlib inline
%config InlineBackend.figure_format = 'svg' import matplotlib.pyplot as plt def plot_metric(history, metric):
train_metrics = history.history[metric]
epochs = range(1, len(train_metrics) + 1)
plt.plot(epochs, train_metrics, 'bo--')
plt.title('Training '+ metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_"+metric])
plt.show() plot_metric(history,"loss")
五,使用模型
此处我们使用模型预测疫情结束时间,即 新增确诊病例为0 的时间。
# 使用dfresult记录现有数据以及此后预测的疫情数据
dfresult = dfdiff[["confirmed_num","cured_num","dead_num"]].copy()
dfresult.tail()
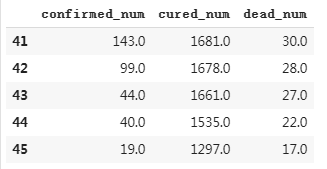
# 预测此后100天的新增走势,将其结果添加到dfresult中
for i in range(100):
arr_predict = model.predict(tf.constant(tf.expand_dims(dfresult.values[-38:,:],axis = 0))) dfpredict = pd.DataFrame(tf.cast(tf.floor(arr_predict),tf.float32).numpy(),
columns = dfresult.columns)
dfresult = dfresult.append(dfpredict,ignore_index=True)
dfresult.query("confirmed_num==0").head()
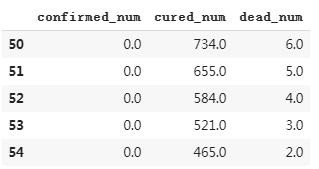
# 第55天开始新增确诊降为0,第45天对应3月10日,也就是10天后,即预计3月20日新增确诊降为0
# 注:该预测偏乐观
dfresult.query("cured_num==0").head()
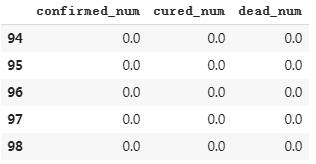
# 第164天开始新增治愈降为0,第45天对应3月10日,也就是大概4个月后,即7月10日左右全部治愈。
# 注: 该预测偏悲观,并且存在问题,如果将每天新增治愈人数加起来,将超过累计确诊人数。
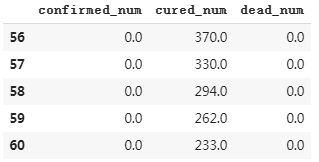
dfresult.query("dead_num==0").head()
# 第60天开始,新增死亡降为0,第45天对应3月10日,也就是大概15天后,即20200325
# 该预测较为合理
六,保存模型
推荐使用TensorFlow原生方式保存模型。
model.save('./data/tf_model_savedmodel', save_format="tf")
print('export saved model.')
model_loaded = tf.keras.models.load_model('./data/tf_model_savedmodel',compile=False)
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
model_loaded.compile(optimizer=optimizer,loss=MSPE(name = "MSPE"))
model_loaded.predict(ds_train)
参考:
开源电子书地址:https://lyhue1991.github.io/eat_tensorflow2_in_30_days/
GitHub 项目地址:https://github.com/lyhue1991/eat_tensorflow2_in_30_days
【tensorflow2.0】处理时间序列数据的更多相关文章
- 【tensorflow2.0】处理图片数据-cifar2分类
1.准备数据 cifar2数据集为cifar10数据集的子集,只包括前两种类别airplane和automobile. 训练集有airplane和automobile图片各5000张,测试集有airp ...
- geotrellis使用(二十三)动态加载时间序列数据
目录 前言 实现方法 总结 一.前言 今天要介绍的绝对是华丽的干货.比如我们从互联网上下载到了一系列(每天或者月平均等)的MODIS数据,我们怎么能够对比同一区域不同时间的数据情况,采用 ...
- mysql 生成时间序列数据 - 存储过程
由于时间自动转换为int值, 做一步转化,也可在调用时处理 use `test`; CREATE table test.test1 as SELECT state, id, `规格条码`, `色号条码 ...
- 基于tensorflow2.0 使用tf.keras实现Fashion MNIST
本次使用的是2.0测试版,正式版估计会很快就上线了 tf2好像更新了蛮多东西 虽然教程不多 还是找了个试试 的确简单不少,但是还是比较喜欢现在这种写法 老样子先导入库 import tensorflo ...
- 006使用Grafana展示时间序列数据
简介 Grafana是一个独立运行的系统,内置了Web服务器.它可以基于仪表盘的方式来展示.分析时间序列数据. Grafana支持多种数据源,例如:Graphite.OpenTSDB.InfluxDB ...
- 时间序列挖掘-预测算法-三次指数平滑法(Holt-Winters)——三次指数平滑算法可以很好的保存时间序列数据的趋势和季节性信息
from:http://www.cnblogs.com/kemaswill/archive/2013/04/01/2993583.html 在时间序列中,我们需要基于该时间序列当前已有的数据来预测其在 ...
- 大数据DDos检测——DDos攻击本质上是时间序列数据,t+1时刻的数据特点和t时刻强相关,因此用HMM或者CRF来做检测是必然! 和一个句子的分词算法CRF没有区别!
DDos攻击本质上是时间序列数据,t+1时刻的数据特点和t时刻强相关,因此用HMM或者CRF来做检测是必然!——和一个句子的分词算法CRF没有区别!注:传统DDos检测直接基于IP数据发送流量来识别, ...
- Google工程师亲授 Tensorflow2.0-入门到进阶
第1章 Tensorfow简介与环境搭建 本门课程的入门章节,简要介绍了tensorflow是什么,详细介绍了Tensorflow历史版本变迁以及tensorflow的架构和强大特性.并在Tensor ...
- TensorFlow2.0(1):基本数据结构—张量
1 引言 TensorFlow2.0版本已经发布,虽然不是正式版,但预览版都发布了,正式版还会远吗?相比于1.X,2.0版的TensorFlow修改的不是一点半点,这些修改极大的弥补了1.X版本的反人 ...
随机推荐
- 基于SpringCloud搭建项目-Zuul篇(六)
本文主要介绍zuul的基本原理和在sprngcloud服务下如何使用 一.简单介绍 Zuul 是 Netflix OSS 中的一员,是一个基于 JVM 路由和服务端的负载均衡器.提供路由.监控.弹性. ...
- 第一篇:解析Linux是什么?能干什么?它的应用领域!
不得不说的前言(不看完睡觉会尿床):饿货们~!你说你们上学都学了点啥?这不懂那也不懂,快毕业了啥也不会.专业课程不学好毕业了也找不到好工作.爸妈给你养大,投资了多少钱.你毕业后随便找了个什么鸡毛工作开 ...
- POJ 1879
栈和队列的综合应用,利用栈和队列分别模拟分,5分,时槽,以及小球队列 利用求出一天后的置换可以求出周期,进而求出最大公约数(可以利用矩阵的角度,也许可以简化,因为每次都是乘上一个相同的置换矩阵) 要注 ...
- PPP协议(简述)
PPP协议(链路层协议):用于点对点信道.互联网用户通常需要连接到某个ISP(运营商)之后才能接入到互联网,PPP协议是用户计算机和ISP(运营商)进行通信时所使用的数据链路层协议.该协议可支持同一时 ...
- go例子(二) 使用go语言实现数独游戏
例子托管于github example.go package main import ( "./sudoku" ) func main() { //var smap ...
- Android NDK JNI 入门笔记-day04-NDK实现Hash算法
* Android NDK JNI 入门笔记目录 * 开头 前面的学习,我们已经掌握了 NDK 开发的必备知识. 下一步就要多实践,通过创造问题并解决问题,来增加熟练度,提升经验. 日常开发中,经常会 ...
- Elasticsearch 之聚合分析入门
本文主要介绍 Elasticsearch 的聚合功能,介绍什么是 Bucket 和 Metric 聚合,以及如何实现嵌套的聚合. 首先来看下聚合(Aggregation): 什么是 Aggregati ...
- .NET 5 Preview 1的深度解读和跟进
这几天微软.NET 团队发布了.NET 5 Preview-1, 如约而至.很兴奋,因为.NET Core和.NET Framework终于实现了大一统,同时也很期待,期待.NET 5能给我们带来哪些 ...
- Python3之turtle的基本用法#Python学习01#
一.turtle基本语法 1.导入turtle 模块import turtle 2.显示箭头turtle.showturtle() 3.写字符串turtle.write("因小米" ...
- ketika aku 病毒
#客户中了该病毒,本想找病毒样本来看看,可是没找到样本,发现中这个病毒的案例还是相对较少: #国内好像没有对于该病毒没有比较详尽的病毒信息,特此写一下方便后者: #中招表现:目前所能够发现的是能够对浏 ...