Flink集群模式部署及案例执行
一.软件要求
Flink在所有类UNIX的环境【例如linux,mac os x和cygwin】上运行,并期望集群由一个 主节点和一个或多个工作节点组成。在开始设置系统之前,确保在每个节点上都安装了一下软件:
1.Java1.8.x或更高版本
2.ssh,必须运行sshd才能使用管理远程组件的Flink脚本
在所有集群节点上都具有免密码的ssh和相同的目录结构,将使你可以使用flink脚本来控制所有内容。
二.Flink Standalone模式设置
1.下载
前往Flink官网下载最新版Flink【我下载的是flink-1.8.2】。若要在Hadoop上使用Flink,则需要下载与Hadoop匹配的版本。下载完成后,上传到几个各个节点并解压
2.配置Flink
通过编辑conf/flink-conf.yaml来为集群配置flink。设置jobmanager.rpc.address以指定flink主节点。还可以通过设置jobmanager.heap.size和taskmanager.heap.size来指定允许JVM在每个节点上分配的最大内存。这些值都是以MB为单位,如果某些工作程序节点有更多的内存分配给Flink集群,则可以通过FLINK_TM_HEAP在那些特定节点上设置环境变量来覆盖默认值。最后,必须提供集群中所有节点的列表,这些列表将用作工作节点。因此,类似于HDFS配置,编辑文件conf/slaves并输入每个子节点的IP/主机名。每个子节点都将运行TaskManager。
以下示例说明了具有三个节点(IP地址从10.0.0.1到10.0.0.3且主机名分别为master,worker1,worker2)的设置,并显示了配置文件的内容:

具体配置如下:
jobmanager.rpc.address:192.168.136.7 # 在每个节点上分别指定各自节点的IP/主机名
taskmanager.tmp.dirs: /usr/local/soft/flink-1.8.2/tmp # 指定每个taskmanager的临时目录
jobmanager.rpc.port:
jobmanager.heap.size: 1024m
taskmanager.heap.size: 1024m
taskmanager.numberOfTaskSlots:
parallelism.default:
解释如下:
1.jobmanager.heap.size:每个JobManager的可用内存大小,默认为1024M
2.taskmanager.heap.size:每个TaskManager的可用内存大小,默认为1024M
3.taskmanager.numberOfTaskSlots:每台计算机可用的CPU数,默认为1
4.parallelism.default:集群中的CPU总数之和
5.io.tmp.dirs:临时目录
3.配置slaves

4.配置环境变量

5.启动flink
执行bin/start-cluster.sh启动JobManager,并通过SSH连接到slaves文件中列出的所有工作节点,以在每个节点上启动TaskManager。

6.Web UI
打开浏览器,输入:http://master:8081 
配置成功!
三.本地执行WordCount
1.代码
package cn.demo import org.apache.flink.api.common.operators.Order
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.api.scala._ //必须导入 /**
* Created by Administrator on 2020/1/22.
*/
object WordCount {
def main(args: Array[String]) {
val params : ParameterTool = ParameterTool.fromArgs(args) // 设置execution执行环境
val execution = ExecutionEnvironment.getExecutionEnvironment // 设置web界面有效参数
execution.getConfig.setGlobalJobParameters(params) val text = execution.fromElements("Apache Flink is an open source platform for distributed stream and batch data processing.",
"Flink core is a streaming dataflow engine that provides data distribution, communication, and fault tolerance for distributed computations over data streams. ",
"Flink builds batch processing on top of the streaming engine, overlaying native iteration support, managed memory, and program optimization.") val counts = text.flatMap(_.toLowerCase.split(" ").filter(_.nonEmpty))
.map((_, 1))
.groupBy(0)//根据第一个元素分组
.sum(1)
.sortPartition(0, Order.ASCENDING) //按照分区进行排序
.first(6) counts.print()
}
}
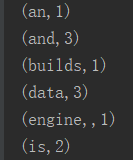
2.本地执行结果
四.案例执行
要运行Flink案例,必须有一个正在运行的Flink实例。最简单的方法是运行./bin/start-cluster.sh,默认情况下会启动一个带有JobManager和一个TaskManager的本地集群。每个Flink二进制发行版都包含一个examples目录,其中包含WordCount这个最常用案例。
要运行WordCount案例,执行以下命令:
./bin/flink run ./examples/batch/WordCount.jar --input /data/flink/wordcount --output /data/flink/wcresult
备注:input路径要提前创建好,其中保存要计算的数据!

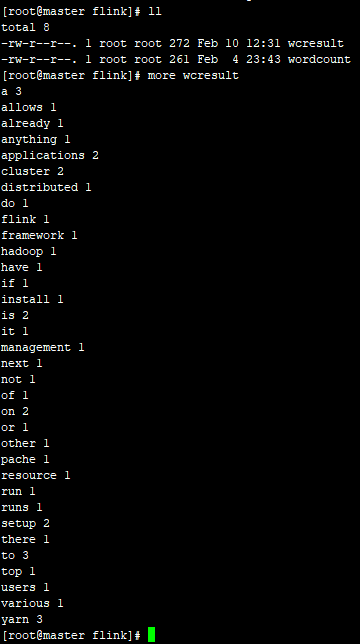
执行结果:
Flink集群模式部署及案例执行的更多相关文章
- 第06讲:Flink 集群安装部署和 HA 配置
Flink系列文章 第01讲:Flink 的应用场景和架构模型 第02讲:Flink 入门程序 WordCount 和 SQL 实现 第03讲:Flink 的编程模型与其他框架比较 第04讲:Flin ...
- Redis集群模式部署
以下以Linux(CentOS)系统为例 1.1 下载和编译 $ wget http://download.redis.io/releases/redis-4.0.7.tar.gz $ tar xzf ...
- zookeeper集群&伪集群模式部署
1.什么是单机部署 一台服务器上面部署一个单机版本的zookeeper服务,用于提供服务. 2.什么是集群部署? 集群部署就是多台服务器上面各部署单独的一个zookeeper服务,然后组建一个集群 3 ...
- flink集群模式安装配置
一.手动下载安装包 wget http://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.6.1/flink-1.6.1-bin-hadoop27 ...
- Kafka集群模式部署
环境:kafka 0.8.1.1 基本概念 Kafka维护按类区分的消息,称为主题(topic) 生产者(producer)向kafka的主题发布消息 消费者(consumer)向主题注册,并且接收发 ...
- ELK集群模式部署
架构拓扑图为: 准备工作: 下载资源包: Elasticsearch: wget https://artifacts.elastic.co/downloads/elasticsearch/elasti ...
- bigdata_ Kafka集群模式部署
环境:kafka 0.8.1.1 基本概念 Kafka维护按类区分的消息,称为主题(topic) 生产者(producer)向kafka的主题发布消息 消费者(consumer)向主题注册,并且接收发 ...
- flink部署操作-flink standalone集群安装部署
flink集群安装部署 standalone集群模式 必须依赖 必须的软件 JAVA_HOME配置 flink安装 配置flink 启动flink 添加Jobmanager/taskmanager 实 ...
- Solr系列二:solr-部署详解(solr两种部署模式介绍、独立服务器模式详解、SolrCloud分布式集群模式详解)
一.solr两种部署模式介绍 Standalone Server 独立服务器模式:适用于数据规模不大的场景 SolrCloud 分布式集群模式:适用于数据规模大,高可靠.高可用.高并发的场景 二.独 ...
随机推荐
- ROS-5 : 自定义消息
自定义消息一般存储在功能包的msg文件夹下的.msg文件中,这些定义可告诉ROS这些数据的类型和名称,以便于在ROS 节点中使用.添加完这些自定义消息后,ROS会将其转为等效的C++节点,从而可在其他 ...
- Lesson 45 Of men and galaxies
In man's early days, competition with other creatures must have been critical. But this phase of our ...
- Windows驱动开发-r3和r0通信
用户部分代码: int main() { HANDLE hDevice = CreateFile(L, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL ...
- GNS3 模拟icmp重定向
网关实质上是一个网络通向其他网络的IP地址.比如有网络A和网络B,网络A的IP地址范围为“192.168.1.1~192. 168.1.254”,子网掩码为255.255.255.0:网络B的IP地址 ...
- XV6源代码阅读-同步机制
Exercise1 源代码阅读 锁部分:spinlock.h/spinlock.c以及相关其他文件代码 // Mutual exclusion lock. struct spinlock { uint ...
- 041、Java中逻辑运算之普通或运算“|”
01.代码如下: package TIANPAN; /** * 此处为文档注释 * * @author 田攀 微信382477247 */ public class TestDemo { public ...
- Python 日志模块详解
前言 我们知道查看日志是开发人员日常获取信息.排查异常.发现问题的最好途径,日志记录中通常会标记有异常产生的原因.发生时间.具体错误行数等信息,这极大的节省了我们的排查时间,无形中提高了编码效率.所以 ...
- 10 MySQL索引选择与使用
索引概述 每种存储引擎对每个表至少支持16个索引,总索引长度至少256字节. MyISAM和InnoDB的表默认创建BTREE索引.MEMORY引擎默认使用HASH索引,但也支持BTR ...
- ArcoLinux安装完成后的的配置
ArcoLinux安装完成后的的配置 这可能是全网第一篇Arcolinux的教程 1. 更改源 修改/etc/pacman.d/mirrorlist 在最头上增加清华源 Server = https: ...
- 验证试验 更改了从机CAN通信的MAC地址 从机新挂CAN网络 上电自检通过
更改前 该之后 主机程序 与 从机 程序 已经上传到网盘上 ,主机和从机程序基本一致, 唯一的区别是 从机更好了MAC地址 为0X10 主机的固定MAC地址为 0X1F 改程序的配置上设置的是双滤波 ...