DDD之4聚合和聚合根

聚合就是归类的意思,把同类事物统一处理;
聚合根也就是最抽象,最普遍的特性;
背景
领域建模的过程回顾:
那么问题来了?
为什么要在限界上下文和实体之间增加聚合和聚合根的概念,即作用是什么?
如何设计聚合?
按照一般的研究和学习思路,先弄懂概念,然后结合实际例子理解概念,然后再回答提出的问题。
聚合根
聚合根:如果把聚合比作组织,聚合根则是组织的负责人,聚合根也叫做根实体,它不仅仅是实体,还是实体的管理者;
职责:
1,作为实体,具备自己的业务属性,业务行为,业务逻辑
2,作为聚合的管理者,
在聚合内部,负责协调实体和值对象按照固定的业务规则协同完成共同的业务逻辑;
在聚合之间:它是聚合对外的接口人,以聚合根ID的方式接受外部请求和任务,实现上下文中的聚合之间的业务协同;
聚合之间通过聚合根关联引用,如果需要访问其他聚合的实体,先访问聚合根,再导航到聚合内部的实体;即外部对象不能直接访问聚合内的实体;
解决的问题: 复杂数据模型缺少统一的业务规则控制而导致的聚合,实体之间数据不一致的问题;
| 数据处理方式 | 问题 |
|---|---|
| 传统:实体个数据模型一一对应, | 任由实体无控制的修改数据,容易导致实体之间数据逻辑不一致的问题; |
加锁增加了软件复杂度和降低系统性能;
|
聚合
在DDD中,实体和值对象都是很基础的领域对象。
聚合是什么呢?类比一下:
| DDD的概念 | 人类 |
|---|---|
| 实体,值对象 | 人 |
| 聚合 | 社团,组织,部门 |
| 聚合的好处: | |
| 让实体和值对象协同工作的组织就是聚合,用来确保这些领域对象在实现公共的业务逻辑的时候,可以保持数据的一致性 | 个人是组织的一员,协同工作,有共同目标,可以发挥出更大的力量 |
聚合的另一种视图: 聚合是业务和逻辑紧密关联的实体和值对象组合而成,聚合是数据修改和持久化的基本单元,一个聚合对应一个数据的持久化;
聚合在DDD分层架构中属于领域层,领域层包含了多个聚合,共同实现核心业务逻辑,聚合内的实体以充血模型实现个体业务能力,以及业务逻辑的高内聚;
跨多个实体的业务逻辑通过领域服务来实现,跨多个聚合的业务逻辑通过应用服务来实现;
| 跨越场景 | 处理办法 |
|---|---|
| 业务场景需要一个聚合中的A实体和B实体共同完成 | 业务逻辑用领域服务来实现; |
| 业务逻辑需要聚合C和聚合D共同完成 | 应用服务来组合这两个服务; |
聚合的组成:
| 组成部分 | 说明 |
|---|---|
| 上下文边界 | 边界是根据业务单一职责和高内聚原则,定义了聚合内部应该包含哪些实体和值对象 |
| 聚合之间的边界是松耦合的; | |
| 聚合根 | 见下面的介绍 |
如何设计聚合?
例子:保单系统聚合的过程。
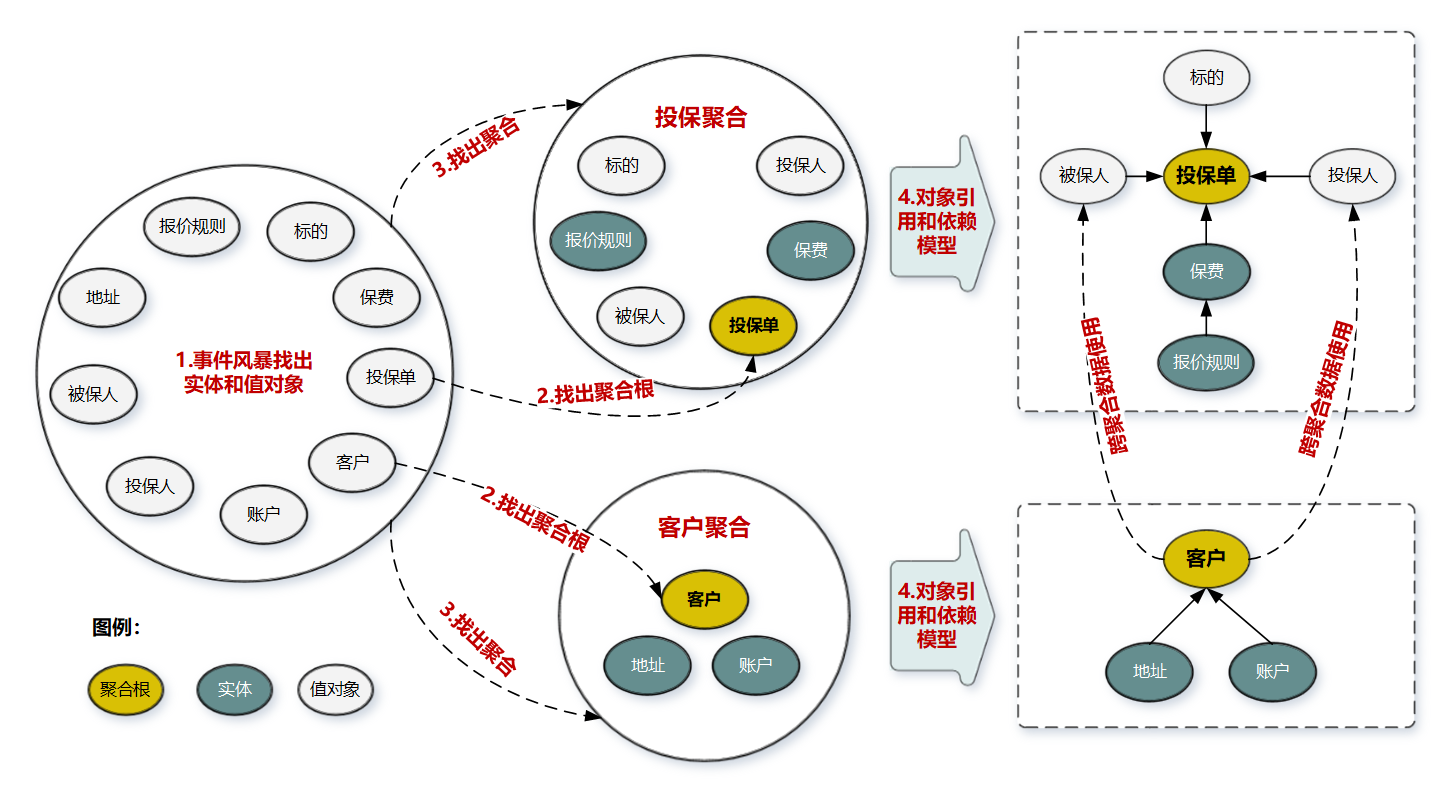
| 步骤 | 说明 |
|---|---|
| 1 | 通过事件风暴的用例分析,场景分析,用户旅程分析得到领域对象(账户,客户,投保单,报废,标的,报价规则,地址,投保人,被保人) |
| 2 | 从领域对象中找出适合作为实体管理者的对象(聚合根),[是否具备唯一标识,能管理其他的实体]-》(投保,客户) |
| 3 | 按照业务的职责单一和高内聚原则,找出聚合根紧密关联的实体和值对象,构建以聚合根为中心的集合,即得到聚合;-》(投保聚合,客户聚合) |
| 4 | 在聚合内部画出聚合根跟实体和值对象的引用和依赖关系图-》(客户依赖地址和账户) |
| 5 | 多个聚合根据业务语义,和上下文划在同一个限界上下文中 |
聚合的设计原则:
| 原则 | 说明 |
|---|---|
| 聚合设计的尽量小 | 如果聚合设计的过大,内部还有大量的实体和值对象,管理会比较复杂,高频操作会有并发和数据库锁冲突的问题,导致系统可用性降低; 聚合设计的足够小,也就降低了复杂度,可复用性也更高,降低了后期重构复杂聚合的成本; |
| 聚合应该高内聚 | 封装的是真正的不变的领域对象,内部的实体和值对象按照固定的规则运行,实现数据的一致性,边界外的任何东西都于该聚合无关, |
| 通过唯一标识符引用其它聚合 | 聚合之间通过聚合根的唯一ID来关联,而不是直接对象引用的方式,外部的聚合对象如果在本聚合范围内管理,容易导致边界不清晰,增加聚合之间的耦合度; |
| 边界之外使用最终一致性 | 聚合内部数据强一致性,聚合之间数据最终一致性,在一次事务中最多只修改一个聚合的数据状态,如果在一次事务中涉及修改多个聚合的状态,应该使用领域事件的方式来异步的实现最终一致性,实现聚合之间的解耦; |
| 在应用层实现跨聚合的调用 | 实现微服务内部聚合之间的解耦,以为为未来以聚合为单位的拆分和组合,应该避免跨聚合的的领域服务调用和数据表关联; |
小结
聚合的特点:高内聚低耦合,是领域模型中最底层的边界,可以作为拆分微服务的最小单位,但是不建议单独对应一个微服务,除非是对性能有极致要求的场景,一个微服务可以包含多个聚合,聚合之间的边界是逻辑最天然的边界,有了这个逻辑边界,就可以在微服务拆分的时候作为拆分和组合依据,微服务架构演进也就不是难事了。
聚合根的特点:聚合根是实体,具备唯一标识,有独立的生命周期,一个聚合只有一个聚合根,聚合根在聚合之内采用引用依赖的方式对实体和值对象进行组织和协调,聚合根和聚合根之间通过唯一id进行聚合之间的协同;
实体的特点:具备id标识,可以通过id进行相等性比较,实体在聚合内唯一,但是状态可变,它依附于聚合根,它的生命周期由聚合根管理,实体一般都会持久化,跟数据持久化对象存在多种对应关系(一对一,一对多,多对一,1对0),实体可以引用聚合中的聚合根,实体,值对象;
值对象特点:无id,不可变,无生命周期,用完即失效,值对象之间通过属性值判断相等性,他的核心是值,是一组概念完整的属性集合,用于描述实体的特征和状态,值对象尽量只引用值对象;
本篇主要介绍了聚合根,聚合的概念,然后介绍了聚合的设计过程和原则,以及对比了聚合,聚合根,实体,值对象的特点。
下面我们来回答最初的两个问题?
为什么要在实体和限界上下文之间增加聚合和聚合根,作用是什么?
在实体和限界上下文之间增加聚合和聚合根之间的原因是:让实体和值对象协同工作,在实现公共业务逻辑的时候,可以保证数据的一致性;
如何设计聚合?
过程是:通过事件风暴(用例分析,场景分析,用户旅程分析)得到实体和值对象,然后找出聚合根,按照高内聚低耦合的设计原则,找出跟聚合根紧密关联的实体和值对象,即形成聚合,并画出聚合内的实体和值对象的引用依赖关系,最后把业务把关联紧密的聚合画在同一个限界上线文中,即完成了领域建模;
聚合的设计原则: 高内聚,聚合尽量小,聚合之间通过id关联,边界之外使用最终一致性,在应用层实现跨聚合的调用。
希望大家可以得到相对完整(高内聚低耦合)的业务领域模型;
原创不易,关注诚可贵,转发价更高!转载请注明出处,让我们互通有无,共同进步,欢迎沟通交流。
我会持续分享Java软件编程知识和程序员发展职业之路,欢迎关注,我整理了这些年编程学习的各种资源,关注公众号‘李福春持续输出’,发送'学习资料'分享给你!

DDD之4聚合和聚合根的更多相关文章
- 从壹开始微服务 [ DDD ] 之六 ║聚合 与 聚合根 (下)
前言 哈喽大家周二好,上次咱们说到了实体与值对象的简单知识,相信大家也是稍微有些了解,其实实体咱们平时用的很多了,基本可以和数据库表进行联系,只不过值对象可能不是很熟悉,值对象简单来说就是在DDD领域 ...
- DDD中聚合、聚合根的含义以及作用
聚合与聚合根的含义 聚合: 聚合往往是一些实体为了某项业务而聚类在一起形成的集合 , 举个例子, 社会是由一个个的个体组成的,象征着我们每一个人.随着社会的发展,慢慢出现了社团.机构.部门等组织,我们 ...
- ASP.NET Core Web API下事件驱动型架构的实现(四):CQRS架构中聚合与聚合根的实现
在前面两篇文章中,我详细介绍了基本事件系统的实现,包括事件派发和订阅.通过事件处理器执行上下文来解决对象生命周期问题,以及一个基于RabbitMQ的事件总线的实现.接下来对于事件驱动型架构的讨论,就需 ...
- NET Core Web API下事件驱动型架构CQRS架构中聚合与聚合根的实现
NET Core Web API下事件驱动型架构在前面两篇文章中,我详细介绍了基本事件系统的实现,包括事件派发和订阅.通过事件处理器执行上下文来解决对象生命周期问题,以及一个基于RabbitMQ的事件 ...
- 基于ABP落地领域驱动设计-02.聚合和聚合根的最佳实践和原则
目录 前言 聚合 聚合和聚合根原则 包含业务原则 单个单元原则 事务边界原则 可序列化原则 聚合和聚合根最佳实践 只通过ID引用其他聚合 用于 EF Core 和 关系型数据库 保持聚合根足够小 聚合 ...
- [CISCO] 交换机间链路聚合端口聚合
[CISCO] 交换机间链路聚合端口聚合 一.Introduction 端口通道( port channel ) 是一种聚合多个物理接口 ( that ) 创建一个逻辑接口.你可以捆扎( bundle ...
- DDD领域驱动设计之聚合、实体、值对象
关于具体需求,请看前面的博文:DDD领域驱动设计实践篇之如何提取模型,下面是具体的实体.聚合.值对象的代码,不想多说什么是实体.聚合等概念,相信理论的东西大家已经知晓了.本人对DDD表示好奇,没有在真 ...
- DDD-领域驱动(三)-聚合与聚合根
概念 高内聚 , 高内聚合Aggregate 就好比一个功能,各个模块互相是有依赖关系存在,例如: 低耦合:模块可以任意替换,不会影响系统的工作 例如:比如你今天穿了这套衣服,明天穿了另一套衣服,但你 ...
- Elasticsearch聚合优化 | 聚合速度提升5倍
https://blog.csdn.net/laoyang360/article/details/79253294 1.聚合为什么慢?大多数时候对单个字段的聚合查询还是非常快的, 但是当需要同时聚合多 ...
随机推荐
- docker 垃圾回收机制
docker垃圾回收机制 作者: 张首富 时间: 2019-04-10 个人博客: www.zhangshoufu.com QQ群: 895291458 说明 对于Docker来说,存在镜像/容器/存 ...
- Docker之docker log详解
1.显示所有log docker logs [OPTIONS] <CONTAINER> #显示某个容器的所有log docker-compose logs #显示启动的所有容器的lo ...
- python 调用ldap同步密码
windows + python2.7 安装 python-ldap https://www.lfd.uci.edu/~gohlke/pythonlibs/#python-ldap 2.python ...
- 简版在线聊天Websocket
序言 What is Webscoket ? websocket 应用场景 简版群聊实现 代码例子 小结 Webscoket Websokcet 是一种单个TCP连接上进行全双工通信的协议,通过HTT ...
- python 机器学习(二)分类算法-k近邻算法
一.什么是K近邻算法? 定义: 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. 来源: KNN算法最早是由Cover和Hart提 ...
- 十、理解JavaBean
1. 理解Bean 1.JavaBean本身就是一个类,属于Java的面向对象编程. 2.在JSP中如果要应用JSP提供的Javabean的标签来操作简单类的话,则此类必须满足如下的开发要求: (1) ...
- Docker 错误:network xxx id xxxx has active endpoints
问题描述:Docker Compose 部署的项目,使用docker-compose down 命令关闭时,提示错误: Removing network xxxl_default ERROR: net ...
- C# 数据操作系列 - 15 SqlSugar 增删改查详解
0. 前言 继上一篇,以及上上篇,我们对SqlSugar有了一个大概的认识,但是这并不完美,因为那些都是理论知识,无法描述我们工程开发中实际情况.而这一篇,将带领小伙伴们一起试着写一个能在工程中使用的 ...
- jdk8 Collections#sort究竟做了什么
前言 Collections#sort 追踪代码进去看,会调用到Arrays.sort,看到这里时,你肯定会想,这不是很简单,Arrays.sort在元素较少时使用插入排序,较多时使用快速排序,再多时 ...
- NO.4 CCS运行第一个demo(本地)
前面介绍了基本的SDK内容,这次主要是本地实际应用CCS实现程序的运行. 首先我们进入CCS,我简单介绍下界面: 界面很简洁,通俗易懂(怎么跟STM32IDE这么像) 由于我们还不会写程序,我们先导入 ...