Code Walkthroughs Table API
上级:https://www.cnblogs.com/hackerxiaoyon/p/12747387.html
Table API
Table api 有批量的api和流实时的api。通常很容易进行数据分析、批量数据导入 和 做一些数据清洗的工作。
What Will You Be Building? 案例说明
此案例需要构建一个数据清洗的通道用来随时间跟踪金融交易,构建一个夜间的批量作业然后集成到流通道中。
Prerequisites 前提
需要你具备java 或 scala的知识,当然你有其他语言也是可以的,同时这方面也是需要具备一定的sql 的知识。
Help,I’m Stuck! 寻求帮助
如果你卡住了,可以 求助 https://flink.apache.org/gettinghelp.html 。
https://flink.apache.org/community.html#mailing-lists 用户邮件列表是一个活跃快速提供帮助的地方。
How To Follow Along 如何跟进
环境
l Java 8 or 11
l Maven
构建java 程序demo
$ mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-walkthrough-table-java \
-DarchetypeVersion=1.10.0 \
-DgroupId=spend-report \
-DartifactId=spend-report \
-Dversion=0.1 \
-Dpackage=spendreport \
-DinteractiveMode=false
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment tEnv = BatchTableEnvironment.create(env);
tEnv.registerTableSource("transactions", new BoundedTransactionTableSource());
tEnv.registerTableSink("spend_report", new SpendReportTableSink());
tEnv.registerFunction("truncateDateToHour", new TruncateDateToHour());
tEnv.scan("transactions").insertInto("spend_report");
env.execute("Spend Report");
Breaking Down The Code分解一下代码
执行环境
java语言
这是个批量的环境,也就是你在接source的时候,可以是流还是批量。这是批量的Table api方式。
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment tEnv = BatchTableEnvironment.create(env);
Registering Tables
然后我们可以注册一个表方式在执行环境中,同时可以接内部系统读写批流数据。一个表数据源提供把数据写到内部系统中,像:数据库,key-value的存储redis,消息队列,或者是文件系统。基本就是接数据源source,中间业务处理,最后sink落地。
tEnv.registerTableSource("transactions", new BoundedTransactionTableSource());
tEnv.registerTableSink("spend_report", new SpendReportTableSink());
这里我们注册了两个表,一个输入table,一个输出table。 transactions表让我们读取信用卡交易信息,包含账号,交易时间,交易额度。
Registering A UDF
注册一个udf,也就是用户自定义函数。具体TruncateDateToHour代码需要你在构建代码后在你的IDE中查看。
tEnv.registerFunction("truncateDateToHour", new TruncateDateToHour());
The Query
tEnv
.scan("transactions")
.insertInto("spend_report");
查看然后插入没有做其他的操作。
Execute
执行代码
env.execute("Spend Report");
Attempt One 尝试一下
tEnv
.scan("transactions")
.select("accountId, timestamp.truncateDateToHour as timestamp, amount")
.groupBy("accountId, timestamp")
.select("accountId, timestamp, amount.sum as total")
.insertInto("spend_report");
你尝试跑这个代码的时候肯定会报错
Caused by: java.lang.ClassNotFoundException: org.apache.flink.table.api.java.internal.BatchTableEnvironmentImpl
因为没有依赖有冲突,所以查看你的冲突直接把对应的排除就好。直接运行你的代码。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
<exclusions>
<exclusion>
<groupId>org.apache.flink</groupId>
<artifactId>org.apache.flink:flink-table-api-java-*</artifactId>
</exclusion>
</exclusions>
</dependency>
代码结果太长了,我截图简单的看一下。
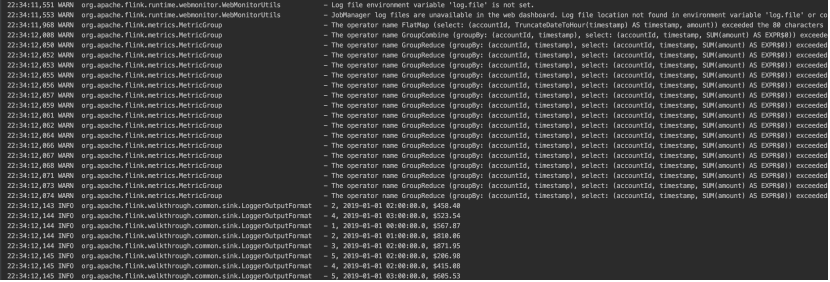
查询表,表中有三个字段,然后我们根据账号,时间分组,计算每个时间段对应的总钱数。然后sink的时候打印出来。
Adding Windows 添加窗口
窗口在我们flink经常使用的一种策略,keyed 窗口,no-keyed窗口。然后有三种指定的窗口类型,之前我记得是三种,分别是:滚动窗口,滑动窗口,会话窗口,全局窗口。等到了窗口的地方我们再细说。执行下面的代码,意思是统计按照时间字段一小时一个窗口进行统计的数据。
tEnv
.scan("transactions")
.window(Tumble.over("1.hour").on("timestamp").as("w"))
.groupBy("accountId, w")
.select("accountId, w.start as timestamp, amount.sum")
.insertInto("spend_report");
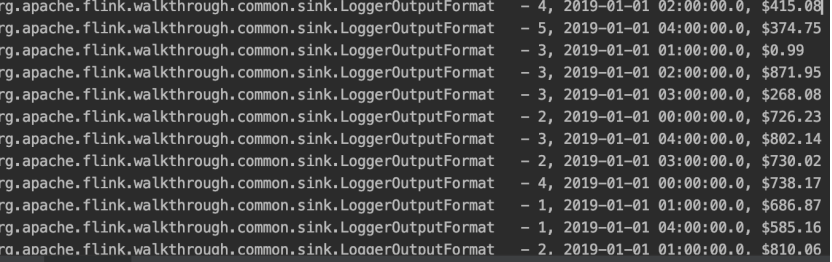
Once More, With Streaming! 再来个流计算
因为table api提供了两种一种batch一种是streaming。我们将环境换成如下就可以了,其他代码不变,直接运行。
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
Code Walkthroughs Table API的更多相关文章
- Code Walkthroughs DataStream API
上级:https://www.cnblogs.com/hackerxiaoyon/p/12747387.html DataStream API DataStreamApi 提供了健壮,有状态的流应用, ...
- 使用flink Table &Sql api来构建批量和流式应用(2)Table API概述
从flink的官方文档,我们知道flink的编程模型分为四层,sql层是最高层的api,Table api是中间层,DataStream/DataSet Api 是核心,stateful Stream ...
- Flink实战(六) - Table API & SQL编程
1 意义 1.1 分层的 APIs & 抽象层次 Flink提供三层API. 每个API在简洁性和表达性之间提供不同的权衡,并针对不同的用例. 而且Flink提供不同级别的抽象来开发流/批处理 ...
- 【翻译】Flink Table Api & SQL — 流概念
本文翻译自官网:Streaming Concepts https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/table/st ...
- Flink Table Api & SQL 翻译目录
Flink 官网 Table Api & SQL 相关文档的翻译终于完成,这里整理一个安装官网目录顺序一样的目录 [翻译]Flink Table Api & SQL —— Overv ...
- 【翻译】Flink Table Api & SQL — 性能调优 — 流式聚合
本文翻译自官网:Streaming Aggregation https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/table ...
- 【翻译】Flink Table Api & SQL — 配置
本文翻译自官网:Configuration https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/table/config.h ...
- 【翻译】Flink Table Api & SQL — Hive —— 在 scala shell 中使用 Hive 连接器
本文翻译自官网:Use Hive connector in scala shell https://ci.apache.org/projects/flink/flink-docs-release-1 ...
- 【翻译】Flink Table Api & SQL — Hive —— Hive 函数
本文翻译自官网:Hive Functions https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/table/hive/h ...
随机推荐
- 小谢第2问:后端返回为数组list时候,怎么实现转为tree
要求后端返回给我的list时候,在数组中定义有id , parentid, 可以用双重循环的方法,得到tree需要的数据结构,这样得到的数据就可以直接复制给树组件的data啦const oldData ...
- 【Socket通信】关于Socket通信原理解析及python实现
Socket(套接字)通信{网络通信其实就是Socket间的通信},首先了解下概念:[来源于百度百科] "两个程序通过一个双向的通信连接实现数据的交换,这个连接的一端称为一个socket.& ...
- for循环的嵌套 函数方法
1.双层for循环:外层循环控制行,内行循环控制列 for循环嵌套例子 用五角星组成一个矩形 // 99乘法表 // for(var i = 1 ;i <= 9 ; i++){ // f ...
- SpringBoot整合Flyway(数据库版本迁移工具)
简介 在团队开发当中,有可能每个人都是使用自己本地的数据库.当数据库的表或者字段更新时,往往需要告知团队的其他同事进行更新. Flyway数据库版本迁移工具,目的就是解决该问题而诞生的(我自己想的). ...
- Java实现 蓝桥杯VIP 算法训练 确定元音字母位置
算法训练 确定元音字母位置 时间限制:1.0s 内存限制:512.0MB 输入一个字符串,编写程序输出该字符串中元音字母的首次出现位置,如果没有元音字母输出0.英语元音字母只有'a'.'e'.'i'. ...
- 第七届蓝桥杯JavaB组省赛真题
解题代码部分来自网友,如果有不对的地方,欢迎各位大佬评论 题目1.煤球数量 煤球数目 有一堆煤球,堆成三角棱锥形.具体: 第一层放1个, 第二层3个(排列成三角形), 第三层6个(排列成三角形), 第 ...
- @Autowired 注解详解
前言 我们平时使用 Spring 时,想要 依赖注入 时使用最多的是 @Autowired 注解了,本文主要讲解 Spring 是如何处理该注解并实现 依赖注入 的功能的. 正文 首先我们看一个测试用 ...
- void out2() const{
include "stdafx.h" include using namespace std; class aa{ int num; public: aa(){ int b =10 ...
- GPIO功能框图
(1)保护二极管 引脚内部加上这两个保护二级管可以防止引脚外部过高或过低的电压输入, 当引脚电压高于 VDD_FT 或 VDD 时,上方的二极管导通吸收这个高电压,当引脚 电压低于 VSS 时,下方的 ...
- [BZOJ]最长道路
题目 点这里看题目. BZOJ 上是权限题目. 分析 这道题可以用点分治,但是我就是喜欢边分治 QAQ . 分治过程中,我们考虑经过分治边的路径的最大痛苦值.一条经过分治边的路径会被 ...