使用Python批量获取学生期末考试成绩
以下是我们学校对于期末考试成绩临时查询的一个网站

我突发奇想,可不可以通过爬虫的方式批量获取成绩信息
于是说干就干
首先观察网页的请求
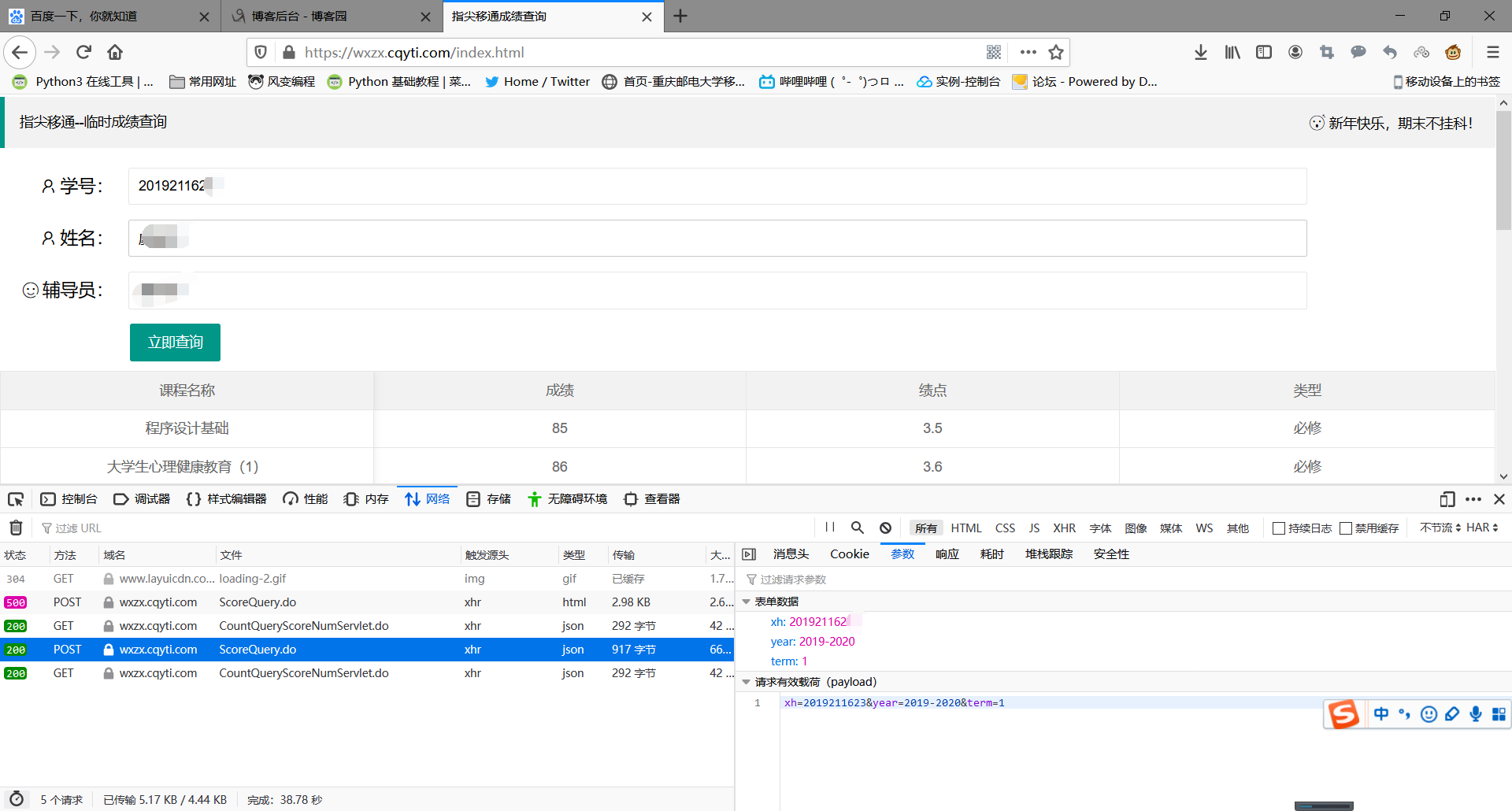
通过查看,我们可以很明显看到网站查询是通过对https://wxzx.cqyti.com/wxProject/ScoreQuery.do进行post请求而来的,令人惊讶的是网页上要填写的姓名和辅导员根本没有post上去
这大大降低了我们爬取数据的难度!!!
我们可以看到,只post了三个数据 分别是
所以我们只需要通过循环生成xh所对应的学号 在带上固定的“year”和“term”即可
首先载入所需要的库
import requests
import re
定义请求的url和伪装请求头
#定义请求的url
url = 'https://wxzx.cqyti.com/wxProject/ScoreQuery.do'
#定义请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0'
}
接下来就是获取数据了
首先我们需要打开一个文本文件用于写入最终的结果
我们定义一个sum来提示我们已经录入了多少
#post的数据
file = open("E:/成绩.txt", "w")
sum = 0 #用于提示总共记录了多少学生
for i in range(2019211600,2019211711):
head = '学号为%d的同学的成绩\n'%(i) #准备好同学的学号用于写入 print (head) #用于提醒正在记录的同学的学号
data = {'xh' : str(i) , 'year' :'2019-2020' , 'term':'' } #定义data 将生成的学号放入 # 发起post请求
res = requests.post(url=url ,headers=headers,data =data)
data_get = res.json()
接下来我们来分析一下所保存的data文件

我们可以很清楚的看到我们所需要的信息就在data_get中的"xskscj”内的 "scorename"与"value"中因此我们可以直接从data_get中切片选取
#写入文本
k = 0 #初始化k的值,用于接下来遍历字典 file.write(head) #将学号写入文本
for ii in data_get['xskscj']: #通过循环遍历字典将成绩和学号写入文本 kecheng = data_get['xskscj'][k]['scorename']
fenshu = data_get['xskscj'][k]['value']
k=k+1
jieguo = kecheng + ':' + str(fenshu)+'分 '
print(jieguo) file.write(jieguo)
file.write('\n')
print('录入成功')
sum= sum + 1 # 用于计算录入的同学总数
print('共计录'+ str(sum) + '名同学')
最后记得关闭文本文件
file.close() #关闭文本文件
最后经过简单的调试就ok啦


使用Python批量获取学生期末考试成绩的更多相关文章
- R语言学习笔记:分析学生的考试成绩
孩子上初中时拿到过全年级一次考试所有科目的考试成绩表,正好可以用于R语言的统计分析学习.为了不泄漏孩子的姓名,就用学号代替了,感兴趣可以下载测试数据进行练习. num class chn math e ...
- Python - 批量获取文件夹的大小输出为文件格式化保存
很多时候,查看一个文件夹下的每个文件大小可以轻易的做到,因为文件后面就是文件尺寸,但是如果需要查看一个文件夹下面所有的文件夹对应的尺寸,就发现需要把鼠标放到对应的文件夹上,稍等片刻才会出结果. 有时候 ...
- 复旦大学2014--2015学年第二学期高等代数II期末考试情况分析
一.期末考试成绩班级前几名 钱列(100).王华(92).李笑尘(92).金羽佳(91).李卓凡(91).包振航(91).董麒麟(90).张钧瑞(90).陆毕晨(90).刘杰(90).黄成晗(90). ...
- 复旦大学2014--2015学年第一学期高等代数I期末考试情况分析
一.期末考试成绩班级前几名 金羽佳(92).包振航(91).陈品翰(91).孙浩然(90).李卓凡(85).张钧瑞(84).郭昱君(84).董麒麟(84).张诚纯(84).叶瑜(84) 二.总成绩计算 ...
- 复旦大学2018--2019学年第一学期高等代数I期末考试情况分析
一.期末考试成绩90分以上的同学(共21人) 周烁星(99).封清(99).叶雨阳(97).周子翔(96).王捷翔(96).张思哲(95).丁思成(94).陈宇杰(94).谢永乐(93).张哲维(93 ...
- 复旦大学2017--2018学年第二学期高等代数II期末考试情况分析
一.期末考试成绩班级前十名 张菲诺(95).刘宇其(95).魏一鸣(93).郭宇城(92).程梓兼(91).葛珈玮(90).汪子怡(90).余张伟(90).张昰昊(89).朱柏青(89) 二.总成绩计 ...
- 复旦大学2017--2018学年第一学期高等代数I期末考试情况分析
一.期末考试成绩班级前十名 郭宇城(100).魏一鸣(93).乔嘉玮(92).刘宇其(90).朱柏青(90).王成文健(90).方博越(88).熊子恺(88).张君格(88).崔镇涛(87).史书珣( ...
- 复旦大学2016--2017学年第二学期高等代数II期末考试情况分析
一.期末考试成绩班级前十五名 林晨(93).朱民哲(92).何陶然(91).徐钰伦(91).吴嘉诚(91).于鸿宝(91).宁盛臻(90).杨锦文(89).占文韬(88).章俊鑫(87).颜匡萱(87 ...
- 复旦大学2018--2019学年第二学期高等代数II期末考试情况分析
一.期末考试成绩班级前十名 丁思成(99).周烁星(97).王捷翔(96).顾文颢(92).顾天翊(90).封清(89).张思哲(89).李哲蔚(88).陈钦品(88).邹年轶(88).王祝斌(88) ...
随机推荐
- Disk Group基础概念与深度解析
- Linux 系统优化参数总结
系统优化参数总结: net.ipv4.tcp_syncookies = 表示开启SYN Cookies.当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击 net.ipv4.t ...
- PP图|QQ图|正态性检验|K-S检验|S-W检验|
应用统计学: 物理条件一致时,有理由认为方差是一致的.配对检验可排除物理影响,使方差变小,但是自由度降低了,即样本数变小.二项分布均值假设检验的模型要依据前面的假设条件: PP图统计图要看中间的贴近情 ...
- vue-cli多页面应用常遇到的问题
1.TypeError: webpack.optimize.OccurenceOrderPlugin is not a constructor 此问题出现在webpack 3中,解决办法很简单,将oc ...
- Python-删除多级目录
def rmdirs(top): for root, dirs, files in os.walk(top, topdown=False): # 先删除文件 for name in files: os ...
- git pull 显示的冲突---解决办法git stash
git pull:显示本地仓库与远程仓库有冲突 Please, commit your changes or stash them before you can merge. Aborting 解决办 ...
- html中的select下拉框
<select name="effective"> <option value="">请选择</option> <op ...
- java 通过数据库名获得 该数据所有的表名以及字段名、字段类型
package com.nf.lc.sql_meta_data; import java.sql.*; import java.util.HashMap; import java.util.Map; ...
- python基础局部变量、全局变量
局部变量的作用域只作用与当前函数块(或代码块)中,对函数块(或代码块)之外的重名变量,没有任何影响. 在函数块(或代码块)中,局部变量可用通过global关键字声明变量来改变在函数块(或代码块)之外对 ...
- 【转载】Scrapy安装及demo测试笔记
Scrapy安装及demo测试笔记 原创 2016年09月01日 16:34:00 标签: scrapy / python Scrapy安装及demo测试笔记 一.环境搭建 1. 安装scrapy ...