实体识别中,或序列标注任务中的维特比Viterbi解码
看懂这个算法,首先要了解序列标注任务 QQ522414928 可以在线交流
大体做一个解释,首先需要4个矩阵,当然这些矩阵是取完np.log后的结果,
分别是:初始strat→第一个字符状态的概率矩阵,转移概率矩阵,发射概率矩阵,最后一个字符状态→end结束的概率矩阵,
这些概率矩阵可以是通过统计得到,或者是LSTM+crf这种训练迭代得到。
zero_log 指的是在统计中发射概率没有的情况下用这个很小的值来代替,lstm+crf中应该不会出现不存在的发射概率。
然后看代码
一个矩阵V:里面保存的是每个时间步上的每个状态对应的概率
一个字典path:里面保存的是 {当前标签:他之前所经过的路径}
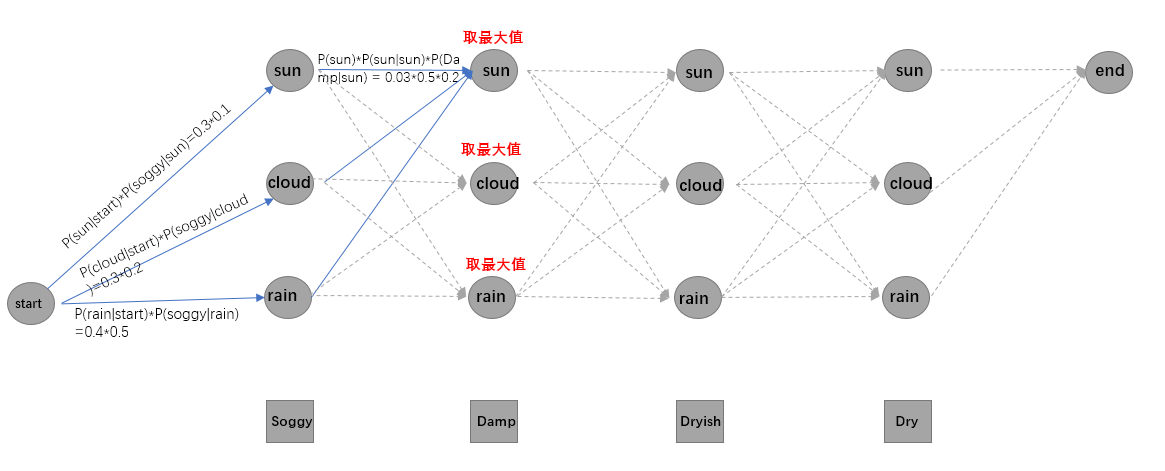
然后最佳路径的计算经过三个部分:初试概率矩阵到第一个字符状态那部分,序列中字符状态转移和发射那部分,最后一个字符状态到end那部分
里边的发射分数和转移分数都使用加法计算是因为 发射矩阵和转移矩阵都经过了log取对数运算
def start_calcute(self,sentence):
'''
通过viterbi算法计算结果
:param sentence: "小明硕士毕业于中国科学院计算所"
:return: "S...E"
'''
zero = -3.14e+100
zero_log = np.log(-3.14e+100)
init_state = self.prob_dict["PiVector_prob"]
trans_prob = self.prob_dict["TransProbMatrix_prob"]
emit_prob = self.prob_dict["EmitProbMartix_prob"]
end_prob = self.prob_dict["EndProbMatrix_prob"] V = [{}] #其中的字典保存 每个时间步上的每个状态对应的概率
path = {} #初始概率
for y in self.state_list:
V[0][y] = init_state[y] + emit_prob[y].get(sentence[0],zero_log)
path[y] = [y] #从第二次到最后一个时间步
for t in range(1,len(sentence)):
V.append({})
newpath = {}
for y in self.state_list: #遍历所有的当前状态
temp_state_prob_list = []
for y0 in self.state_list: #遍历所有的前一次状态
cur_prob = V[t-1][y0]+trans_prob[y0][y]+emit_prob[y].get(sentence[t],zero_log)
temp_state_prob_list.append([cur_prob,y0])
#取最大值,作为当前时间步的概率
prob,state = sorted(temp_state_prob_list,key=lambda x:x[0],reverse=True)[0]
#保存当前时间步,当前状态的概率
V[t][y] = prob
#保存当前的状态到newpath中
newpath[y] = path[state] + [y]
#让path为新建的newpath
path = newpath #输出的最后一个结果只会是S(表示单个字)或者E(表示结束符)
(prob, state) = max([(V[len(sentence)][y]+end_prob[y], y) for y in ["S","E"]])
return (prob, path[state])
实体识别中,或序列标注任务中的维特比Viterbi解码的更多相关文章
- 命名实体识别,使用pyltp提取文本中的地址
首先安装pyltp pytlp项目首页 单例类(第一次调用时加载模型) class Singleton(object): def __new__(cls, *args, **kwargs): if n ...
- 用深度学习做命名实体识别(二):文本标注工具brat
本篇文章,将带你一步步的安装文本标注工具brat. brat是一个文本标注工具,可以标注实体,事件.关系.属性等,只支持在linux下安装,其使用需要webserver,官方给出的教程使用的是Apac ...
- 神经网络结构在命名实体识别(NER)中的应用
神经网络结构在命名实体识别(NER)中的应用 近年来,基于神经网络的深度学习方法在自然语言处理领域已经取得了不少进展.作为NLP领域的基础任务-命名实体识别(Named Entity Recognit ...
- 转:使用RNN解决NLP中序列标注问题的通用优化思路
http://blog.csdn.net/malefactor/article/details/50725480 /* 版权声明:可以任意转载,转载时请标明文章原始出处和作者信息 .*/ author ...
- 【神经网络】神经网络结构在命名实体识别(NER)中的应用
命名实体识别(Named Entity Recognition,NER)就是从一段自然语言文本中找出相关实体,并标注出其位置以及类型,如下图.它是NLP领域中一些复杂任务(例如关系抽取,信息检索等)的 ...
- Oracle中的序列
序列是什么? 序列是用来生成唯一.连续的整数的数据库对象.序列通常用来自动生成主键或唯一键的值.序列可以按升序排列,也可以按照降序排列. 其实Oracle中的序列和MySQL中的自增长差不多一个意思. ...
- 2. 知识图谱-命名实体识别(NER)详解
1. 通俗易懂解释知识图谱(Knowledge Graph) 2. 知识图谱-命名实体识别(NER)详解 3. 哈工大LTP解析 1. 前言 在解了知识图谱的全貌之后,我们现在慢慢的开始深入的学习知识 ...
- NLP(十四)自制序列标注平台
背景介绍 在平时的NLP任务中,我们经常用到命名实体识别(NER),常用的识别实体类型为人名.地名.组织机构名,但是我们往往也会有识别其它实体的需求,比如时间.品牌名等.在利用算法做实体识别的时候 ...
- 『深度应用』NLP命名实体识别(NER)开源实战教程
近几年来,基于神经网络的深度学习方法在计算机视觉.语音识别等领域取得了巨大成功,另外在自然语言处理领域也取得了不少进展.在NLP的关键性基础任务—命名实体识别(Named Entity Recogni ...
随机推荐
- Nature重磅:华裔科学家成功解码脑电波,AI直接从大脑中合成语音
[导读]Nature发表华裔作者论文:通过解码大脑活动提升语音的清晰度,使用深度学习方法直接从大脑信号中产生口语句子,达到150个单词,接近正常人水平. 大脑活动能够解码成语音了. 说话似乎是一项毫不 ...
- Kubernetes(K8s) 安装(使用kubeadm安装Kubernetes集群)
背景: 由于工作发生了一些变动,很长时间没有写博客了. 概述: 这篇文章是为了介绍使用kubeadm安装Kubernetes集群(可以用于生产级别).使用了Centos 7系统. 一.Centos7 ...
- iOS pch
Xcode6 之前会在 Supporting Files 文件夹下自动生成一个"工程名-PrefixHeader.pch"的预编译头文件,pch 头文件的内容能被项目中的其他所有源 ...
- Mysql数据库的基本操作(1)
一.启动数据库 1. 我的电脑(此电脑)--->右键点击[管理]--->[服务和应用程序]--->[服务] 找到MySQL8.0可以选择手动启动或者自动启动. 2.可以直接通过命令行 ...
- 基于 HTML5 WebGL 的楼宇智能化集成系统(一)
前言 随着现代通信技术.计算机技术.控制技术的飞速发展,智能建筑已经成为现代建筑发展的主流.智能建筑是以建筑物为平台,兼备信息设施系统.信息化应用系统.建筑设备管理系统.公共安全系统等.集 ...
- 多源第k短路 (ford + 重新定义编号) / 出发点、终点确定的第k短路 (Spfa+ 启发搜索)
第k短路 Description 一天,HighLights实在是闲的不行,他选取了n个地点,n各地点之间共有m条路径,他想找到这m条路径组成的第k短路,你能帮助他嘛? Input 第一行三个正整数, ...
- CAS单点登录系列之极速入门于实战教程(4.2.7)
@ 目录 一. SSO简介 1.1 单点登录定义 1.2 单点登录角色 1.3 单点登录分类 二. CAS简介 2.1 CAS简单定义 2.2 CAS体系结构 2.3 CAS原理 三.CAS服务端搭建 ...
- java电商项目常见异常
1. java.lang.nullpointerexception 这个异常大家肯定都经常遇到,异常的解释是"程序遇上了空指针",简单地说就是调用了未经初始化的对象或者是不存在的对 ...
- SQL Server 存储过程分页。
create proc proc_Product@page int, -- 页数@row int -- 一页有几行Asdeclare @newpage int set @newpage = (@ ...
- 数据库学习 day1 认识数据库
从SQL的角度而言,数据库是一个以某种有组织的方式储存的数据集合. 我们可以把它比作一个“文件柜”,这个“文件柜”是一个存放数据的物理位置,不管数据是什么,也不管数据是如何组织的. 下面介绍几个术语 ...