Hadoop伪分布式HDFS环境搭建和使用
1.环境要求
Java版本不低于Hadoop要求,并配置环境变量
2.安装
1)在网站hadoop.apache.org下载稳定版本的Hadoop包
2)解压压缩包
检查Hadoop是否可用
hadoop/bin/hadoop version

3)修改配置文件
Hadoop配置以.xml文件形式存在
修改文件hadoop/etc/hadoop/core-site.xml:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/users/hadoop/hadoop/tmp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改文件hadoop/etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/users/hadoop/hadoop/data</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/users/hadoop/hadoop/name</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:8100</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4)namenode格式化
hadoop/bin/hdfs namenode -format

格式化成功如上图所示。
5)开启Namenode和Datanode
hadoop/sbin/start-dfs.sh
执行成功后,输入如下命令查看开启状态
jps

6)web页面查看hdfs服务状况
http://hostname:8100 //8100对应hdfs-site.xml配置文件中的dfs.http.address端口号
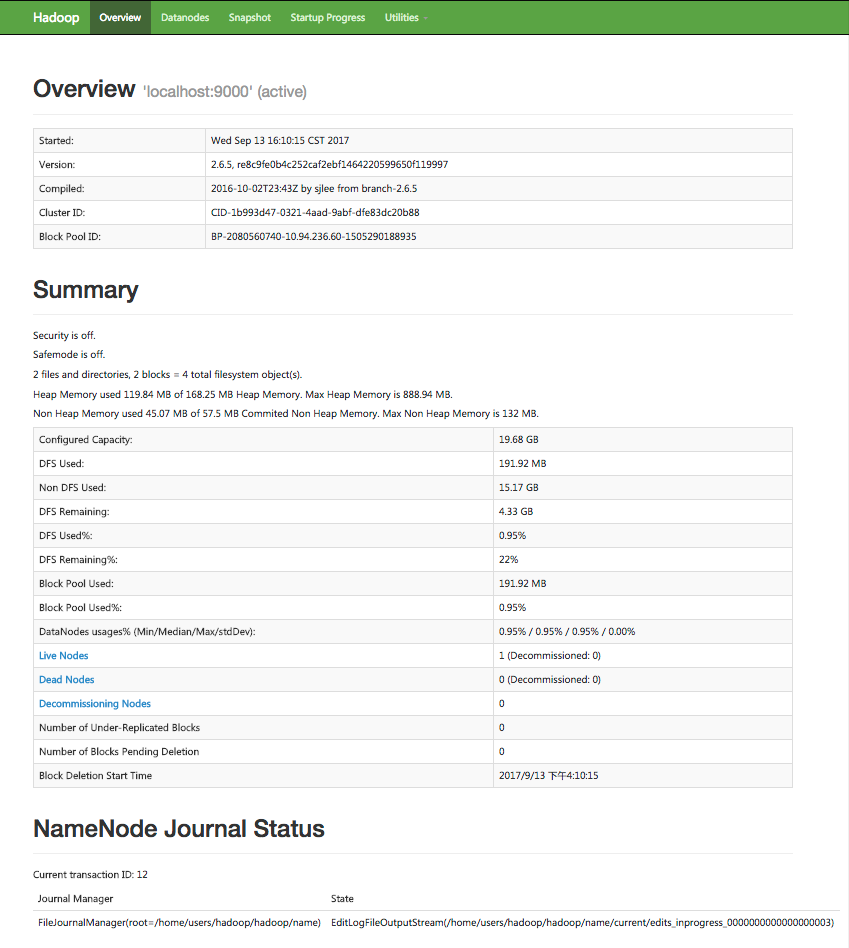
7)安装过程中遇到的问题
<1>namenode格式化的时候遇到JAVA_HOME环境变量问题
解决办法:hadoop/etc/hadoop/hadoop-env.xml文件中有变量的设置,但是不能满足要求,还要修改一下hadoop/libexec/hadoop-config.sh文件中大概160行,新增:
export JAVA_HOME=/home/tools/tools/java/jdk1.6.0_20
<2>datanode无法启动
出现该问题的原因:在第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令(hdfs namenode -format),这时namenode的clusterID会重新生成,而datanode的clusterID 保持不变。
解决办法:将hadoop/name/current下的VERSION中的clusterID复制到hadoop/data/current下的VERSION中,覆盖掉原来的clusterID,让两个保持一致然后重启,启动后执行jps,查看进程
3.HDFS的使用
HDFS的命令执行格式:hadoop fs -cmd,其中cmd是类shell的命令
hadoop fs -ls / //查看hdfs根目录的文件树
hadoop fs -mkdir /test //创建test文件夹
hadoop fs -cp 文件 文件 //拷贝文件
注:以上命令可以通过添加环境变量来简化
Hadoop伪分布式HDFS环境搭建和使用的更多相关文章
- Win7下单机版的伪分布式solrCloud环境搭建Tomcat+solr+zookeeper【转】
Win7下单机版的伪分布式solrCloud环境搭建Tomcat+solr+zookeeper 1.软件工具箱 在本文的实践中,需要用到以下的软件: Tomcat-7.0.62+solr-5.0.0+ ...
- Hadoop-01 搭建hadoop伪分布式运行环境
Linux中配置Hadoop运行环境 程序清单 VMware Workstation 11.0.0 build-2305329 centos6.5 64bit jdk-7u80-linux-x64.r ...
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- Hadoop2.0伪分布式平台环境搭建
一.搭建环境的前提条件 环境:ubuntu-16.04 hadoop-2.6.0 jdk1.8.0_161.这里的环境不一定需要和我一样,基本版本差不多都ok的,所需安装包和压缩包自行下载即可. 因 ...
- 基于Hadoop伪分布式集群搭建Spark
一.前置安装 1)JDK 2)Hadoop伪分布式集群 二.Scala安装 1)解压Scala安装包 2)环境变量 SCALA_HOME = C:\ProgramData\scala-2.10.6 P ...
- Hadoop学习笔记(一):ubuntu虚拟机下的hadoop伪分布式集群搭建
hadoop百度百科:https://baike.baidu.com/item/Hadoop/3526507?fr=aladdin hadoop官网:http://hadoop.apache.org/ ...
- hadoop_spark伪分布式实验环境搭建和运行实例详细教程
hadoop+spark伪分布式环境搭建 安装须知 单机模式(standalone): 该模式是Hadoop的默认模式.这种模式在一台单机上运行,没有分布式文件系统,而是直接读写本地操作系统的文件系统 ...
- hadoop2.5.2学习及实践笔记(一)—— 伪分布式学习环境搭建
软件 工具:vmware 10 系统:centOS 6.5 64位 Apache Hadoop: 2.5.2 64位 Jdk: 1.7.0_75 64位 安装规划 /opt/softwares ...
- Hadoop伪分布式集群搭建
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 1.下载Hadoop压缩包 wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop- ...
随机推荐
- iview checkbox demo(文档改写)
<template> <div class="content"> <div style="border-bottom: 1px solid ...
- selenium浏览器内核监测处理
一.代码 from selenium.webdriver import Chrome from selenium.webdriver import ChromeOptions option = Chr ...
- Codeforce 370A Rook, Bishop and King 数学规律
这个题目挺有意思的,给定 起终点,要你求车,象,王分别最少要走多少步 车横竖都能走,而且每步任意走几格,所以它是最容易处理的,如果在同行或者同列,就是1,否则就是2 象要找下规律,象任意对角线都能走, ...
- spring学习之依赖注入DI与控制反转IOC
一 Ioc基础 1.什么是Ioc? Ioc(Inversion of Control)既控制反转,Ioc不是一种技术,而是一种思想,在Java开发中意味着将设计好的对象交给容器来进行控制,并不是像传统 ...
- LeetCode Input Initial Code
说明 LeetCode提供的样本输入,显示上是数组Array,而后台的实际测试用例则是树TreeNode,链表ListNode等. 如果你是在页面手撸代码直接提交的,那没什么影响. 如果你是在本地ID ...
- ssh登录脚本
#!/usr/bin/expect set timeout 100 set passwd "your password" spawn shell expect "key& ...
- mysql超大sql导入(10G)
mysql 大数据库文件上传(10G) phpstudy2017 环境 mysql 5.5.53 php 5.5.45 更改php.ini memory_limit 为 2048M php.i ...
- iOS筛选菜单、分段选择器、导航栏、悬浮窗、转场动画、启动视频等源码
iOS精选源码 APP启动视频 自定义按钮,图片可调整图文间距SPButton 一款定制性极高的轮播图,可自定义轮播图Item的样式(或只... iOS 筛选菜单 分段选择器 仿微信导航栏的实现,让你 ...
- 吴裕雄--天生自然 PYTHON3开发学习:SMTP发送邮件
import smtplib smtpObj = smtplib.SMTP( [host [, port [, local_hostname]]] ) SMTP.sendmail(from_addr, ...
- 01 语言基础+高级:1-7 异常与多线程_day07 【线程池、Lambda表达式】
day07[线程池.Lambda表达式] 主要内容 等待与唤醒案例 线程池 Lambda表达式 教学目标 -[ ] 能够理解线程通信概念-[ ] 能够理解等待唤醒机制-[ ] 能够描述Java中线程池 ...