geotrellis使用(三十三)关于Geotrellis读取Geotiff的两个细节
前言
在上两篇文章中我介绍了如何直接将Geotiff(一个或者多个)发布为TMS服务。这中间其实我遇到了一个问题,并且这个问题伴随Geotrellis的几乎所有使用案例,下面我详细讲述。
一、问题描述
无论在将Tiff文件使用Geotrellis导入Accumulo中还是直接将其发布为TMS服务,其实这中间都存在一个问题:当多个Tiff文件存在重叠部分的时候如何接边、去重叠以及在边界处的瓦片如何取出各Tiff文件中涉及到的数据,即保持瓦片显示效果的完整性。
这个问题可以说是一个问题也可以说是两个问题。当我们采用事先导入Accumulo中的方案的时候,这个问题不存在(下面会介绍不存在的原因),这也是我一直没有理会此问题的原因,而当我们直接加载Tiff文件为TMS服务的时候这个问题便出现了,当某一个瓦片对应的是两个或者多个Tiff文件的时候,无论选用哪一个文件都会导致最终的瓦片数据不全。接下来我们就来解决这个问题。
二、原理分析及最终效果
要解决这个问题,首先要搞明白Geotrellis是如何读取Tiff文件的。
Geotrellis使用HadoopGeoTiffRDD类将Tiff文件直接读取为RDD,主要方法如下:
def apply[I, K, V](path: Path, uriToKey: (URI, I) => K, options: Options)(implicit sc: SparkContext, rr: RasterReader[Options, (I, V)]): RDD[(K, V)] = {
val conf = configuration(path, options)
options.maxTileSize match {
case Some(tileSize) =>
val pathsAndDimensions: RDD[(Path, (Int, Int))] =
sc.newAPIHadoopRDD(
conf,
classOf[TiffTagsInputFormat],
classOf[Path],
classOf[TiffTags]
).mapValues { tiffTags => (tiffTags.cols, tiffTags.rows) }
apply[I, K, V](pathsAndDimensions, uriToKey, options)
case None =>
sc.newAPIHadoopRDD(
conf,
classOf[BytesFileInputFormat],
classOf[Path],
classOf[Array[Byte]]
).mapPartitions(
_.map { case (p, bytes) =>
val (k, v) = rr.readFully(ByteBuffer.wrap(bytes), options)
uriToKey(p.toUri, k) -> v
},
preservesPartitioning = true
)
}
}
其中path为传入的路径,所以configuration方法是关键,其定义如下:
private def configuration(path: Path, options: Options)(implicit sc: SparkContext): Configuration = {
val conf = sc.hadoopConfiguration.withInputDirectory(path, options.tiffExtensions)
conf
}
withInputDirectory方法定义如下:
def withInputDirectory(path: Path, extensions: Seq[String]): Configuration = {
val searchPath = path.toString match {
case p if extensions.exists(p.endsWith) => path
case p =>
val extensionsStr = extensions.mkString("{", ",", "}")
new Path(s"$p/*$extensionsStr")
}
withInputDirectory(searchPath)
}
def withInputDirectory(path: Path): Configuration = {
val allFiles = HdfsUtils.listFiles(path, self)
if(allFiles.isEmpty) {
sys.error(s"$path contains no files.")
}
HdfsUtils.putFilesInConf(allFiles.mkString(","), self)
}
看完这两个方法我们是不是就豁然开朗了。extensions是一个Tiff文件扩展名的集合。当此文件是tiff文件的时候就直接读取他,如果不是的时候就以他为文件夹读取他下面的所有可能tiff文件,所以我上面说事先导入Accumulo时该问题不存在,因为那时我传入的正是文件夹,系统直接帮我达到了想要的结果。
所以我们就可以明白,如果你想让Geotrellis处理接边、重叠等问题可以直接传入包含所有要处理的Tiff数据的文件夹,这样系统就会自动处理(具体的接边、去重叠操作在rdd的union方法中,由UnionRDD类具体完成)。
所以我们的Tiff文件直接发布为TMS也可以才用同样的处理方式,只需要将文件夹传入即可,这样在涉及到重叠、接边区域的瓦片还能保证数据的完整性。但是这样又出现了另一个问题,如果一次读入所有文件势必会造成处理速度很慢,那么我们为什么不能只取出当前瓦片涉及到的文件呢,如果只涉及一个Tiff就取一个,如果涉及到多个Tiff就取多个。这样既不会造成数据缺失也不会造成读取缓慢。先来看一下最终效果。
我下载了14幅连续的srtm数据,采用上述方式发布的TMS最终结果如下图:
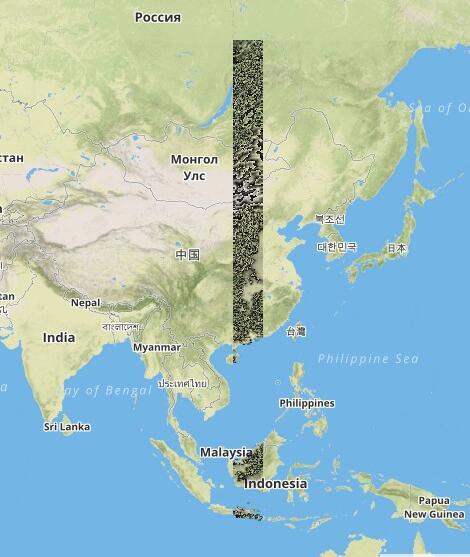
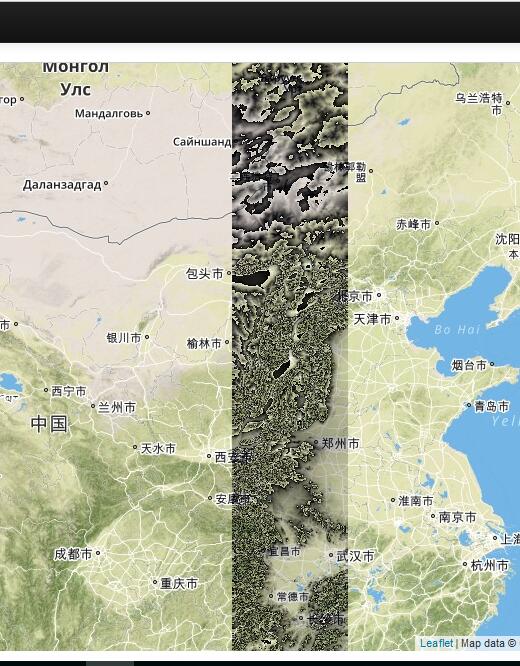
从中可以看出拼接的效果非常好,如果是只读取单幅Tiff的情况必然两幅之间会存在空白,采用这种逐一读取的方式,不仅结果完美,效率也较高。下面来介绍实现方案。
三、实现方案
整体实现方案如下:
- 判断并取出与请求的瓦片有交集的Tiff文件
- 将这些Tiff文件作为整体读取rdd并发布TMS
3.1 判断并取出与请求的瓦片有交集的Tiff文件
上一篇文章中已经大致介绍了此块内容,在这里再简要介绍一下更新后的版本,代码如下:
val files = HdfsUtils.listFiles(new Path(self.getHdfsUri), sc.hadoopConfiguration)
files.filter { s =>
if (HadoopGeoTiffRDD.Options.DEFAULT.tiffExtensions.exists(s.toString.endsWith)) {
val tiffExtent = getExtent(s)
extent.intersects(tiffExtent)
}
else
false
}
def getExtent(path: Path) = {
val rdd = HadoopGeoTiffRDD.spatialMultiband(path)
rdd
.map { case (key, grid) =>
val ProjectedExtent(extent, crs) = key.getComponent[ProjectedExtent]
// Bounds are return to set the non-spatial dimensions of the KeyBounds;
// the spatial KeyBounds are set outside this call.
val boundsKey = key.translate(SpatialKey(0,0))
val cellSize = CellSize(extent, grid.cols, grid.rows)
HashMap(crs -> RasterCollection(crs, grid.cellType, cellSize, extent, KeyBounds(boundsKey, boundsKey), 1))
}
.reduce { (m1, m2) => m1.merged(m2){ case ((k,v1), (_,v2)) => (k,v1 combine v2) } }
.values.toSeq.head.extent
}
其中sc为SparkContext对象,hdfsPath为HDFS中Tiff文件夹路径,files即为此文件下面所有文件,getExtent函数获取传入Tiff文件的空间范围。filter操作过滤掉非Tiff文件以及与extent(瓦片的空间范围)不相交的Tiff文件。这样就可以得到所有与此瓦片有关的Tiff文件。
3.2 将这些Tiff文件作为整体读取rdd并发布TMS
此步又有两种思路(原谅我最近中国哲学简史看多了,总想往高大上的哲学上套一套):
- 将这些Tiff文件作为整体提交Geotrellis得到最终结果
- 读取每一幅tiff文件然后手动union
两种方案各有利弊,第一种需要自己写读取多个Tiff文件的方案,第二种需要我们手动union,在这里我都介绍一下。
3.2.1 读取多个Tiff文件
解决思路就是将多个Tiff文件提交到上述的conf中,这样系统就会自动帮我们读取。简单的说就是改写上述configuration函数。代码如下:
private def configuration(paths: Array[Path])(implicit sc: SparkContext): Configuration = {
val union = paths.mkString(",")
HdfsUtils.putFilesInConf(union, sc.hadoopConfiguration)
}
其中paths为上一步获取到的与瓦片有关的Tiff文件集合。只需要重写上面的读取Tiff的apply方法,将其中的configuration换成此函数即可。
3.2.2 逐一读取,手动union
思路清晰明了,代码如下:
paths.map(s => HadoopGeoTiffRDD.spatial(s))
.reduce((a, b) => a union b)
很简单的代码,先对Tiff文件集合进行map操作读取所有rdd,然后执行reduce操作,reduce执行的函数为union,即将两个rdd联合,意味着拼接和去重叠。这样也可解决问题。
四、总结
本文简单讲述了使用Geotrellis处理Tiff文件时的两个细节,通过这两个细节能够让我们对Geotreliis的核心更加了解,也能够使我们更加便捷和灵活的处理实际中碰到的关于数据方面的问题。
Geotrellis系列文章链接地址http://www.cnblogs.com/shoufengwei/p/5619419.html
geotrellis使用(三十三)关于Geotrellis读取Geotiff的两个细节的更多相关文章
- geotrellis使用(四)geotrellis数据处理部分细节
前面写了几篇博客介绍了Geotrellis的简单使用,具体链接在文后,今天我主要介绍一下Geotrellis在数据处理的过程中需要注意的细节,或者一些简单的经验技巧以供参考. 一.直接操作本地Geot ...
- NeHe OpenGL教程 第三十三课:TGA文件
转自[翻译]NeHe OpenGL 教程 前言 声明,此 NeHe OpenGL教程系列文章由51博客yarin翻译(2010-08-19),本博客为转载并稍加整理与修改.对NeHe的OpenGL管线 ...
- JAVA之旅(三十三)——TCP传输,互相(伤害)传输,复制文件,上传图片,多并发上传,多并发登录
JAVA之旅(三十三)--TCP传输,互相(伤害)传输,复制文件,上传图片,多并发上传,多并发登录 我们继续网络编程 一.TCP 说完UDP,我们就来说下我们应该重点掌握的TCP了 TCP传输 Soc ...
- FreeSql (三十三)CodeFirst 类型映射
前面有介绍过几篇 CodeFirst 内容文章,有 <(二)自动迁移实体>(https://www.cnblogs.com/FreeSql/p/11531301.html) <(三) ...
- COJ967 WZJ的数据结构(负三十三)
WZJ的数据结构(负三十三) 难度级别:C: 运行时间限制:7000ms: 运行空间限制:262144KB: 代码长度限制:2000000B 试题描述 请你设计一个数据结构,完成以下功能: 给定一个大 ...
- COJ 0967 WZJ的数据结构(负三十三)
WZJ的数据结构(负三十三) 难度级别:E: 运行时间限制:7000ms: 运行空间限制:262144KB: 代码长度限制:2000000B 试题描述 请你设计一个数据结构,完成以下功能: 给定一个大 ...
- 三十三、Java图形化界面设计——布局管理器之null布局(空布局)
摘自http://blog.csdn.net/liujun13579/article/details/7774267 三十三.Java图形化界面设计--布局管理器之null布局(空布局) 一般容器都有 ...
- Gradle 1.12用户指南翻译——第三十三章. PMD 插件
本文由CSDN博客万一博主翻译,其他章节的翻译请参见: http://blog.csdn.net/column/details/gradle-translation.html 翻译项目请关注Githu ...
- “全栈2019”Java多线程第三十三章:await与signal/signalAll
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java多 ...
随机推荐
- 【Centos】yum 安装mariaDB
[dream361@za ~]$ sudo yum search mariadb #查找需安装的包 mariadb-libs.x86_64 : The shared libraries require ...
- centos下搭建多项目svn服务器
svn是多人协作开发中的利器,是一个开放源代码的版本控制系统. 相比与git,他的操作更加简单,windows下有优秀的图形界面,并且支持的文件类型比较多. 本文讲述如何在linux下搭建一个svn服 ...
- pandas数据分析(数据结构)
本文主要从以下两个方向对pandas的数据结构进行展开,分别为Series和DataFrame(对应的分别是系列与numpy中的一维数组和二维数组) 1.首先从Series讲起,主要介绍Series的 ...
- SpringMVC获取页面数据乱码的解决get/post
一.post请求方式的乱码 在web.xml中加入: <filter> <filter-name>CharacterEncodingFilter</filter-name ...
- .net core 2.0 登陆权限验证
首先在Startup的ConfigureServices方法添加一段权限代码 services.AddAuthentication(x=> { x.DefaultAuthenticateSche ...
- Selenium 学习笔记(一)
selenium 学习整理 初学者,如果有不当得地方请指出,非常感谢. 准备事项: 1. Python 安装包 安装Python,并勾选添加环境变量. 安装完成后,打开dos窗口,输入python,看 ...
- web安全普及:通俗易懂,如何让网站变得更安全?以实例来讲述网站入侵原理及防护。
本篇以我自己的网站[http://www.1996v.com]为例来通俗易懂的讲述如何防止网站被入侵,如何让网站更安全. 要想足够安全,首先得知道其中的道理. 本文例子通俗易懂,从"破解网站 ...
- windows平台下node,npm,gulp配置
参考文献:http://blog.csdn.net/yuanyuan214365/article/details/53749583 1.安装nodejs:nodejs nodejs安装路径随意 nod ...
- HDMI转EDP芯片NCS8803简介
NCS8803 HDMI-to-eDP w/ Scaler Features --Embedded-DisplayPort (eDP) Output 1/2/4-lane eDP @ 1.62/2.7 ...
- django全文检索
-------------------linux下配置操作1.在虚拟环境中依次安装包 1.pip install django-haystack haystack:django的一个包,可以方便地对m ...